Command Palette
Search for a command to run...
컬럼비아 대학교, 극심한 강수량을 정확하게 예측하기 위해 신경망 Org-NN의 업그레이드 버전 출시

내용 한눈에 보기: 환경 변화가 심화됨에 따라 최근 몇 년 동안 전 세계적으로 극심한 기상 현상이 자주 발생하고 있습니다. 강수 강도를 정확하게 예측하는 것은 인간과 자연환경 모두에게 매우 중요합니다. 기존 모델은 분산이 작은 강수량을 예측하고, 가벼운 비를 예측하는 경향이 있으며, 극심한 강수량은 과소 예측하는 경향이 있습니다.
키워드: 극한 날씨를 위한 암묵적 학습 신경망
본 기사는 HyperAI WeChat 공개 플랫폼에 처음 게재되었습니다~
태풍 두수루이의 영향으로 베이징은 7월 29일부터 며칠 동안 연속으로 폭우를 기록했으며, 일부 지역에서는 극도로 많은 비가 내렸습니다. 극심한 폭우로 인해 하이허 유역에 대규모 홍수가 발생하였고, 먼터우거우, 줘저우 등지에서는 심각한 홍수 재해가 발생했습니다.
CCTV.com의 7월 31일 보도에 따르면, 이번 폭우로 베이징은 1,000만 입방미터가 넘는 물을 빼냈는데, 이는 이화원에 있는 쿤밍 호수 약 5곳의 물이 빠지는 양과 맞먹는 양입니다.극심한 강수량을 시기적절하고 정확하고 효과적으로 예측하면 사상자를 최소화하고 기상 재해로 인한 손실을 줄일 수 있습니다.
기존 기후 모델 매개변수화에는 아격자 규모의 구름 구조와 조직 정보가 부족하여, 거친 해상도에서 강수 강도와 무작위성에 영향을 미치고, 극한 강수 조건을 정확하게 예측할 수 없습니다.컬럼비아 대학의 LEAP 연구실은 전 세계 폭풍 분석 시뮬레이션과 머신 러닝을 사용하여 누락된 정보 문제를 해결하고 더 정확한 예측 방법을 제공하는 새로운 알고리즘을 개발했습니다.
해당 연구는 현재 PNAS에 게재되었으며, 논문 제목은 "대류 조직의 암묵적 학습이 강수 확률성을 설명한다"입니다.

해당 논문은 PNAS에 게재되었습니다.
논문 주소: https://www.pnas.org/doi/10.1073/pnas.2216158120#abstract
준비: 10일간의 날씨 데이터 + 2개의 신경망
데이터 및 처리
실험팀에서 사용한 데이터 세트는 다음과 같습니다.DYAMOND(비정수역학 도메인을 모델로 한 대기 일반 순환의 역학) 2단계 비교 프로젝트에서 시뮬레이션된 대기 순환 역학의 일부입니다. 이 프로젝트에서는 북반구의 40일간의 겨울을 시뮬레이션했습니다. 실험자들은 처음 10일을 모델의 스핀업으로 사용하고, 다음 30일 동안 무작위로 10일을 선택하여 훈련 세트로 사용했습니다.
연구자들은 적절한 데이터를 선택했습니다.이러한 데이터는 세분화되어 있으며 GCM 크기와 같거나 비슷한 그리드를 갖춘 하위 도메인으로 나뉩니다.
다음으로, 훈련, 검증, 테스트 데이터 세트를 제공하기 위해 팀은 10일을 각각 훈련, 검증, 테스트에 6일, 2일, 2일로 나누었습니다.강수량이 임계값(0.05mm/h)을 초과하는 샘플만 보존하여 강수 원인이 아닌 강수 강도에만 집중할 수 있도록 했습니다. . 최종적으로 총 샘플 수는 108개였습니다.
신경망 아키텍처
연구자들은 실험에서 두 가지 신경망을 사용했습니다.기존 모델인 Baseline-NN(Baseline Neural Network)과 새롭게 제안된 Org-NN .
