Command Palette
Search for a command to run...
NVIDIA Huang Renxun은 H100보다 추론 능력이 30배 높고 에너지 소모가 25배 낮은 GB200을 출시하여 AI4S 기능을 마이크로서비스로 전환했습니다.

"AI의 아이폰 시대가 도래했습니다." 황런쉰이 NVIDIA GTC 2023에서 한 중요한 말은 아직도 우리의 기억에 생생합니다. 올해는 AI의 발전으로 그의 말이 사실이라는 게 증명됐습니다.
수년에 걸쳐 AI 개발이 가속화되고 엔비디아의 기술과 생태계가 흔들리지 않게 되면서 GTC는 초기 기술 컨퍼런스에서 전체 산업 체인이 주목하는 AI 산업 행사로 점차 업그레이드되었습니다. 엔비디아가 보여준 '근력'은 산업 혁신의 중요한 촉매제가 될 수 있다.
올해의 2024 GTC AI 컨퍼런스가 예정대로 진행됩니다. 3월 18일부터 3월 21일까지 900회 이상의 회의와 20회 이상의 기술 강의가 진행될 예정입니다. 물론, 가장 눈길을 끄는 연설은 여전히 "Leather Yellow" 연설이었습니다. 이전에 발표된 일정에 따르면, 황런쉰의 연설은 베이징 시간으로 3월 19일 오전 4시에 시작되어 오전 6시까지 진행됩니다. 방금 황런쉰은 2시간 동안 진행된 공유 세션에서 일련의 "AI 핵폭탄"을 투하했습니다.
* 새로운 세대 GPU 플랫폼, 블랙웰
* 블랙웰 기반 최초의 칩, GB200 Grace Blackwell
* 차세대 AI 슈퍼컴퓨터 DGX SuperPOD
* AI 슈퍼컴퓨팅 플랫폼 DGX B200
* 차세대 네트워크 스위치 X800 시리즈
* 양자 컴퓨팅 클라우드 서비스
* 기후 디지털 트윈 클라우드 플랫폼인 Earth-2
* 생성형 AI 마이크로서비스
* 5개의 새로운 Omniverse Cloud API
* DRIVE Thor는 생성적 AI 애플리케이션을 위해 설계된 차량용 컴퓨팅 플랫폼입니다.
* BioNeMo 기본 모델
라이브 리플레이 링크:
https://www.bilibili.com/video/BV1Z6421c7V6/?spm_id_from=333.337.search-card.all.click
cuLitho의 실제 활용
작년 GTC 컨퍼런스에서 NVIDIA는 계산 리소그래피 라이브러리인 cuLitho를 출시하면서, 이를 통해 계산 리소그래피 속도가 40배 이상 빨라질 수 있다고 주장했습니다. 오늘 황런쉰은 TSMC와 Synopsys가 NVIDIA cuLipo를 자사의 소프트웨어, 제조 공정 및 시스템에 통합하여 칩 제조 속도를 높였다고 소개했습니다.두 회사는 공유 워크플로에서 cuLitho를 테스트할 때 곡선형 흐름의 경우 속도를 45배 높이고, 보다 전통적인 맨해튼 스타일 흐름의 경우 효율성을 약 60배 향상시키는 성과를 공동으로 달성했습니다.
또한 NVIDIA는 cuLitho 플랫폼의 가치를 더욱 높이기 위해 생성적 AI를 적용하는 알고리즘을 개발했습니다. 구체적으로, cuLitho를 기반으로 한 생산 공정 효율성 향상을 바탕으로,이 생성 AI 알고리즘은 2배 더 빠릅니다.
생성적 AI를 적용하면 빛의 회절을 고려하여 거의 완벽한 역마스크 솔루션을 만들 수 있고, 이후 기존의 물리적 방법을 통해 최종 마스크를 도출하여 궁극적으로 전체 광학 근접 보정(OPC) 프로세스의 속도를 2배로 높일 수 있다고 합니다.
