Command Palette
Search for a command to run...
"고래 얼굴 인식"이 이제 온라인에 공개되었습니다. 하와이 대학은 50,000개의 이미지를 사용하여 평균 정확도 0.869의 인식 모델을 훈련합니다.

내용을 한눈에 보기:얼굴 인식은 인간의 신원을 확인할 수 있으며, 이 기술은 고래에게까지 확장되어 '등지느러미 인식'이라는 결과를 낳았습니다. "등지느러미 식별"은 이미지 인식 기술을 사용하여 등지느러미를 통해 고래 종을 식별합니다. 기존의 이미지 인식은 합성곱 신경망(CNN) 모델에 의존하는데, 이는 많은 수의 학습 이미지가 필요하고 특정한 단일 종만 인식할 수 있습니다. 최근 하와이 대학의 연구자들은 고래 응용 분야에서 좋은 성과를 보이는 다양한 종의 이미지 인식 모델을 훈련시켰습니다.
키워드:이미지 인식 고래류 ArcFace
저자: daserney
편집자: 환환, 삼양
본 기사는 HyperAI WeChat 공개 플랫폼에 처음 게재되었습니다.~
고래류는 해양 생태계의 대표적 동물이자 지표생물로, 해양 생태환경을 보호하는 데 있어 연구 가치가 매우 높습니다.전통적인 동물 식별에는 현장에서 동물 사진을 찍고 개별 동물이 나타난 시간과 위치를 기록하는 것이 필요했습니다. 여러 단계가 필요하고 과정도 복잡합니다.그 중에서도 이미지 매칭, 즉 서로 다른 이미지에서 동일한 개인을 식별하는 작업은 특히 시간이 많이 걸립니다.
Tyne 등이 2014년에 실시한 연구 1년간의 점박이 돌고래(Stenella longirostris)에 대한 포획 및 방류 조사 동안 추정된 바에 따르면,이미지 매칭에는 1,100시간 이상의 수작업이 필요했으며, 이는 총 프로젝트 비용의 약 3분의 1을 차지했습니다..
최근 하와이 대학의 필립 T. 패튼을 포함한 연구진은 50,000장 이상의 사진(고래 24종과 카탈로그 39개 포함)을 사용하여 얼굴 인식 ArcFace Classification Head를 기반으로 하는 다종 이미지 인식 모델을 훈련했습니다.이 모델은 테스트 세트에서 0.869의 평균 정밀도(MAP)를 달성했습니다. 이 중 10개 디렉토리의 MAP 점수는 0.95를 초과했습니다.
이 연구는 "사진 식별을 위한 딥러닝 접근법이 20여 종의 고래류에 대해 높은 성능을 보인다"라는 제목으로 '생태와 진화 방법' 저널에 게재되었습니다.

해당 연구 결과는 Methods in Ecology and Evolution에 게재되었습니다.
서류 주소:
https://besjournals.onlinelibrary.wiley.com/doi/full/10.1111/2041-210X.14167
데이터 세트: 25종, 39개 카탈로그
데이터 소개
Happywhale과 Kaggle은 전 세계 연구자들과 협력하여 대규모의 다양한 종에 대한 고래 데이터 세트를 조립했습니다. 이 데이터 세트는 등지느러미/측면 사진에서 개별 고래를 식별해야 하는 Kaggle 경연대회를 위해 수집되었습니다.이 데이터 세트에는 25종의 41개 카탈로그가 포함되어 있으며, 각 카탈로그에는 한 종이 포함되어 있고 카탈로그의 일부 종은 반복적으로 나타납니다.
이 연구에서는 경쟁 카탈로그 두 개를 제거했는데, 그 중 하나는 훈련 및 테스트를 위한 저품질 이미지가 26개만 있었고, 다른 카탈로그에는 테스트 세트가 없었기 때문입니다.최종 데이터 세트에는 50,796개의 훈련 이미지와 27,944개의 테스트 이미지가 포함되어 있으며, 그 중 50,796개의 훈련 이미지에는 15,546개의 ID가 포함되어 있습니다.이러한 ID 중 9,240개(59%)는 훈련 이미지가 1개만 있고, 14,210개(91%)는 훈련 이미지가 5개 미만입니다.
데이터 세트 및 코드 주소:
https://github.com/knshnb/kaggle-happywhale-1st-place
훈련 데이터
이미지의 복잡한 배경 문제를 해결하기 위해 일부 참가자는 이미지에서 고래를 자동으로 감지하고 그 주위에 경계 상자를 그릴 수 있는 이미지 자르기 모델을 훈련했습니다. 아래 그림에서 볼 수 있듯이,이 파이프라인에는 YOLOv5와 Detic을 포함한 다양한 알고리즘을 사용하는 4개의 고래 감지기가 포함되어 있습니다.검출기의 다양성은 모델의 견고성을 높이고 실험 데이터에 대한 데이터 증강을 가능하게 합니다.

