Command Palette
Search for a command to run...
산둥대학교는 4단계로 유기화합물의 역합성 경로를 식별하기 위해 해석 가능한 딥러닝 알고리즘 RetroExplainer를 개발했습니다.

역합성은 목표 생성물을 효율적으로 합성하기 위해 적합한 일련의 반응물을 찾는 것을 목표로 합니다. 이는 유기 합성 경로를 해결하는 중요한 방법이며, 유기 합성 경로를 설계하는 가장 간단하고 기본적인 방법이기도 합니다.
초기 역합성 연구는 주로 프로그래밍에 의존했지만, 이 작업은 나중에 AI로 대체되었습니다. 그러나 기존의 역합성 방법은 대부분 단일 단계 역합성에 초점을 맞추고 있어 해석성이 좋지 않고, 분자의 단거리 및 장거리 정보를 모두 고려할 수 없어 성능이 제한적입니다.
이를 위해 산둥대학의 웨이레이와 중국 전자과학기술대학의 주취안 연구팀이 공동으로 RetroExplainer를 개발했습니다. 설명 가능한 딥 러닝 알고리즘은 4단계로 유기 화합물의 역합성 경로를 식별하고 쉽게 이용 가능한 반응물을 제공할 수 있습니다. RetroExplainer는 유기화학 분야의 역합성 연구에 강력한 도구를 제공할 것으로 기대됩니다.
저자 | 쉐차이
편집자 | 산양
유기화학에서 역합성은 목표 생성물을 효율적으로 합성하기 위해 적합한 일련의 반응물을 찾는 것을 목표로 합니다.. 이 과정은 컴퓨터 지원 합성에 있어서 필수적인 기본 작업입니다.
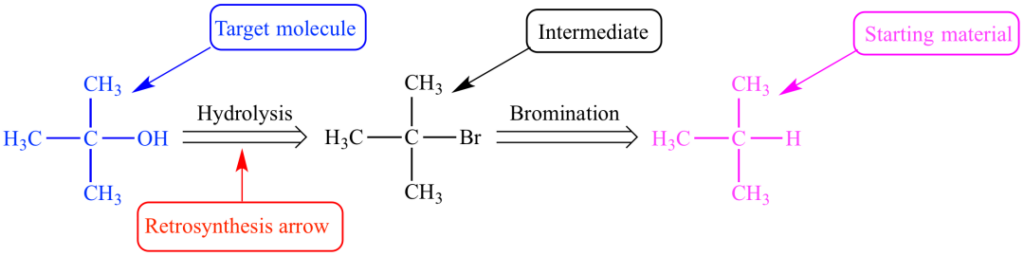
그림 1: tert-부틸 알코올의 역합성 경로
1960년대에는코리 등 프로그래밍을 통해 역합성 분석을 시도했습니다., 유기화학 시뮬레이션 합성(OCSS) 소프트웨어를 개발했습니다. 하지만,데이터 양이 늘어나면서 이 작업은 AI가 빠르게 대체하게 됩니다.. 그 중에서도 딥러닝 모델은 큰 기대를 받고 있으며 상당한 성과를 냈습니다.
초기 AI 역합성 연구에서 연구자들은 종종 반응 템플릿을 기반으로 생성물에서 반응물로 역으로 작업했습니다. 즉, 템플릿 기반 역합성이었습니다.. 그 중에서도 다층 퍼셉트론을 기반으로 한 분자 지문은 제품 인코딩과 템플릿 선택에 자주 사용됩니다.
그 다음에,연구자들은 템플릿 없는 합성 방법과 반템플릿 합성 방법을 탐색하기 시작했습니다.주로 다음을 포함합니다.
1. 시퀀스 기반 역합성
2. 다이어그램 기반 역합성.
두 가지의 주요 차이점은 분자가 표현되는 형태에 있습니다. 전자는 SMILES 사양과 같이 분자를 표현하기 위해 선형화된 문자열을 사용합니다. 후자는 분자 그래프 모델을 사용하여 분자를 표현하는데, 여기에는 주로 반응 중심(RC)의 예측과 합성체의 완성이 포함됩니다.
