Command Palette
Search for a command to run...
AI는 본격적인 '광산' 산업에 관여하고 있습니다. 카네기 과학 연구소는 다른 접근 방식을 취하고 상관관계 분석을 사용하여 새로운 광물 매장지를 찾았습니다.

내용을 한눈에 보기:광물은 기술 사회에 중요한 원자재를 제공하며 많은 지질학적 사건과 고대 환경에 대한 유일한 증거입니다. 수세기 동안 광물 자원에 대한 탐색과 그 기원 및 분포의 근본 원인을 밝히는 것이 지질학의 주요 관심사였습니다. 최근 미국 국립과학원 회보의 자회사인 PNAS Nexus는 기계 학습 모델을 사용하여 광물 연관 분석을 통해 새로운 광물 매장지의 위치와 유형을 예측하는 연구 결과를 발표했습니다.
키워드:머신러닝 상관관계 분석 광물 탐사
본 기사는 HyperAI WeChat 공개 플랫폼에 처음 게재되었습니다~
광물은 수십억 년 전에 나타났으며 생명의 진화에 중요한 역할을 해왔습니다. 현재 지질산업에는 다양한 탐사기술이 있지만, 광물자원은 숨겨져 있고 불확실한 경우가 많습니다.광물 탐사 과정은 매우 복잡합니다.동시에, 광물 탐사는 높은 위험, 긴 투자 주기, 낮은 성공률 등 많은 어려움에 직면해 있습니다.
과거 연구에 따르면, 과학자들은 지구상에 존재하는 5,000개 이상의 광물이 무작위로 분포되어 있지 않다는 사실을 발견했습니다.많은 종들이 공생 관계(상생)로 존재합니다.소위 공생관계는 특정한 물리적, 화학적 법칙에 따라 형성된 광물 조합입니다. 예를 들어, 광물의 형성은 모암의 화학적 구성 및 환경 조건과 밀접한 관련이 있습니다.
최근, 워싱턴 카네기 과학 연구소의 모리슨 샤우나 M은 애리조나 대학의 프라부 아니루드와 다른 연구자들과 함께 기계 학습을 사용하여 광물의 조합 규칙을 발견하고 광물의 위치를 예측했습니다. 해당 연구 결과는 PNAS Nexus 저널에 게재되었습니다.제목은 "광물 연관 분석을 통한 새로운 광물 발생 및 행성 유사 환경 예측"입니다.