그림 1: 경쟁 세트의 9개 카테고리 이미지와 4개의 고래 감지기에서 생성된 경계 상자
각 경계 상자에 의해 생성된 작물의 확률은 빨간색의 경우 0.60, 올리브 그린의 경우 0.15, 주황색의 경우 0.15, 파란색의 경우 0.05입니다. 연구자들은 잘라낸 후 각 이미지의 크기를 EfficientNet-B7 백본과 호환되도록 1024 x 1024 픽셀로 조정했습니다.
크기 조정 후 아핀 변환, 크기 조정 및 자르기, 회색조, 가우시안 블러 등의 데이터 증강 기술을 적용합니다.모델을 피하세요심각한 과적합.
데이터 증강은 학습 과정에서 원본 데이터를 변환하거나 확장하여 학습 샘플의 다양성과 양을 늘리고, 이를 통해 모델의 일반화 능력과 견고성을 개선하는 것을 말합니다.
모델 훈련: 종 및 개체 식별
다음 그림은 주황색 부분에 표시된 모델의 학습 과정을 보여줍니다.연구자들은 이미지 인식 모델을 척추, 목, 머리의 세 부분으로 나누었습니다.
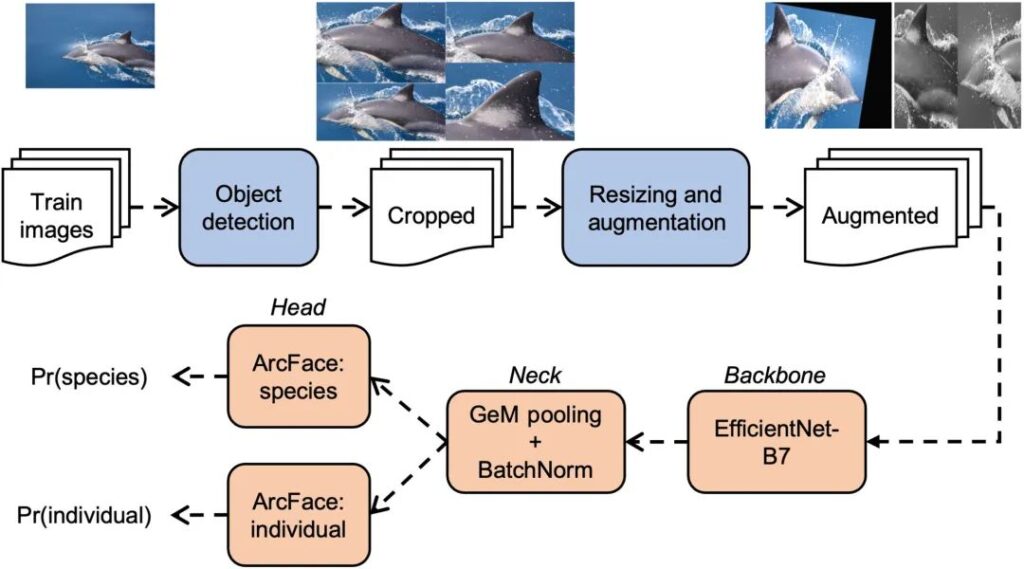
그림 2: 다중 종 이미지 인식 모델 훈련 파이프라인
그림의 첫 번째 행은 전처리 단계를 보여줍니다(일반 돌고래인 Delphinus delphis의 이미지를 예로 들어 보겠습니다).4개의 객체 감지 모델을 통해 작물이 생성되고, 데이터 증강 단계에서는 두 개의 예시 이미지가 생성됩니다.
아래 행은 이미지 분류 네트워크의 학습 단계를 보여줍니다.척추부터 목을 거쳐 머리까지.
이미지는 먼저 네트워크를 거쳐 백본으로 이동합니다.지난 10년 동안 진행된 일련의 연구를 통해 ResNet, DenseNet, Xception, MobileNet을 포함한 수십 개의 인기 있는 백본이 탄생했습니다. 입증됨,EfficientNet-B7은 고래류 응용 프로그램에서 가장 좋은 성능을 보입니다.
백본은 이미지를 가져와 일련의 합성곱 및 풀링 계층을 통해 처리하여 이미지의 단순화된 3D 표현을 생성합니다. 넥은 이 출력을 1차원 벡터, 즉 고유 벡터로 축소합니다.