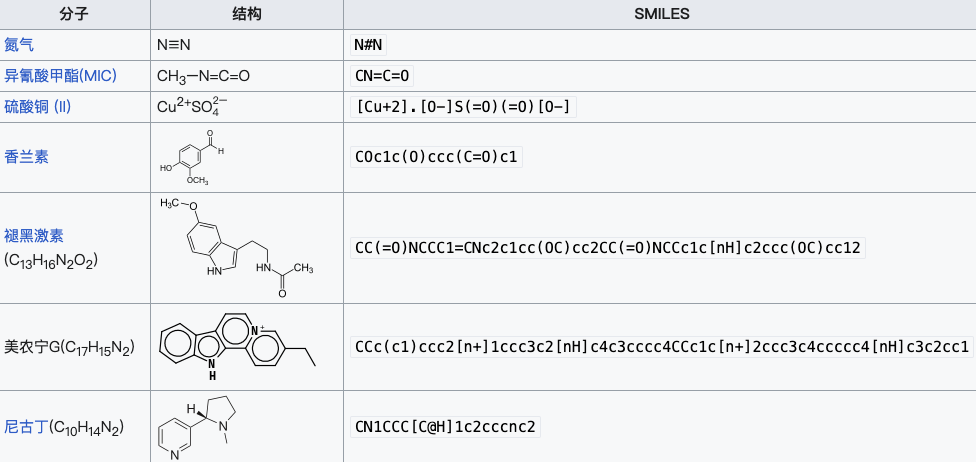
그림 2: 일부 물질의 SMILES 표현
기존의 역합성 방법은 상당한 진전을 이루었지만,그러나 여전히 3가지 내생적 문제가 존재한다.:
1.시퀀스 기반 역합성은 분자 정보를 놓치는 반면 그래프 기반 역합성은 분자의 시퀀스 정보와 장거리 특징을 무시합니다.. 두 방법 모두 기능 학습에 한계가 있으며 성능을 개선하기 어렵습니다.
2.딥러닝 기반 역합성 방법은 해석성이 낮습니다.. 템플릿 기반 역합성은 이해하기 쉬운 합성 경로를 제공할 수 있지만, 알고리즘의 의사 결정 메커니즘은 여전히 모호하며, 모델의 재현성과 실현 가능성을 고려해야 합니다.
3.기존 방법은 대부분 단일 단계 역합성에 초점을 맞춥니다.. 이 접근 방식은 적절한 반응물을 제공하는 것처럼 보이지만, 이러한 반응물을 구입하기 어렵거나 복잡한 처리 과정이 필요할 수 있습니다. 따라서 실제 화학 합성에서는 다단계 역합성이 더 의미가 있을 수 있습니다.
이를 위해,산둥대학교의 웨이레이(Wei Leyi)와 중국 전자과학기술대학의 주취안(Zou Quan) 연구팀이 공동으로 RetroExplainer를 개발했습니다. . 이 알고리즘은 알고리즘의 해석 가능성과 실현 가능성을 고려하면서 딥 러닝을 기반으로 역합성 예측을 수행할 수 있습니다. RetroExplainer는 약 12개의 벤치마크 데이터 세트에서 다른 알고리즘보다 우수한 성능을 보였으며, 제안된 TP3T 합성 경로의 반응 중 86.91%가 문헌을 통해 검증되었습니다. 이 결과는 Nature Communications에 게재되었습니다.

이 결과는 Nature Communications에 게재되었습니다.
논문 링크:
https://www.nature.com/articles/s41467-023-41698-5
공식 계정을 팔로우하고 "retrosynthesis"라고 답글을 달면 전체 논문 PDF를 받을 수 있습니다.
실험 절차
알고리즘 구축:모듈 + 서브그리드
역합성 분석 과정 전체는 분자 그래픽 인코딩, 다중 작업 학습, 의사 결정, 다단계 합성 경로 예측의 4단계로 구성됩니다.
RetroExplainer는 주로 다중감각 다중스케일 그래프 변환기(MSMS-GT), 동적 적응형 다중작업 학습(DAMT), 설명 가능한 결정 모듈, 경로 예측 모듈의 4개 모듈로 구성됩니다.