연구 결과는 다음에 게재되었습니다.PNAS 넥서스"우수한
서류 주소:
https://academic.oup.com/pnasnexus/article/2/5/pgad110/7163824?login=true
실험 개요
연구진은 광물 진화 데이터베이스의 데이터를 사용하여 연관 규칙에 따라 광물 위치를 예측하는 머신 러닝 모델을 개발하고, 화성과 유사한 환경으로 잘 알려진 테코파 분지에서 이 모델을 테스트했습니다. 실험 결과에 따르면 머신러닝은 광물의 위치, 종류, 양을 효과적으로 예측할 수 있는 것으로 나타났습니다.
연관성 분석은 머신 러닝 방법입니다.데이터 세트에서 연관 규칙과 패턴을 발견하는 데 사용됩니다.데이터 내 항목 집합 간의 연관성을 분석하여 서로 다른 항목 집합 간의 상관관계와 종속성을 보여줍니다.
저자들은 올바른 데이터가 주어지면 광물 조합 분석을 사용하여 새로운 매장지의 위치와 광물의 종류뿐만 아니라 주어진 장소에 존재하는 광물의 양을 예측할 수 있다고 제안합니다. 그리고 이 모델은 지구에만 적용되는 것이 아니라, 암석으로 이루어진 모든 행성체에도 적용됩니다.
데이터세트
이 연구를 위한 데이터 세트에는 5,478개의 광물, 295,583개의 광물 지역, 그리고 810,907개의 광물-지역 조합을 포함하는 대규모 광물 진화 데이터베이스에서 가져온 5,472개의 광물 지역의 관련 연대 정보가 포함되어 있습니다. 연구자들은 데이터의 규모가 크기 때문에 이를 여러 하위 집합으로 나누고 그 중 3개를 선택했습니다.
* 지리적 하위 집합:연구진은 광물 다양성이 높고, 지리적 범위가 넓고 잘 기록되어 있으며, 지질학적 환경이 매우 다양한 미국을 선택했습니다. 이 하위 집합에는 2,622개의 광물 종, 93,419개의 광물 발생, 8,139,004개의 연관 규칙이 포함되어 있습니다.
* 지구화학 하위 집합:연구진은 우라늄 광석을 선택하고 U를 기본 원소로 하는 하나 이상의 광물 종을 분석하여 우라늄을 함유하는 광물상을 조사했습니다. 이 하위 집합에는 5,439개의 광물, 11,729개의 광물 발생, 60,589,982개의 연관 규칙이 포함되어 있습니다.
* 시간 부분 집합:연구자들은 원생대(25억 년 이상), 원생대(25억 ~ 05억 4천만 년), 신생대(05억 4천만 년 미만)의 세 가지 시간대를 선택했습니다.
모델 개발
연구자들은 위의 데이터 세트를 바탕으로 모델을 개발하고 그 효과를 검증하기 시작했습니다.전체 과정은 3단계로 나뉩니다.
1. 광물 결합 규칙 생성
연구진은 연관성 분석에 일반적으로 사용되는 Apriori 알고리즘을 사용했습니다. 이 알고리즘은 자주 동시에 발생하는 항목(예: 광물 조합) 세트를 테스트하고 비교하여 연관 규칙을 생성하는 하향식 접근 방식을 채택하며, 이는 광물 연관 분석에 사용될 수 있습니다.
2. 광물결합규칙의 가능성 측정
연구자들은 요구 사항을 충족하는 연관 규칙을 걸러내기 위해 가능성 지수를 설정했습니다. 가능성 지표란 광물 간의 관계를 정량화하고 평가하는 지표를 말합니다. 일반적인 가능성 지표로는 지지, 신뢰도, 상승세가 있습니다.
지지도는 모든 샘플 중 두 가지 이상의 미네랄을 동시에 포함하는 비율을 말합니다.지지도가 높을수록 이들 광물 간의 연관성이 강해진다.

그림 2: 지지 계산 공식
신뢰도는 한 광물이 발생할 때 다른 광물도 발생할 확률을 말합니다.높은 신뢰 수준은 두 광물 사이에 강력한 연관성이 있음을 나타냅니다.

그림 3: 신뢰도 계산 공식
고도는 두 광물이 함께 발생할 확률과 두 광물이 독립적으로 발생할 확률의 비율입니다.1보다 큰 리프트는 두 광물 사이에 긍정적인 연관성이 있음을 나타내고, 1보다 작은 리프트는 부정적인 연관성이 있음을 나타내며, 1은 연관성이 없음을 나타냅니다.