Baseline-NN은 세대별로 학습률이 조정되는 완전히 연결된 피드포워드 네트워크입니다.기존 모델인 Baseline-NN은 대규모 변수에만 접근하여 강수량을 예측할 수 있습니다.
Org-NN에는 자동 인코더가 포함되어 있으며, 인코더 부분은 3개의 1차원 합성곱 계층과 2개의 완전 연결 계층을 포함합니다.. 인코더의 입력은 32 x 32 크기의 고해상도 PW(강수 가능 수위) 이상치이고, 출력은 org 변수입니다. org 차원은 네트워크의 하이퍼파라미터로, 연구자들은 이를 4로 설정했습니다. 디코더는 org 변수를 수신하고 인코더 구조의 반대인 원래의 고해상도 필드를 재구성합니다. Org-NN의 신경망 부분은 Baseline-NN과 유사하지만, 조직 잠재 변수(org)를 입력으로 추가한 점이 다릅니다. .
두 가지 모두 TensorFlow 버전 2.9를 사용하여 구현되었으며, 하이퍼파라미터는 Sherpa 최적화 라이브러리를 사용하여 조정되었습니다.
실험 결과
실험팀은 두 개의 모델을 사전 훈련시켰습니다.연구진은 신경망의 예측 성능을 평가하기 위해 회귀 모델의 성능을 정량화하는 데 일반적으로 사용되는 지표인 R2를 선택했습니다.. 계산 공식은 다음과 같습니다.
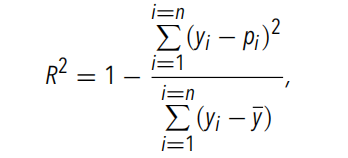
기존 모델 기준선-NN
실험팀은 먼저 Baseline-NN을 사용했습니다.아래 그림은 조립립 PW, SST, qv2m 및 T2m을 입력으로 사용할 때의 강수량 예측 가능성을 보여줍니다.. 이 중 qv2m과 T2m은 Baseline-NN에 경계층 조건 정보를 제공하는 데 사용됩니다. 실험팀은 조립질 PW를 그룹으로 나누고 각 그룹의 조립질 강수량의 예측값과 실제값을 평균화했습니다.각 그룹 내에서 조립질 강수량 값의 분산도 계산되었습니다..
비밀 번호: 침전 가능한 물
해수면 온도:해수면 온도, 해수면 온도
qv2: 표면 근처 비습도
티2m:지표면 부근의 대기 습도 2m, 표면 온도
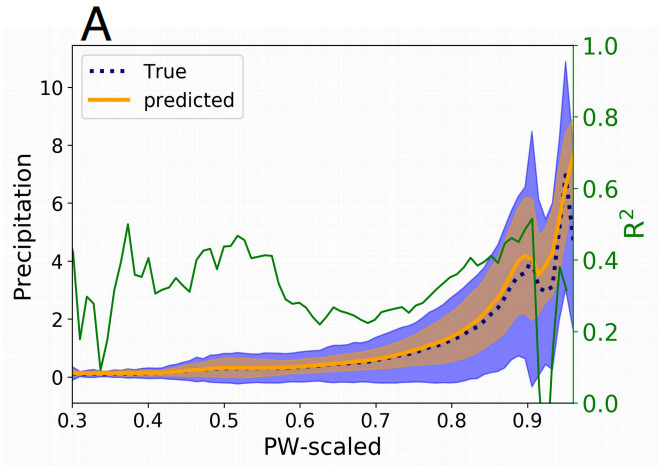
그림 1: PW 빈의 조립질 강수량 평균값
점선: 실제 평균 강수량
오렌지 라인: 예상 강수량 평균
그린 라인: 각 PW 빈에서 계산된 R2
그림자: 각 그룹 내의 분산
Baseline-NN은 PW 조건에서 강수량 평균(즉, 그룹의 평균)의 주요 동작을 정확하게 복구하고, 중요 지점 근처에서 발생하는 빠른 전환도 정확하게 복구합니다. 하지만,실험팀은 전 지구 폭풍 시뮬레이션에서 관찰된 강수량 변동성을 설명할 수 없다는 것을 발견했습니다.그리고 그 성능(모든 샘플의 R2 값으로 측정)은 약 0.45입니다. 낮은 R2 값은 다음을 나타냅니다.강수량의 일부 변동성은 파악할 수 있지만, 입력과 강수량 사이에 강력한 관련성은 발견할 수 없습니다.그리고 각 PW 빈에 대해 계산된 R2 값은 0.5를 초과하지 않았습니다.