1조 매개변수 규모의 생성 AI를 위한 Blackwell 플랫폼

cuLitho 응용 프로그램에 대한 위의 소개는 계산 리소그래피 기술의 개발 전망을 보여주고, 어느 정도 NVIDIA AI 칩의 세대 업그레이드에 대한 기본적인 보장을 제공하는 "전채 요리"와 같습니다.
이제 메인 코스가 시작됩니다. 2년마다 GPU 아키텍처를 업데이트한다는 NVIDIA의 전통에 따라, Huang이 선보인 첫 번째 블록버스터 제품은 새로운 대형 GPU인 Blackwell 플랫폼입니다. 그는 말했다,호퍼는 훌륭하지만, 더 강력한 GPU가 필요합니다.
블랙웰 건축물은 미국 과학 아카데미에 선출된 최초의 아프리카계 미국인인 데이비드 해럴드 블랙웰을 기리기 위해 명명되었습니다.

성능 측면에서 Blackwell은 6가지 혁신적인 기술을 보유하고 있습니다.
* 세계에서 가장 강력한 칩:블랙웰 아키텍처 GPU는 맞춤형 4NP TSMC 공정을 사용하여 제조되었으며 2,080억 개의 트랜지스터를 포함합니다. 10TB/초의 칩 간 링크를 통해 두 개의 익스트림 GPU 칩을 하나의 통합 GPU로 연결합니다. 2세대 트랜스포머 엔진: Blackwell은 새로운 4비트 부동 소수점 AI 추론 기능을 기반으로 두 배의 컴퓨팅 및 모델 크기를 지원합니다.
* 5세대 NVLink:NVIDIA NVLink의 최신 버전은 GPU당 1.8TB/s의 획기적인 양방향 처리량을 제공하여 최대 576개 GPU 간의 원활한 고속 통신을 보장하여 가장 복잡한 LLM을 구현합니다.
* RAS 엔진:Blackwell 기반 GPU에는 안정성, 가용성, 서비스 용이성을 위한 전용 엔진이 포함되어 있습니다. 또한, Blackwell 아키텍처는 AI 기반 예방적 유지 관리를 사용하여 진단을 실행하고 안정성 문제를 예측하는 칩 수준 기능을 추가합니다. 이를 통해 시스템 가동 시간이 극대화되고, 대규모 AI 배포의 복원력이 향상되며, 몇 주 또는 몇 달 동안 중단 없이 실행될 수 있으며 운영 비용이 절감됩니다.
* 보안 AI:성능 저하 없이 AI 모델과 고객 데이터를 보호하고, 개인 정보 보호에 민감한 의료 및 금융 서비스 산업에 필수적인 새로운 기본 인터페이스 암호화 프로토콜을 지원합니다.
* 감압 엔진:전용 압축 해제 엔진은 최신 형식을 지원하고 데이터베이스 쿼리를 가속화하여 데이터 분석 및 데이터 과학에 최고의 성능을 제공합니다.
현재 AWS, Google, Meta, Microsoft, OpenAI, Tesla 등의 회사가 Blackwell 플랫폼을 "예약"하는 데 앞장서고 있습니다.
GB200 그레이스 블랙웰

블랙웰을 기반으로 한 최초의 칩은 GB200 Grace Blackwell Superchip으로 명명되었습니다.두 개의 NVIDIA B200 Tensor Core GPU를 초저전력 900GB/s NVLink 칩 간 상호연결을 통해 NVIDIA Grace CPU에 연결합니다.
이 중 B200 GPU는 기존 H100보다 트랜지스터 수가 두 배 이상 많아 2,080억 개에 달합니다. 단일 GPU를 통해 20페타플롭의 고성능 컴퓨팅 성능을 제공할 수 있는 반면, 단일 H100은 최대 4페타플롭의 AI 컴퓨팅 성능만 제공할 수 있습니다. 또한 B200 GPU에는 192GB의 HBM3e 메모리가 탑재되어 최대 8TB/s의 대역폭을 제공합니다.