두 헤드 모델 모두 특징 벡터를 클래스 확률, 즉 Pr(종) 또는 Pr(개체)로 변환합니다.각각 종 식별과 개체 식별에 사용됩니다.이러한 분류 헤드는 동적 마진을 갖춘 하위 중심 ArcFace라고 불리며 일반적으로 다중 종 이미지 인식 시나리오에 적용할 수 있습니다.
실험 결과: 평균 정확도 0.869
우리는 테스트 세트(24개 종의 39개 카탈로그)에서 21,192개 이미지에 대한 예측에 대해 0.869의 평균 정확도(MAP)를 얻었습니다.아래 그림에서 볼 수 있듯이, 평균 정밀도는 종마다 다르며 훈련 또는 테스트 이미지의 수와 무관합니다.
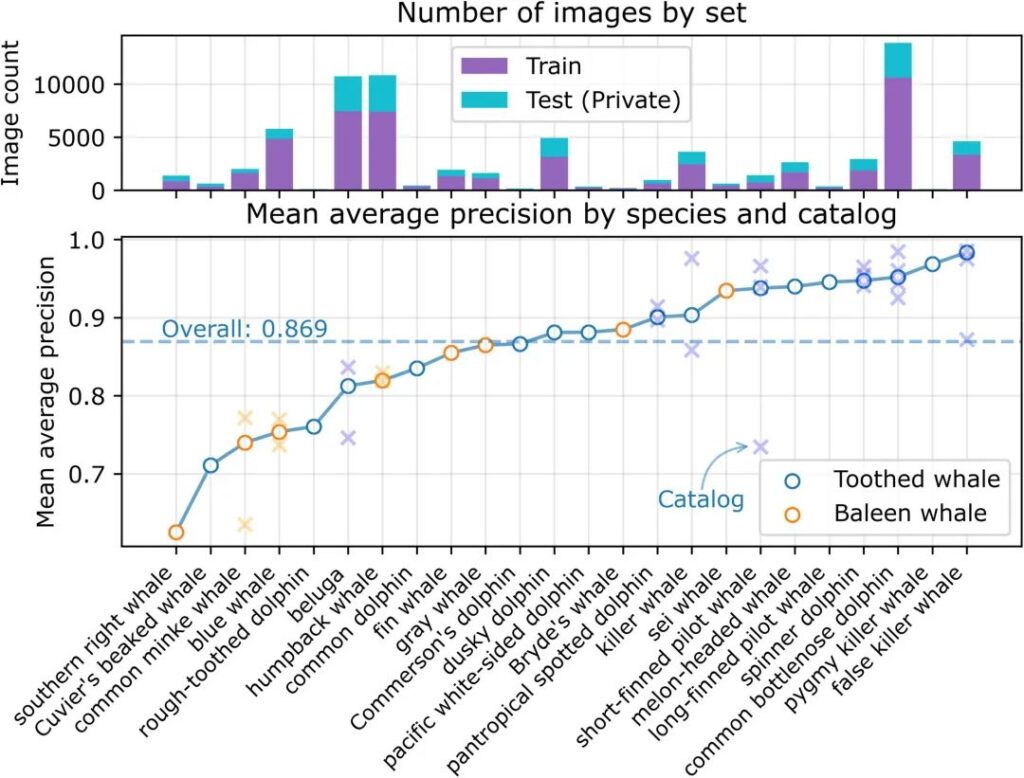
그림 3: 테스트 세트의 평균 정밀도
상단 패널은 목적(예: 훈련 또는 테스트)에 따라 각 종에 대한 이미지 수를 보여줍니다. 여러 카탈로그에 있는 종은 x로 표시됩니다.
그림은 이 모델이 이빨고래를 식별하는 데는 더 나은 성과를 보이지만, 수염고래를 식별하는 데는 성과가 떨어진다는 것을 보여줍니다.수염고래 종 중 평균 이상의 성적을 거둔 종은 두 종뿐이었습니다.
다중 카탈로그 종에 대한 모델 성능에도 차이가 있습니다.예를 들어, 여러 카탈로그 간의 일반 밍크고래(Balaenoptera acutorostrata)의 MAP 점수는 각각 0.79와 0.60이었습니다. 흰돌고래(Delphinapterus leucas)와 범고래와 같은 다른 종들도 카탈로그 간에 성능에 큰 차이를 보입니다.
연구자들은 이 디렉토리 수준의 성능 차이를 설명할 이유를 찾지 못했지만,하지만 그들은 흐릿함, 고유성, 레이블 혼동, 거리, 대비, 튀김 등과 같은 일부 정성적 지표가 이미지의 정확도 점수에 영향을 미칠 수 있다는 것을 발견했습니다.