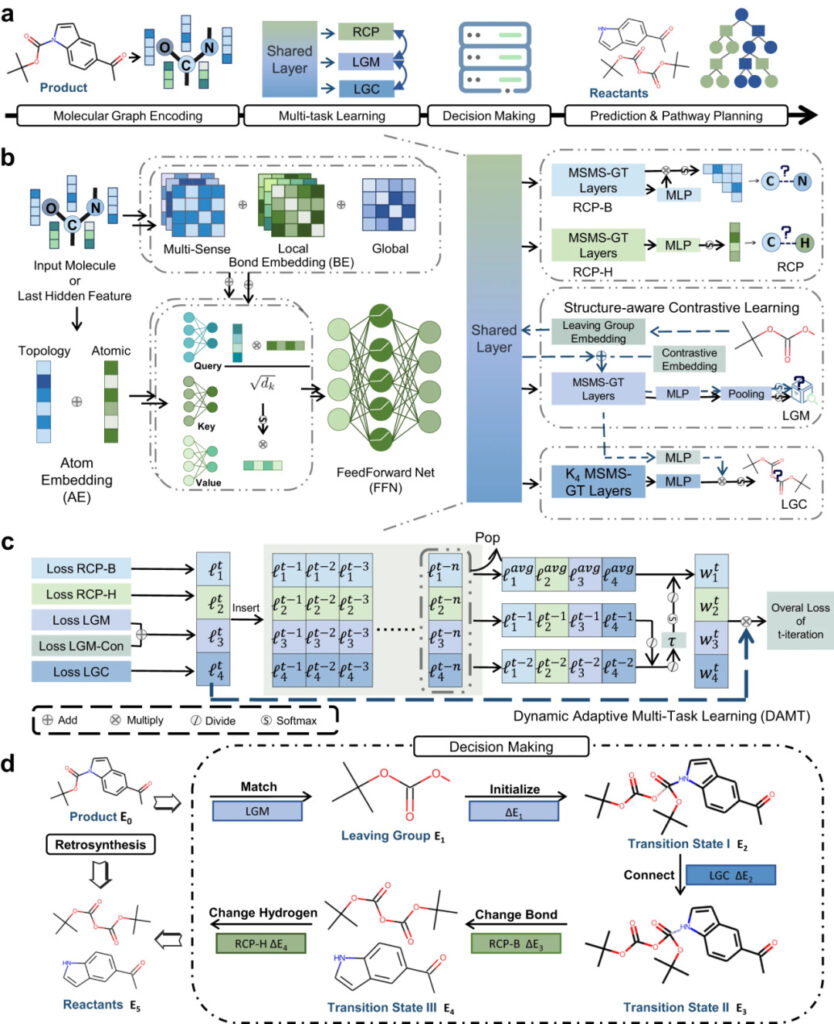
그림 3: RetroExplainer 및 해당 모듈의 개략도
a: RetroExplainer 프로세스 다이어그램;
b: MSMS-GT 아키텍처;
c: DAMT 알고리즘의 개략도;
d: 반응 메커니즘과 유사한 의사결정 과정.
MSMS-GT는 화학 결합 삽입과 원자의 위상적 삽입을 통해 중요한 화학 정보를 포착합니다. 인코딩된 정보는 Multi-Head Attention 메커니즘을 통해 분자 벡터로 융합됩니다.
DAMT 모듈에서는 분자 정보가 반응 중심 예측(RCP), 이탈 그룹 일치(LGM), 이탈 그룹 연결(LGC) 하위 그리드에 동시에 입력됩니다.
RCP는 화학 결합의 변화와 원자에 인접한 수소 원자의 수를 식별하고, LGM은 생성물의 이탈기를 데이터베이스에 있는 이탈기와 일치시키고, LGC는 이탈기를 생성물 잔류물에 연결합니다.
결정 모듈은 5가지 역합성 작용과 결정 곡선의 에너지 점수(E)를 기반으로 생성물을 반응물로 변환하고, 분자 조립 과정을 역으로 시뮬레이션합니다.
마지막으로, 휴리스틱 트리 탐색 알고리즘을 사용하여 반응물의 가용성을 보장하는 동시에 효율적인 제품 합성 경로를 찾습니다.
성능 비교:USPTO 벤치마크 데이터 세트
연구진은 RetroExplainer의 성능을 검증하기 위해 미국 특허상표청(USPTO)에 포함된 화학 반응을 기반으로 한 21개의 다른 역합성 알고리즘과 비교했으며, 평가 지표는 Top-k 정확도였습니다.