GB200은 NVIDIA GB200 NVL72의 핵심 구성 요소입니다.NVL72는 다중 노드, 액체 냉각, 랙 장착 시스템입니다.가장 컴퓨팅 집약적인 작업에 이상적인 이 제품은 5세대 NVLink로 상호 연결된 72개의 Blackwell GPU와 36개의 Grace CPU를 포함한 36개의 Grace Blackwell 슈퍼칩을 결합합니다.
또한 GB200 NVL72에는 NVIDIA BlueField®-3 데이터 처리 장치가 포함되어 있어 클라우드 네트워크 가속, 구성 가능한 스토리지, 제로 트러스트 보안, 하이퍼스케일 AI 클라우드의 GPU 컴퓨팅 탄력성을 구현합니다. GB200 NVL72는 동일한 수의 GPU를 탑재한 NVIDIA H100 Tensor Core GPU보다 최대 25배 낮은 비용과 에너지 소비로 LLM 추론 워크로드에서 최대 30배 더 뛰어난 성능을 제공합니다.
차세대 AI 슈퍼컴퓨터 DGX SuperPOD
NVIDIA DGX SuperPOD는 새로운 액체 냉각 랙 장착 아키텍처를 사용하며 NVIDIA DGX GB200 시스템을 기반으로 제작되었습니다.FP4 정밀도로 11.5엑사플롭스의 AI 슈퍼컴퓨팅 성능과 240TB의 고속 메모리를 제공합니다.추가 랙을 사용하면 더 높은 성능으로 확장할 수 있습니다. DGX SuperPOD는 하드웨어와 소프트웨어 전반에 걸쳐 수천 개의 데이터 포인트를 지속적으로 모니터링하여 가동 중지 및 비효율성의 근원을 예측하고 차단하는 지능형 예측 관리 기능을 갖추고 있어 시간, 에너지 및 컴퓨팅 비용을 절감합니다.
DGX GB200 시스템은 36개의 NVIDIA Grace CPU와 72개의 NVIDIA Blackwell GPU를 포함한 36개의 NVIDIA GB200 슈퍼 칩을 탑재하고 있으며, 5세대 NVLink를 통해 슈퍼컴퓨터에 연결됩니다.
각 DGX SuperPOD는 8개 이상의 DGX GB200을 탑재할 수 있으며, NVIDIA Quantum InfiniBand를 통해 연결된 수만 개의 GB200 슈퍼 칩으로 확장할 수 있습니다. 예를 들어, 사용자는 NVLink 상호연결을 기반으로 576개의 Blackwell GPU를 8개의 DGX GB200에 연결할 수 있습니다.
AI 슈퍼컴퓨팅 플랫폼 DGX B200
DGX B200은 공랭식의 전통적인 랙 마운트 DGX 디자인을 사용하여 AI 모델 학습, 미세 조정 및 추론을 위한 컴퓨팅 플랫폼입니다. DGX B200 시스템은 새로운 Blackwell 아키텍처에서 FP4 정밀도를 달성하여 최대 144페타플롭의 AI 컴퓨팅 성능, 1.4TB의 대용량 GPU 메모리, 64TB/s의 메모리 대역폭을 제공합니다.이전 세대에 비해 1조 개의 매개변수가 있는 모델의 실시간 추론 속도가 15배 빨라졌습니다.
새로운 Blackwell 아키텍처를 기반으로 한 DGX B200에는 8개의 Blackwell GPU와 2개의 5세대 Intel Xeon 프로세서가 장착되어 있습니다. 사용자는 DGX B200 시스템을 사용하여 DGX SuperPOD를 구축할 수도 있습니다. 네트워크 연결을 위해 DGX B200에는 NVIDIA ConnectX™-7 네트워크 카드 8개와 BlueField-3 DPU 2개가 장착되어 초당 최대 400기가비트의 대역폭을 제공합니다.