그림 4: 리프트 계산 공식
3. 광물 예측을 위한 광물 연합 규칙
이 연구에서 연구진은 기존의 광물 데이터를 조사하고 분석하여 세 가지 데이터 하위 집합(지리적, 지구화학적, 시간적) 각각에 대한 연관 규칙을 생성했습니다. 그들은 연관 규칙을 사용하여 예측 대상 위치에서 광물의 발생을 분석하고 비교하며, 어느 위치에서나 광물 유형, 광물 조합, 광화 환경 등을 예측할 수 있습니다.
실험 결과
실험은 미국 캘리포니아주의 테코파 분지에서 수행되었습니다. 이 지역에는 화산재와 트라버틴 퇴적물이 포함되어 있고, 근처에 화성 환경을 시뮬레이션할 수 있는 현무암 용암류가 있기 때문입니다.연구자들은 해당 유적지에서 발견될 광물의 종류를 예측했습니다.다음 표에서 볼 수 있듯이:
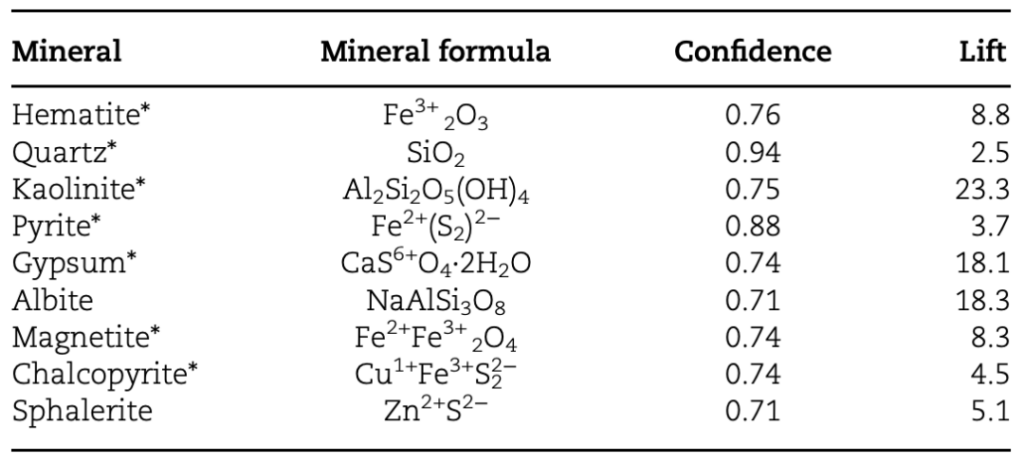
표 1: 테코파 분지에서 발생할 것으로 예상되는 광물 종
표는 예측의 기반이 되는 연관 규칙에 대한 관련 신뢰도 및 리프트 지표를 보여줍니다.
연구진은 또한 우라늄과 기타 주요 광물이 어디에 나타날지 예측하고 지도에 예측 결과를 표시했습니다.우라늄 광산 예측 위치의 결과는 아래 그림과 같습니다.이 중 일부 예측은 2020년 10월 이후 확정되었으며, 이는 광물상관분석의 예측력을 입증합니다.

그림 5: 예상 우라늄 매장지 위치 지도
다른 주요 광물 몇 가지의 예상 위치는 아래 그림에 표시되어 있습니다.