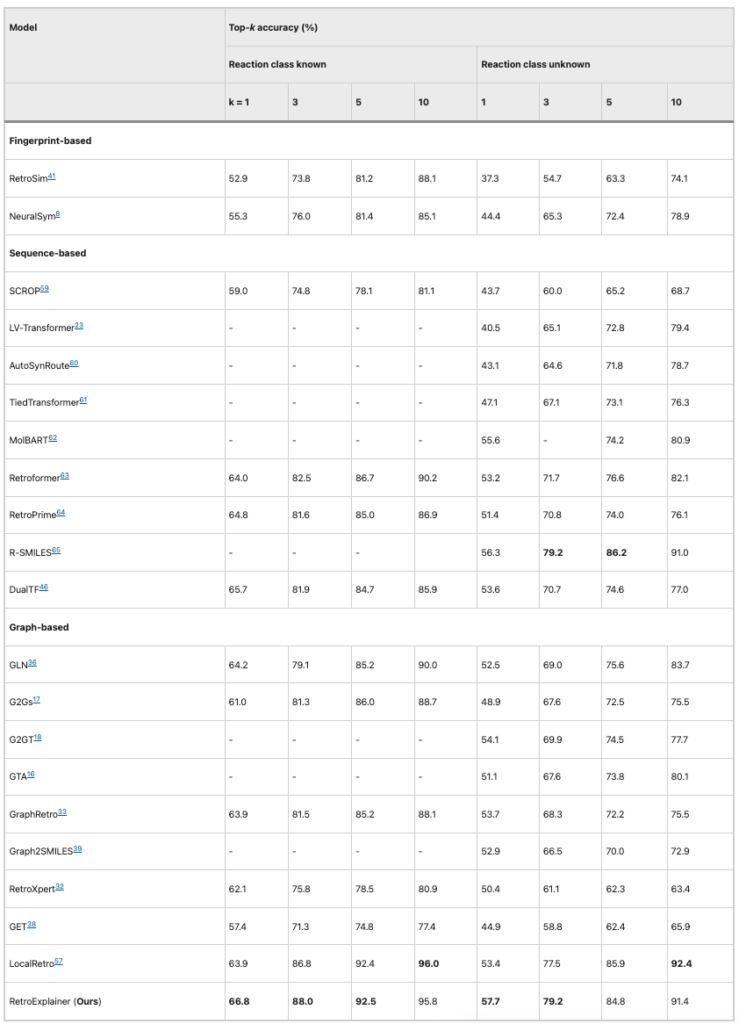
표 1: RetroExplainer와 다른 알고리즘의 성능 비교(USPTO-50K)
USPTO-50K 데이터셋을 기준으로 볼 때, 8개의 평가 지표 중RetroExplainer는 5가지 측면에서 다른 알고리즘보다 성능이 뛰어나며 평균 정확도에서 1위를 차지했습니다.. RetroExplainer는 Top 10 정확도 측면에서 LocalRetro보다 떨어지지만, 두 모델의 차이는 단 1%에 불과합니다.
유사한 분자의 영향을 제거하기 위해 연구진은 Tanimoto Similarity를 사용하여 데이터를 재분할하고 가장 정확한 두 가지 알고리즘인 R-SMILE과 LocalRetro와 비교했습니다.
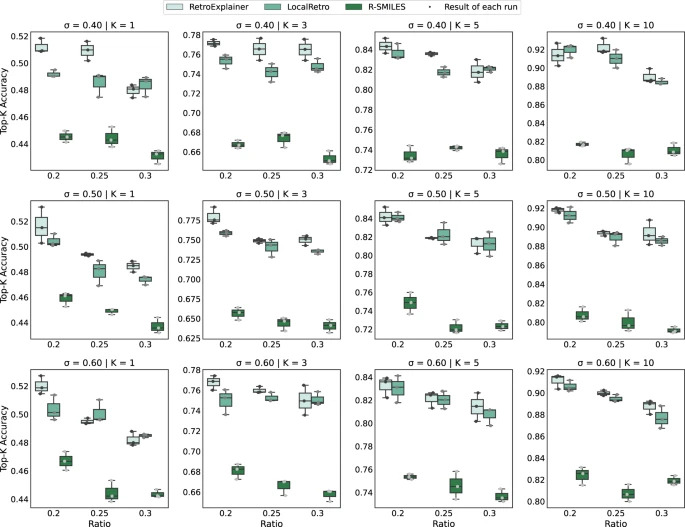
그림 4: 다양한 데이터 세트에서 RetroExplainer, R-SMILES 및 LocalRetro의 성능 비교
결과에서 볼 수 있듯이 RetroExplainer는 대부분의 데이터 세트에서 더 나은 성능을 보이며, 이는 안정성과 적응성을 반영합니다.