차세대 네트워크 스위치 시리즈 - X800
새로운 세대의 네트워크 스위치 X800 시리즈는 대규모 인공지능을 위해 설계되어 컴퓨팅 및 AI 워크로드의 네트워크 성능 한계를 뛰어넘는 것으로 알려졌습니다.
이 플랫폼에는 NVIDIA Quantum Q3400 스위치와 NVIDIA ConnectX@-8 슈퍼 네트워크 카드가 포함되어 업계 최고 수준인 800Gb/s의 엔드투엔드 처리량을 달성합니다.이전 세대 제품에 비해 대역폭 용량이 5배 증가했습니다.동시에 NVIDIA의 SHARPv4(Scalable Hierarchical Aggregation and Reduction Protocol)를 채택하여 최대 14.4Tflops의 네트워크 내 컴퓨팅 성능을 달성했습니다.이전 세대에 비해 성능이 최대 9배 향상되었습니다.
양자 컴퓨팅 클라우드 서비스, 과학 연구 가속화
NVIDIA의 양자 컴퓨팅 클라우드 서비스는 해당 회사의 오픈 소스 CUDA-Q 양자 컴퓨팅 플랫폼을 기반으로 합니다.현재 업계에서 양자 처리 장치(QPU)를 배치한 회사의 4분의 3이 이 플랫폼을 사용하고 있습니다. 엔비디아의 양자 컴퓨팅 클라우드 서비스를 이용하면 강력한 시뮬레이터와 양자 하이브리드 프로그래밍 도구를 포함하여 사용자가 클라우드에서 처음으로 새로운 양자 알고리즘과 애플리케이션을 구축하고 테스트할 수 있습니다.
양자 컴퓨팅 클라우드는 과학적 발견을 가속화하는 강력한 기능과 타사 소프트웨어 통합을 갖추고 있습니다. 여기에는 다음이 포함됩니다.
* 토론토 대학과 협력하여 개발한 생성적 양자 고유값 솔버는 대규모 언어 모델을 사용하여 양자 컴퓨터가 분자의 기본 상태 에너지를 더 빠르게 찾을 수 있도록 합니다.
* Classiq와 CUDA-Q의 통합을 통해 양자 연구자들은 대규모의 복잡한 양자 프로그램을 생성하고 양자 회로를 심층적으로 분석하여 실행할 수 있습니다.
* QC Ware Promethium은 분자 시뮬레이션과 같은 복잡한 양자 화학 문제를 해결할 수 있습니다.
기후 디지털 트윈 클라우드 플랫폼 Earth-2 출시
Earth-2는 대규모로 날씨와 기후를 시뮬레이션하고 시각화하여 극한 날씨를 예측하는 것을 목표로 합니다. Earth-2 API는 AI 모델을 제공하고 CorrDiff 모델을 사용합니다.
CorrDiff는 NVIDIA가 출시한 새로운 생성 AI 모델입니다. SOTA 확산 모델을 사용합니다.그 결과로 나온 이미지는 기존 수치 모델보다 해상도가 12.5배 높고, 속도는 1,000배 빠르며, 에너지 효율은 3,000배 더 좋습니다.이는 낮은 해상도의 예측으로 인한 부정확성을 극복하고 의사 결정에 중요한 지표를 통합합니다.

CorrDiff는 초고해상도를 제공하고, 새로운 중요한 지표를 합성하고, 고해상도 데이터세트에서 지역적 세부 날씨의 물리적 특성을 학습하는 최초의 생성형 AI 모델입니다.