그림 6: 기타 주요 광물의 예측된 지리적 위치
2021년 10월 현재,확인된 위치에는 Mindat 로고가 표시됩니다. 민닷은 글로벌 광물 데이터베이스 웹사이트입니다. 특정 장소에서 광물이 발견되면 웹사이트에 공개됩니다.
또한 연구진은 지구 역사에서 광물 외관의 변화를 더 잘 이해하기 위해 원생대(25억 년 이상), 원생대(25억-05억 4천만 년), 신생대(05억 4천만 년 미만)를 포함한 선택된 시기에 대한 광물 연관 규칙을 연구했습니다. 세 가지 기간 동안 미네랄 조합의 개선은 아래 그림과 같습니다.
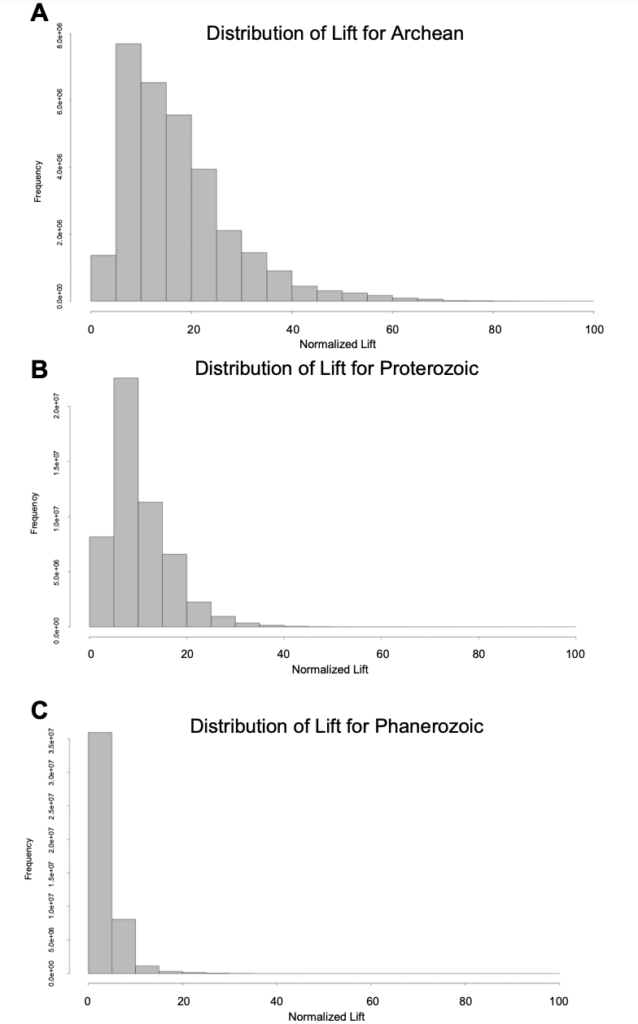
그림 7: 원생대(a), 원생대(b), 신생대(c) 광물 조합 고도
고도의 정도는 광물 조합 간의 연관 강도를 나타내며, 원생대, 원생대, 신생대의 광물 조합 분포에 확실한 차이가 있음을 알 수 있습니다. 이 규칙은 향후 연구에 활용될 수 있습니다.환경과 기후 등 다양한 요소가 광물 조합에 미치는 영향을 더 자세히 살펴보세요.
요약하자면, 광물 연관 분석은 새로운 광물 유형과 목표 광물 위치를 예측하는 데 적용될 수 있습니다.
연관성 분석: 정보 마이닝에서 가장 활발한 방법 중 하나
연관 분석(Association Analysis)은 연관 마이닝(Association Mining)이라고도 불리며 데이터 정보 마이닝 분야에서 가장 활발하게 연구되는 방법 중 하나이며 1993년에 처음 제안되었습니다. 본 논문의 저자들은 논의 부분에서 다음과 같이 제안했습니다.연관 분석의 적용은 광물 조합에만 국한되어서는 안 됩니다.또한 공생 화석, 미생물, 분자, 지질 환경 등 다른 특성을 분석하는 데에도 적용할 수 있습니다. 이 방법은 확장성과 전환성이 뛰어나고, 다양한 분야에 적용 가능하며 중요한 역할을 할 수 있기 때문입니다.
본 논문에서 논의된 광물 탐사에서의 상관 분석 적용 외에도,인간, 동물, 식물 유전학 연구 분야에서의 진전도 주목할 만합니다.현재 이 분야의 연구자들은 연관성 분석을 기반으로 한 일련의 새로운 방법과 소프트웨어를 제안했습니다. 예를 들어, 이전에 대중에게 공개된 PLINK 소프트웨어는 데이터 관리, 인구 구조 평가, 복합 형질 및 사례 대조 데이터의 연관 분석에 사용할 수 있으며 유전형 및 표현형 빅데이터도 처리할 수 있습니다. 저장대학의 주쥔 교수 연구실에서 개발한 QTXNetwork는 대규모 복합형질 오믹스 데이터를 처리할 수 있는 GPU 컴퓨팅 기반의 연관성 분석 소프트웨어 패키지입니다.
데이터의 양이 계속 늘어나고, 컴퓨터 과학과 기술, 통계 알고리즘이 계속 업데이트됨에 따라 다양한 분야에서 연관성 분석을 적용하는 방식이 더욱 발전할 것입니다.또한, 효율적이고 빠르며 대량으로 라벨링된 새로운 연관성 분석 기술 플랫폼도 등장할 것입니다.이러한 맥락에서 팀과 개인이 도구를 선택할 때 실제 비즈니스 요구 사항을 기반으로 도구를 평가하고 비교해야 합니다.
참조 링크:
[1]https://www.doc88.com/p-9788189626622.html?
[2]https://zwxb.chinacrops.org/article/2016/0496-3490-42-7-945.html
본 기사는 HyperAI WeChat 공개 플랫폼에 처음 게재되었습니다~