그런 다음 연구자들은 더 큰 USPTO-MIT와 USPTO-FULL 데이터 세트에서 알고리즘 성능을 비교했습니다. RetroExplainer는 모든 지표에서 다른 알고리즘보다 우수한 성과를 보였으며, 다른 알고리즘과의 격차는 더욱 큽니다.이는 RetroExplainer가 대규모 데이터 분석에서 더 큰 잠재력을 가지고 있음을 보여줍니다.
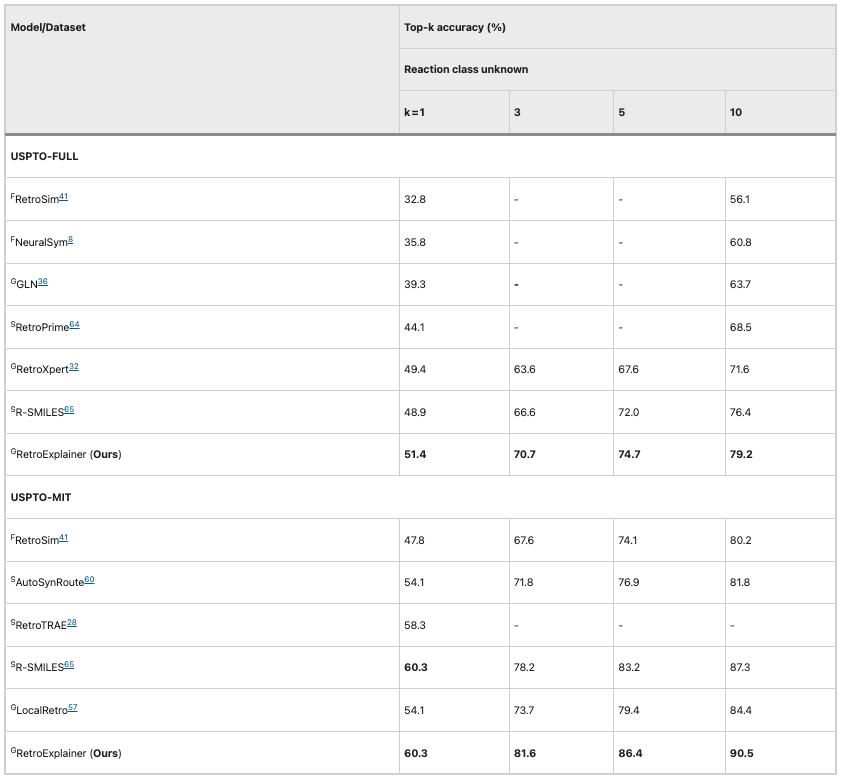
표 2: RetroExplainer와 다른 알고리즘(USPTO-MIT 및 USPTO-FULL)의 성능 비교
설명 가능성:의사결정 시각화
연구진은 이분자 친핵성 치환 반응(SN2)에서 영감을 얻어 딥 러닝 기반 분자 조립을 기반으로 해석 가능한 역합성 예측 프로세스를 설계했습니다. 의사결정 과정은 원래 생성물(P), 이탈기 매칭(S-LGM), 초기화(IT), 이탈기 연결(S-LGC), 반응 중심 화학 결합 변화(S-RCP), 수소 원자 수 변화(HC)의 6단계로 구성됩니다.
DAMT 하위 그리드는 최종 결정에 대한 각 단계의 기여도를 바탕으로 각 단계에 대한 에너지 점수(E)를 생성합니다.
구체적인 과정은 다음과 같습니다.
1. P단계에서는 각 단계의 E는 0으로 초기화됩니다.
2. S-LGM 단계에서는 LGM 모듈의 예측 확률을 기반으로 이탈 그룹이 선택됩니다.
3. S-LGM 단계에서 선정된 이탈기의 E를 RCP 및 LGM 모듈이 예측한 반응 사건 확률에 더하여 IT 단계의 에너지를 구한다.
4. S-LGC 및 S-RCP 단계에서는 동적 프로그래밍 알고리즘을 기반으로 탐색 트리의 모든 가능한 노드가 확장됩니다. 사전 설정된 임계값보다 확률이 큰 이벤트를 선택하고 E를 고정합니다.
5. 각 원자의 수소 원자 수와 형식 전하를 조정하여 최종 분자도가 원자가 규칙에 맞는지 확인하고 최종 E를 계산합니다.