약물 개발, 의료 기술 반복 및 디지털 건강을 촉진하기 위한 생성적 AI 마이크로서비스 출시
새로운 NVIDIA 헬스케어 마이크로서비스 제품군에는 최적화된 NVIDIA NIM™ AI 모델과 업계 표준 API 워크플로가 포함되어 있어 클라우드 기반 애플리케이션을 만들고 배포하기 위한 빌딩 블록 역할을 합니다. 이러한 마이크로서비스에는 고급 이미징, 자연어 및 음성 인식, 디지털 생물학 생성, 예측 및 시뮬레이션과 같은 기능이 포함됩니다.
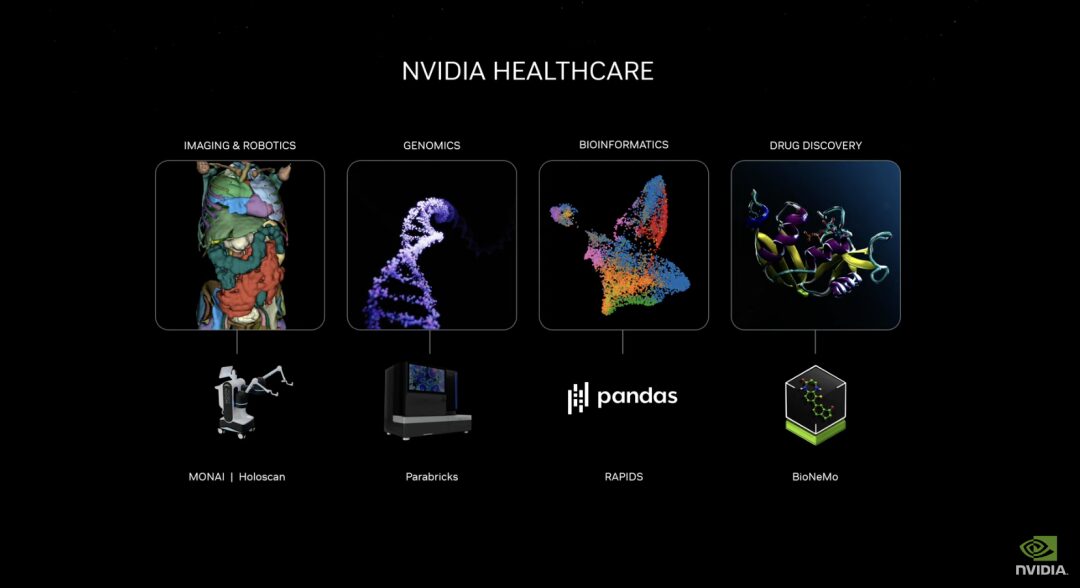
또한 Parabricks®, MONAI, NeMo™, Riva 및 Metropolis를 포함한 NVIDIA 가속 소프트웨어 개발 키트와 관련 도구는 이제 NVIDIA CUDA-X™ 마이크로서비스를 통해 액세스할 수 있습니다.
추론 마이크로서비스
기업이 자체 플랫폼에서 맞춤형 애플리케이션을 만들고 배포하는 동시에 지적 재산권을 유지하는 데 사용할 수 있는 수십 개의 엔터프라이즈급 생성적 AI 마이크로서비스를 출시합니다.