동시에 실험팀은 Baseline-NN이 예측한 강수량의 확률밀도함수와 실제 강수량을 비교했습니다.이는 모델이 강수량 분포의 끝부분을 예측할 수 없다는 것을 보여줍니다. 즉, 극한 강수량을 예측할 수 없습니다..
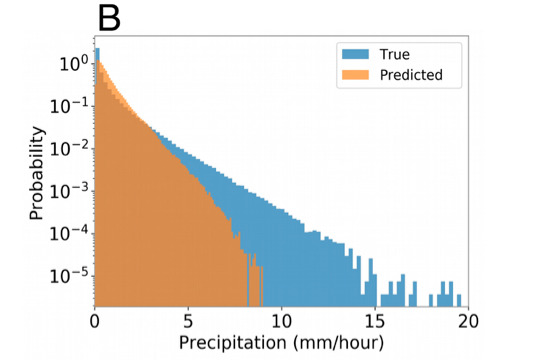
그림 2: 강수량 확률밀도함수의 개략도
파란색 부분: 실제 강수량의 확률 밀도 함수
오렌지색 부분: 예측 강수량의 확률 밀도 함수
연구자들은 또한 Baseline-NN을 추가로 테스트하기 위해 신경망에 대한 입력 중 하나로 전체 구름 덮개를 대략적인 수준으로 사용했습니다.. 총 구름 덮개는 기후 모델에서 매개변수화된 변수이며 강수량과 직접적인 관계가 없으므로 이를 신경망의 입력으로 사용하면 강수량의 매개변수화에 직접 사용되는 응축에 대한 단서를 제공할 수 있습니다. 실제로 이는 예보를 약간만 개선할 뿐, 평균 구름 덮개가 강수량을 정확하게 예측하는 데 필요한 정보를 제공하지 않는다는 점을 강조합니다. 또한, 실험팀은 추가 분석을 실시했습니다.CAPE와 CIN은 예측 인자로 사용할 수 없으며 예측 결과를 개선할 수 없다는 것이 확인되었습니다..
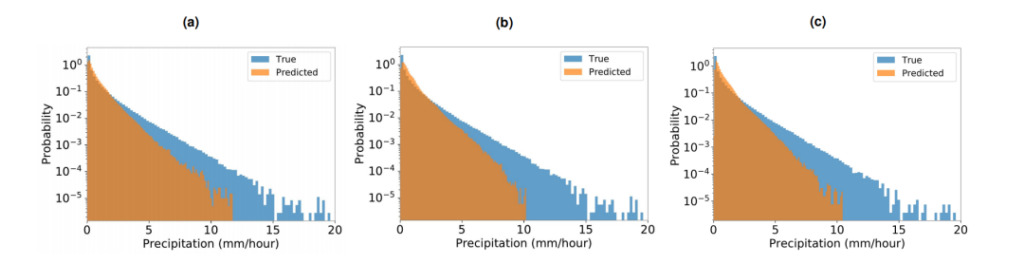
그림 3: 강수 확률 밀도 함수
파란색 부분: 실제 강수 확률 밀도 함수
오렌지색 부분: 강수 확률 밀도 함수를 예측합니다
에이: 입력은 [PW, SST, qv2m, T2m, 현열유속, 잠열유속]입니다.
비: 입력은 [PW, SST, qv2m, T2m, 총 구름 덮개]입니다.
기음: 입력은 [PW, SST, qv2m, T2m, CAPE, CIN]입니다.
결론은 Baseline-NN이 강수량과 변동성을 정확하게 예측하는 능력이 낮다는 것입니다..