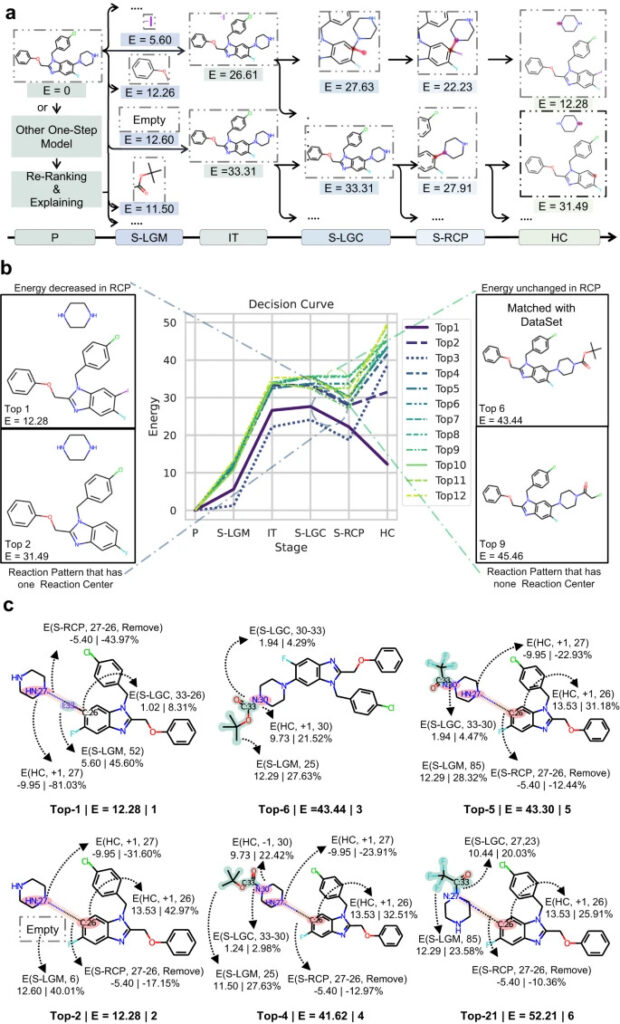
그림 5: RetroExplainer의 의사 결정 프로세스
a: 두 개의 예측 결과에 대한 RetroExplainer의 검색 경로.
b: 상위 12개 예측 경로의 결정 곡선
c: 합성 경로를 나타내는 6가지 구조적 변화 과정.
E의 변화에 따른 결정 곡선을 그리면 RetroExplainer의 결정 과정을 분석하고 RetroExplainer의 예측 오류를 알아낼 수 있습니다.
그림에서 보듯이, 생성물의 올바른 합성 경로는 아민의 탈보호 반응이어야 하지만, RetroExplainer는 이를 6위로 평가하고, CN 커플링 반응을 1위로 선정했습니다. 분석 결과, RetroExplainer는 HC 단계에서 아민의 수소 원자 수를 증가시키는 경향이 있었고, 이로 인해 이러한 차이가 나타났습니다.이는 RetroExplainer가 HC 단계에서 유사한 구조를 가진 분자에 대해서도 동일한 잘못된 판단을 내릴 수 있음을 나타냅니다.
1위와 2위 RetroExplainer의 반응을 비교해보면,연구자들은 E가 응답의 어려움과 관련이 있을 수 있음을 발견했습니다.. 반응 1에서 I:33과 C:26의 연결은 에너지 감소에 도움이 되지 않지만, C:26에 수소 원자를 연결하는 데는 이전 반응보다 13배의 에너지가 필요합니다. 동시에 I:33의 도입으로 CN 커플링 반응에서 발생하는 선택성 문제가 약화되었습니다.
동시에,입체 장애는 RetroExplainer의 예측 결과에도 영향을 미칠 수 있습니다.. 4위와 21위를 비교해보면, 분자 구조는 동일하지만, 이탈기가 대칭적인 N에 붙어 있어서 E에 차이가 있습니다.
경로 계획:다단계 예측 합성 경로
연구진은 RetroExplainer의 예측의 실용성을 개선하기 위해 이를 Retro 알고리즘과 결합하여 후자의 단일 단계 예측을 다단계 예측으로 대체했습니다.
기관지 확장제인 프로토킬롤을 예로 들어, RetroExplainer는 이 제품에 대한 4단계 합성 경로를 설계했습니다. 연구자들은 이러한 4단계 반응에 대한 문헌 검토를 실시하여 그 실현 가능성을 알아보았습니다.