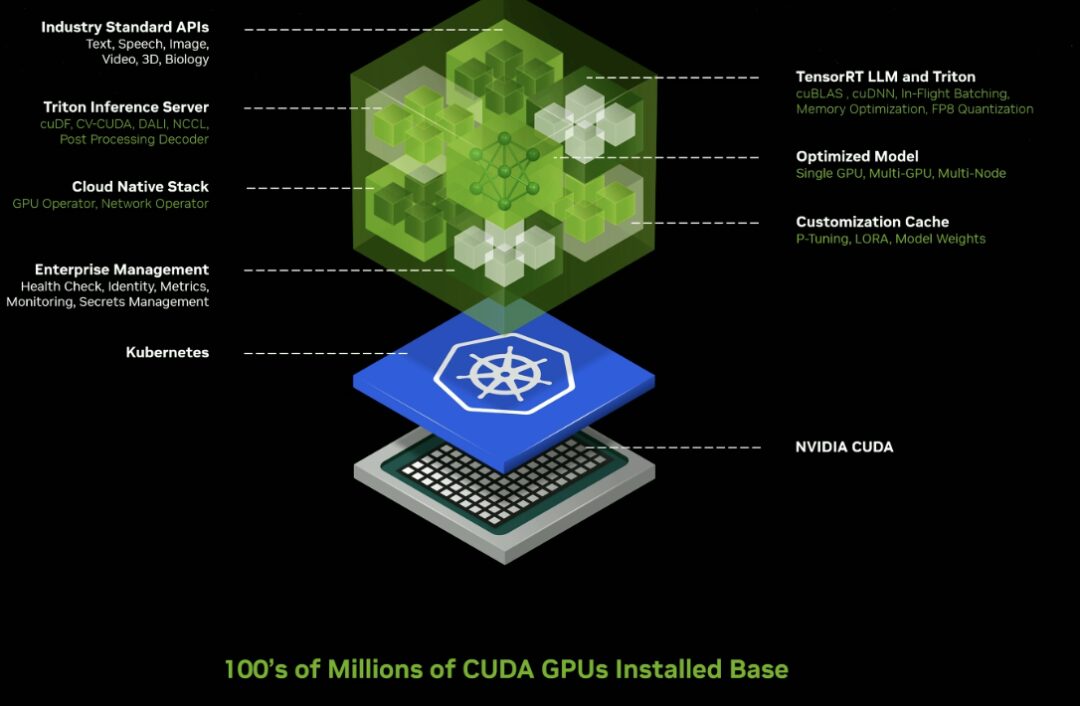
클라우드, 데이터 센터, 워크스테이션, PC에서 수억 개의 CUDA 지원 GPU에서 실행되도록 최적화된 사전 학습된 AI 모델을 위한 새로운 GPU 가속 NVIDIA NIM 마이크로서비스 및 클라우드 엔드포인트입니다.
기업은 마이크로서비스를 사용하여 데이터 처리, LLM 사용자 정의, 추론, 검색 향상 생성 및 보호를 가속화할 수 있습니다.
Cadence, CrowdStrike, SAP, ServiceNow 등 선도적인 애플리케이션 플랫폼 공급업체를 포함한 광범위한 AI 생태계에서 채택되었습니다.
NIM Microservices는 Triton Inference Server™ 및 TensorRT™-LLM을 포함하여 NVIDIA 추론 소프트웨어로 구동되는 사전 구축된 컨테이너를 제공하며, 이를 통해 배포 시간을 몇 주에서 몇 분으로 단축할 수 있습니다.
산업용 디지털 트윈 소프트웨어 도구를 강화하는 Omniverse Cloud API 출시
개발자는 5개의 새로운 Omniverse Cloud API를 사용하여 Omniverse 핵심 기술을 기존 디지털 트윈 설계 및 자동화 소프트웨어 애플리케이션에 직접 통합할 수 있을 뿐만 아니라 로봇이나 자율 주행 자동차를 테스트하고 검증하기 위한 시뮬레이션 워크플로(예: 대화형 산업용 디지털 트윈을 Apple Vision Pro로 스트리밍)에 통합할 수 있습니다.
이러한 API에는 다음이 포함됩니다.
* USD 렌더링:글로벌 레이 트레이싱 OpenUSD 데이터의 NVIDIA RTX™ 렌더링 생성
* USD 쓰기:사용자가 OpenUSD 데이터를 수정하고 상호작용할 수 있도록 합니다.
* USD 쿼리:씬 쿼리와 씬 상호작용을 지원합니다.
* USD 알림:USD 변동을 추적하고 업데이트를 제공합니다.
* 옴니버스 채널:사용자, 도구 및 현실을 연결하여 시나리오 간 협업을 달성합니다.