새로운 모델 Org-NN
실험팀은 기존 방법을 뒤집어 Org-NN을 예측에 사용했습니다. Org-NN은 자동 인코더를 포함하고 있으므로 역전파를 통해 신경망의 목적 함수로부터 직접 피드백을 받을 수 있습니다.따라서 자동 인코더는 강수량 예측을 개선하기 위해 관련 정보를 수동으로 추출할 수 있습니다..
아래 그림은 org를 입력으로 하고 거친 변수로 구성된 Org-NN의 강수량 예측 결과를 보여줍니다. Baseline-NN과 비교했을 때 Org-NN은 상당한 진전을 이루었습니다.. 모든 데이터 포인트에 대해 계산하면 예측된 R2는 0.9로 증가합니다. 강수량이 적은 구간을 제외한 PW의 각 구간에 대해 계산된 R2 값은 0.80에 거의 가깝습니다.
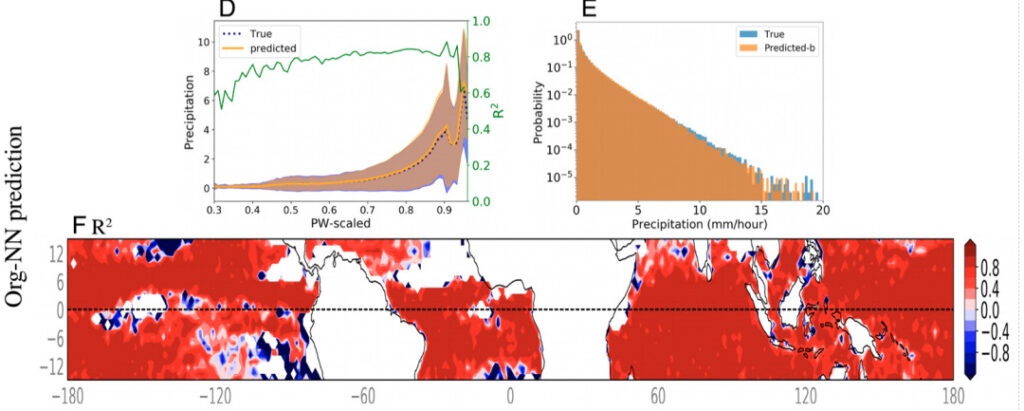
그림 4: Org-NN 예측 결과
디: PW bin의 조립질 강수량 평균값
이자형:강수량 확률밀도함수의 개략도
에프: 그림 D의 각 위도 및 경도 위치에 대한 시간 단계에 걸쳐 계산된 R2 값입니다. 그림의 흰색 영역은 강수량이 0.05mm/h 미만임을 나타내며 모델 입력에서 제외되었습니다. 강수량 한계점에 도달하지 못한 지점 근처 지역을 제외하고 대부분 지역에서 Org-NN의 R2 값이 0.8보다 유의하게 높았습니다.
실험팀은 Org-NN의 실제 강수량과 고해상도 강수량 모델의 확률 밀도 함수를 비교하여 Org-NN의 성능을 더욱 정량화했습니다. Org-NN은 극한 강수량에 해당하는 분포의 끝부분을 포함하여 확률 밀도 함수를 완벽하게 포착하는 것으로 나타났습니다.이는 Org-NN이 극한 강수량을 정확하게 예측할 수 있음을 보여줍니다..
실험팀이 얻은 결과에 따르면, org를 입력에 통합함으로써 강수량 예측이 크게 개선된다는 것이 밝혀졌습니다. 이는 하위 격자 규모 구조가 현재 기후 모델의 대류 및 강수 매개변수화에서 누락된 중요한 정보일 수 있음을 시사합니다..