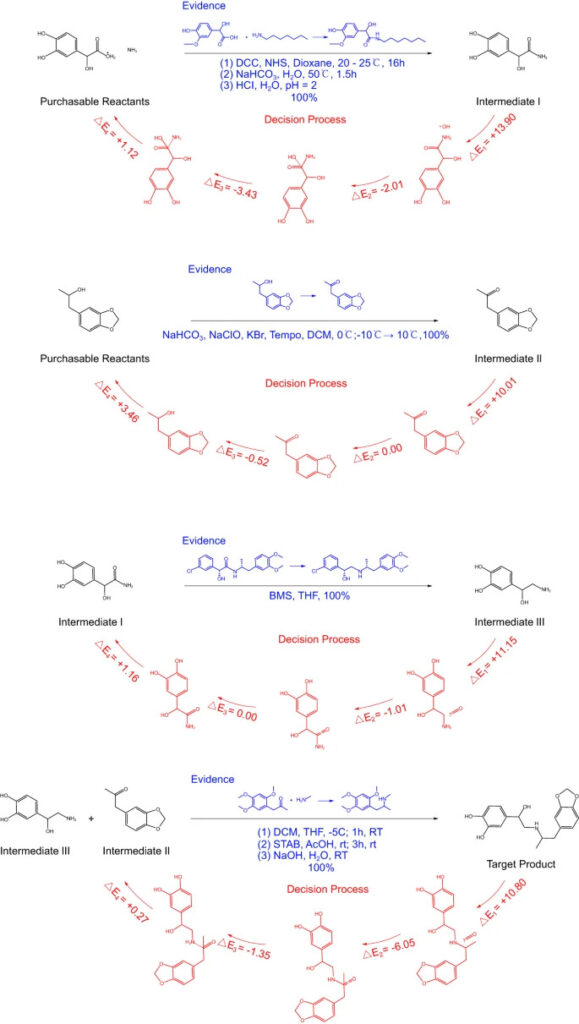
그림 6: RetroExplainer의 프로토산 4단계 합성
그림 속 파란색 글씨는 참고문헌에 기록된 유사한 응답이고, 빨간색 부분은 RetroExplainer의 의사결정 과정입니다.
많은 반응에서 정확히 동일한 참조물을 찾지는 못했지만, 유사한 고수율 반응을 발견했습니다. 또한,RetroExplainer는 101가지 사례에 대해 176가지 실험을 설계했으며, 그 중 153가지를 SciFinder에서 유사한 반응을 찾을 수 있었습니다.
위의 결과는 RetroExplainer의 역합성 예측이 다른 현재 알고리즘보다 우수함을 보여줍니다. 동시에 RetroExplainer의 결정은 투명하고 설명 가능하며, 응답에 대한 다단계 계획을 수행하므로 실행 가능성이 더 높습니다. RetroExplainer는 유기화학 분야의 역합성 연구에 강력한 도구를 제공할 것으로 기대됩니다.
성능 vs 설명 가능성, AI의 모순
설명 가능성은 다양한 시나리오에서 AI를 적용하는 데 있어 핵심 요소입니다.. 자율주행, 의료 진단, 금융 및 보험 등의 산업에서 AI가 지속적으로 발전함에 따라 AI의 의사결정 과정은 점점 더 중요해졌으며, 점점 더 많은 실용적, 사회적, 심지어 법적 문제에 직면하게 되었습니다.
동시에 설명 가능성은 사용자가 AI를 이해하고 유지 관리하고 사용할 수 있도록 돕고, AI 응용 분야에서 새로운 개념을 발견하고 이해할 수 있도록 도와줍니다. 설명 가능성은 또한 결과의 실현 가능성을 보여주고 사용자에게 어떤 결정이 가장 큰 이익을 가져올지 알려줍니다.