황런쉰은 미래에는 모든 제조물에 디지털 트윈이 적용될 것이라고 믿는다. 옴니버스는 물리적 현실의 디지털 트윈을 구축하고 실행하기 위한 운영 체제입니다. 옴니버스와 생성적 인공지능은 50조 달러 규모의 중공업 시장을 디지털화하는 기반 기술입니다.
DRIVE Thor: Blackwell 아키텍처를 활용한 생성 AI로 자율주행 실현
DRIVE Thor는 생성적 AI 애플리케이션을 위해 설계된 차량용 컴퓨팅 플랫폼으로, 중앙 플랫폼에서 기능이 풍부한 시뮬레이션 주행과 고도로 자동화된 주행 기능을 제공합니다. 차세대 자율주행차 중앙 컴퓨터로서 안전성과 신뢰성을 갖추고 있으며, 지능형 기능을 하나의 시스템으로 통합하여 전체 시스템의 효율성을 높이고 비용을 절감할 수 있습니다.
DRIVE Thor에는 새로운 NVIDIA Blackwell 아키텍처도 통합됩니다.이 아키텍처는 Transformer, LLM, 생성 AI 워크로드를 위해 설계되었습니다.
BioNeMo: 신약 개발 지원
BioNeMo의 기본 모델은 DNA 염기서열을 분석하고, 약물 분자의 작용에 따른 단백질의 모양 변화를 예측하고, RNA를 기반으로 세포의 기능을 결정할 수 있습니다.
현재 BioNeMo에서 제공하는 첫 번째 게놈 모델인 DNABERT는 DNA 염기서열을 기반으로 하며, 게놈의 특정 영역의 기능을 예측하고, 유전자 돌연변이 및 변이의 영향을 분석하는 데 사용할 수 있습니다. 곧 출시될 두 번째 모델인 scBERT는 단일 세포 RNA 염기서열 분석 데이터를 기반으로 학습됩니다. 사용자는 유전자 녹아웃(즉, 특정 유전자를 삭제하거나 비활성화)의 효과를 예측하고 신경 세포, 혈액 세포 또는 근육 세포와 같은 세포 유형을 식별하는 등의 하위 작업에 이를 적용할 수 있습니다.
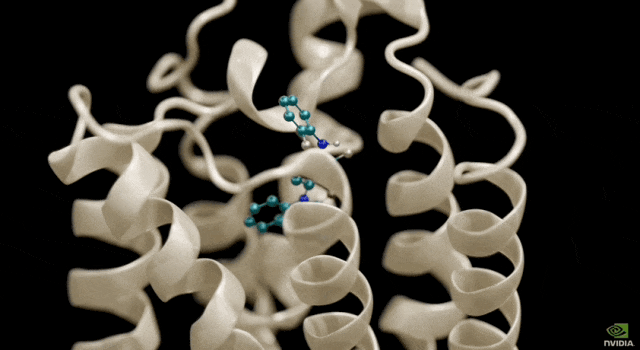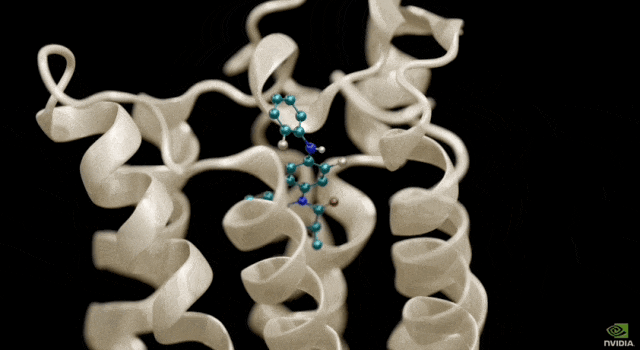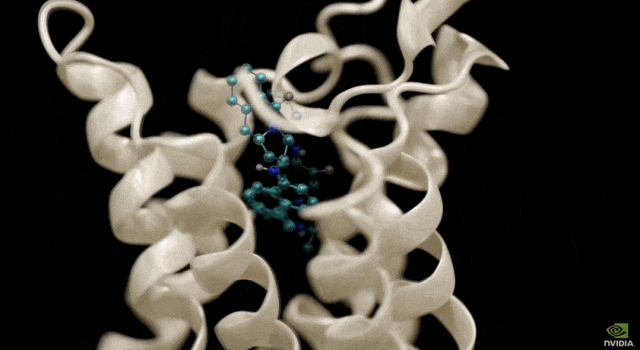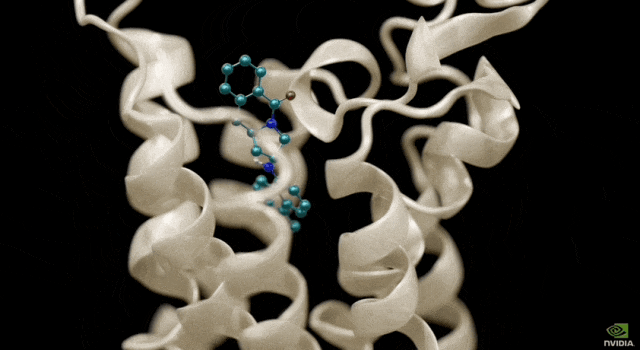