실험 과정 요약
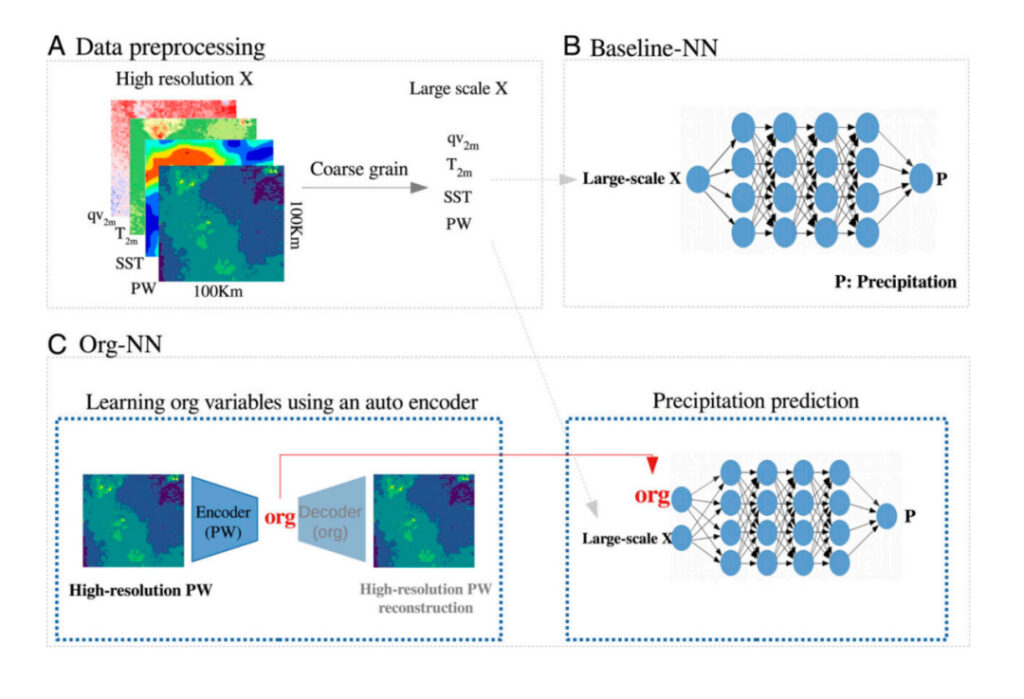
그림 5: 실험 과정 개요
에이:데이터 처리 프로세스: 거친 입자 고해상도 데이터
비: 기준 NN: 이 네트워크는 대략적인 변수(SST 및 PW 등)를 입력으로 받고 대략적인 강수량을 예측합니다.
기음:Org-NN : 왼쪽 그림은 고해상도 PW를 입력으로 받고 병목 지점을 통과한 후 재구성하는 자동 인코더를 보여줍니다. 오른쪽 그림은 거친 규모의 강수량을 예측하는 신경망을 보여줍니다.
기존 기후 모델이 변화하고 있습니다
이 실험을 위한 팀은 다음에서 왔습니다. 인공지능과 물리학을 활용한 지구 학습(LEAP)2021년 컬럼비아 대학교가 출범시킨 NSF 과학기술센터이 연구소의 주요 연구 전략은 물리적 모델링과 머신 러닝을 결합하여 기후 과학과 기후 시뮬레이션 분야의 전문 지식과 최첨단 머신 러닝 알고리즘을 활용하여 단기 기후 예측을 개선하는 것입니다.. 이는 기후 과학과 데이터 과학 모두에 도움이 될 것입니다.

LEAP Lab 멤버에 대한 간략한 소개
|연구소 공식 홈페이지: https://leap.columbia.edu
연구자들은 현재 머신 러닝 접근 방식을 기후 모델에 적용하고 있습니다.강수 강도 및 변동성에 대한 예측을 개선하고 과학자들이 지구 온난화의 맥락에서 물 순환 및 극한 기상 패턴의 변화를 보다 정확하게 예측할 수 있도록 합니다..
동시에 이 연구는 강수에 기억 효과가 있을 가능성을 탐구하는 등 새로운 연구 방향을 제시합니다. 즉, 대기가 최근 날씨 상황에 대한 정보를 유지하여 이후의 대기 상황에 영향을 미칠 수 있다는 것입니다. 이 새로운 방법은 강수 시뮬레이션을 넘어 빙상과 해양 표면에 대한 더 나은 시뮬레이션과 같은 광범위한 분야에 적용될 수 있습니다.
본 기사는 HyperAI WeChat 공개 플랫폼에 처음 게재되었습니다~