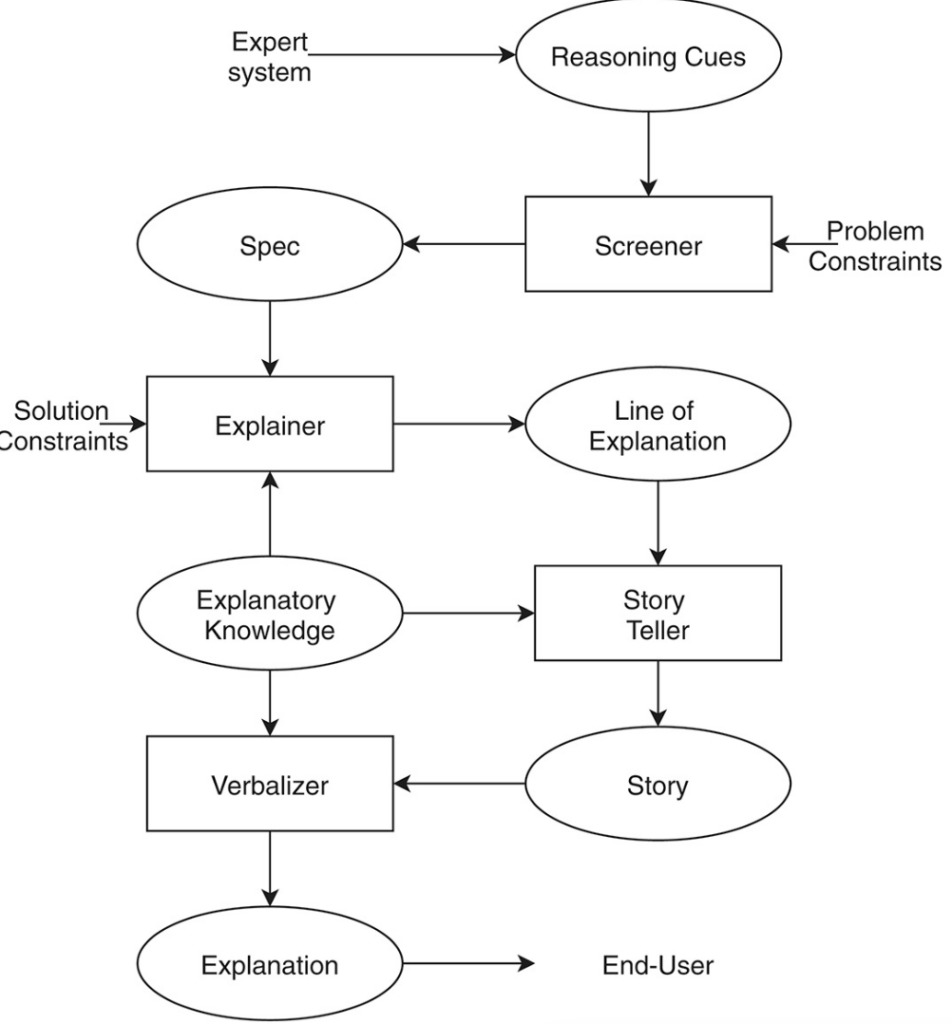
그림 7: 문제 해결 프로세스의 설명 단계
하지만,모델 성능과 모델 해석 가능성은 ScienceAI의 큰 문제입니다.모델이 좋은 성능과 좋은 교차 테스트 세트 견고성을 갖고 있다면 고차원 딥 피처가 더 잘 작동할 수 있지만, 우리가 종종 "라고 부르는 물리적 의미가 없습니다.과학 연구의 해석 가능성은 일반적으로 좋지 않습니다.".
반면, 잘 설명된 특징을 사용하더라도 물리적으로는 해석 가능성이 높지만, 실제 모델 성능은 데이터에 크게 의존하게 되고, 데이터 세트가 변경되면 모델 성능이 저하됩니다.
아직은 둘 사이의 모순을 통합할 좋은 방법이 없지만, 이 연구에서 연구자들은 AI의 의사결정 과정을 단계별로 시각화했습니다.이를 통해 사용자는 각 단계별 다양한 예측 결과의 점수 변화를 명확하게 파악하고, AI의 의사결정 과정을 이해하며, 개발자가 모델을 최적화하는 데 도움이 됩니다.
설명 가능한 AI가 지속적으로 발전함에 따라 사람들은 AI에 대한 이해가 더욱 깊어지고, AI의 의사결정 과정을 더 쉽게 이해할 수 있게 될 것입니다.미래에는 인간과 기계의 상호작용이 더욱 활발해지고, 상호작용의 문턱은 더욱 낮아지며, AI가 더 많은 분야에 활용되어 삶이 더욱 편리하고 지능화될 것입니다.
참조 링크:
[1]http://www.chem.ucla.edu/~harding/IGOC/R/레트로합성.html
[2] https://zh.wikipedia.org/zh-cn/간소화된 분자 선형 입력 사양
[3]https://wires.onlinelibrary.wiley.com/doi/10.1002/widm.1391