현재 전 세계적으로 BioNeMo를 기반으로 연구 개발 프로세스를 진행하고 있는 회사는 100개가 넘는 것으로 알려졌는데, 여기에는 도쿄에 본사를 둔 Astellas Pharma, 계산 소프트웨어 개발업체 Cadence, 약물 개발 회사 Iambic 등이 있습니다.
마지막 말
황런쉰은 위에서 언급한 많은 신제품 외에도 로봇 분야에서 엔비디아의 레이아웃을 소개했습니다. 황 씨는 움직이는 모든 것이 로봇이며, 자동차 산업이 그 중요한 부분이 될 것이라고 말했습니다. 현재 NVIDIA 컴퓨터는 자동차, 트럭, 배달 로봇, 로봇 택시에 사용되고 있습니다. 이후 NVIDIA는 Isaac Perceptor 소프트웨어 개발 키트, 인간형 로봇의 범용 기반 모델인 GR00T, NVIDIA Thor 시스템 온 칩을 기반으로 한 인간형 로봇용 새로운 Jetson Thor 컴퓨터를 출시하고 NVIDIA Isaac 로봇 플랫폼을 대대적으로 업그레이드했습니다.
요약하자면, 2시간 동안의 공유 세션은 고성능 제품과 모델 소개로 가득 차 있었습니다. 이처럼 빠르고 내용이 풍부한 기자회견은 AI 산업의 현재 발전 상황, 즉 빠르고 번영하는 모습과 정확히 일치합니다.
AI 시대의 기반으로서, 고성능 칩이 대표하는 컴퓨팅 파워는 산업의 발전 주기와 방향을 결정하는 핵심입니다. 현재 엔비디아가 흔들리지 않는 우위를 점하고 있다는 점에는 의심의 여지가 없습니다. 많은 회사가 황을 공격하기 시작했고, OpenAI, 마이크로소프트, 구글 등도 자체 "군대"를 육성하고 있지만, 여전히 빠른 속도로 전진하고 있는 엔비디아에게 이는 더 큰 원동력이 될 수 있습니다.
이제 온라인 라이브 방송은 종료되었습니다. 황런쉰은 새로운 제품이 출시될 때마다 어떤 파트너가 새로운 서비스를 "예약"했는지 소개할 예정이며, 예외 없이 모든 대기업이 목록에 올랐습니다. 미래에는 현재 업계를 선도하는 기업들이 업계의 높은 생산성을 활용해 더욱 혁신적인 제품과 애플리케이션을 선보일 수 있을 것으로 기대합니다.