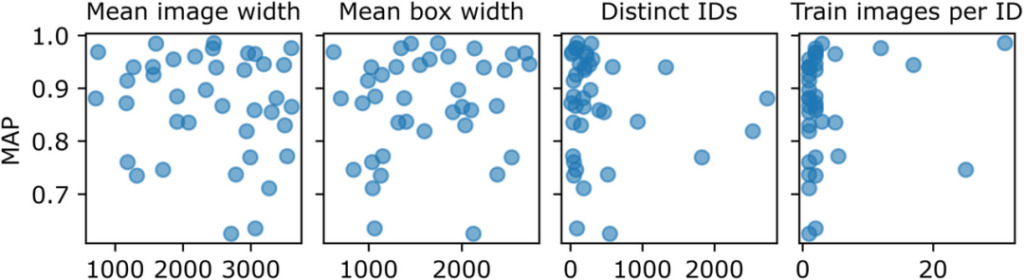
그림 4: 디렉토리 수준 성능 차이에 영향을 줄 수 있는 변수
그림의 각 점은 경쟁 데이터 세트의 디렉토리를 나타내고, 픽셀은 이미지와 경계 상자 너비를 나타냅니다. 고유 ID는 훈련 세트에 있는 고유 개인의 수를 나타냅니다. 하지만,카탈로그 수준 MAP과 평균 이미지 너비, 평균 경계 상자 너비, 훈련 이미지 수, 다양한 개인의 수, 개인당 훈련 이미지 수 사이에는 명확한 상관 관계가 없습니다.
요약하자면, 연구자들은 이 모델을 예측에 사용할 경우 7개 종을 대표하는 10개 카탈로그의 평균 정확도가 0.95보다 높았으며, 기존 예측 모델보다 성능이 더 우수하다고 제안했습니다. 이는 이 모델을 사용하면 개체를 정확하게 식별할 수 있음을 추가로 보여줍니다.또한 연구진은 실험 중 고래 연구에 대한 7가지 사항을 요약했습니다.
- 등지느러미 식별이 가장 잘 수행되었습니다.
- 개별적인 특징이 적은 디렉토리는 성과가 좋지 않았습니다.
- 이미지 품질이 중요합니다.
- 색깔로 동물을 식별하는 것은 어려울 수 있습니다.
- 훈련 세트와 특성이 다른 종은 낮은 점수를 받습니다.
- 전처리는 여전히 어려운 문제로 남아 있다.
- 동물 표시의 변화는 모델 성능에 영향을 미칠 수 있습니다.
Happywhale: 고래류 연구를 위한 시민 과학 플랫폼
이 기사의 데이터 세트 소개에서 언급한 Happywhale은 고래 이미지를 공유하는 공공 과학 플랫폼입니다.이 기술의 목표는 대규모 데이터 세트를 활용하고 사진 ID 일치를 빠르게 촉진하는 것입니다.대중을 위한 과학 연구 참여를 창출합니다.
Happywhale 공식 웹사이트 주소:
해피웨일은 2015년 8월에 설립되었습니다. 공동 창립자인 테드 치즈먼은 캘리포니아주 몬터레이 베이에서 자란 자연주의자입니다. 그는 어렸을 때부터 고래 관찰을 좋아했고 남극과 사우스조지아 섬을 여러 번 여행했습니다.그는 남극 탐험과 극지방 관광 관리 분야에서 20년 이상의 경험을 쌓았습니다.

해피웨일 공동 창립자 테드 치즈먼
테드는 21년간 일한 Cheesemans' Ecology Safaris(자연주의자인 부모가 1980년에 설립한 생태관광 회사)를 떠나 2015년에 Happywhale 프로젝트에 합류했습니다. 고래에 대한 이해와 보존을 증진하기 위해 과학적 데이터를 수집합니다.
단 몇 년 만에,Happywhale.com은 고래 연구 분야에 가장 큰 기여를 하는 사이트 중 하나가 되었습니다.엄청난 수의 고래 식별 이미지 외에도 고래의 이동 패턴을 이해하는 데 많은 통찰력을 제공합니다.
참조 링크:
[1]https://baijiahao.baidu.com/s?id=1703893583395168492
[2]https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0086132
[3]https://phys.org/news/2023-07-개별-고래-돌고래-아이디-페이셜.html#구글_비네트
[4]https://happywhale.com/about
본 기사는 HyperAI WeChat 공개 플랫폼에 처음 게재되었습니다.~