Command Palette
Search for a command to run...
Sim Computing: TVM 기반 DSA AI 컴파일러 빌드

안녕하세요 여러분, 저는 Shim Computing의 댄 샤오치앙입니다. 오늘은 저와 동료 3명이 TVM에서 NPU를 지원하는 방법을 알려드리겠습니다.
DSA 컴파일러가 해결하는 본질적인 문제는 다양한 추상 수준에서 최적화 방법을 사용하여 하드웨어에 다양한 모델을 배포하여 모델이 칩을 최대한 채우도록 해야 한다는 것입니다. 즉, 버블을 압축해야 합니다. 스케줄링 방법과 관련해서, Halide가 설명한 스케줄링 삼각형이 문제의 본질입니다.
DSA 컴파일러가 해결하는 주요 문제는 무엇입니까? 먼저, DSA 아키텍처를 추상화합니다. 그림에서 볼 수 있듯이 Habana, Ascend, IPU는 모두 이 추상 아키텍처의 인스턴스입니다. 일반적으로 각 코어에는 벡터, 스칼라, 텐서 컴퓨팅 유닛이 있습니다. 명령어 작업과 데이터 세분성의 관점에서 볼 때, 많은 DSA는 2차원 및 3차원 벡터와 텐서 명령어와 같이 비교적 거친 명령어를 사용하는 경향이 있습니다. 1차원 SIMD나 VLIW와 같이 세분화된 명령어를 사용하는 하드웨어도 많이 있습니다. 명령어 간의 일부 종속성은 소프트웨어 제어를 위한 명시적 인터페이스를 통해 노출되지만, 다른 종속성은 하드웨어 자체에 의해 제어됩니다. 메모리는 다중 레벨 메모리이며, 대부분 스크래치패드 메모리입니다. 컴퓨팅 구성 요소 간에는 스트림 병렬 처리, 클러스터 병렬 처리, 멀티 코어 병렬 처리, 파이프라인 병렬 처리 등 다양한 세분성과 차원의 병렬 처리가 있습니다.
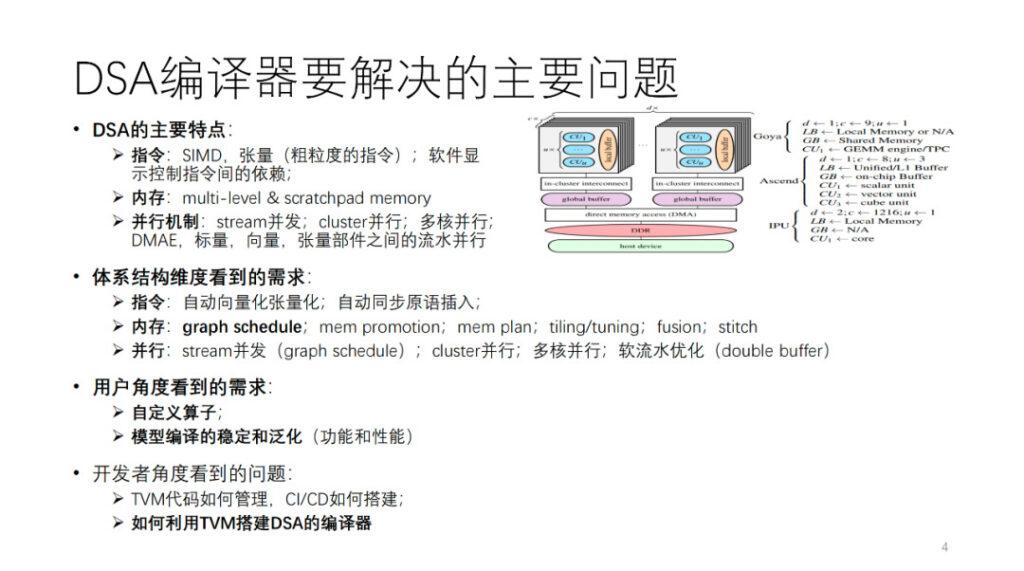
이러한 유형의 아키텍처를 지원하기 위해 컴파일러 개발자의 관점에서 볼 때, 위에 언급된 아키텍처의 여러 측면에서 AI 컴파일러에 대한 다양한 요구 사항이 제시됩니다. 이 부분에 대해서는 나중에 자세히 설명하겠습니다.
사용자 관점에서 볼 때, 우선 가능한 한 많은 모델이나 연산자를 성공적으로 컴파일할 수 있는 안정적이고 일반화된 컴파일러가 있어야 합니다. 또한 사용자들은 컴파일러가 알고리즘과 연산자를 사용자 정의할 수 있는 프로그래밍 가능한 인터페이스를 제공하여 일부 주요 알고리즘 혁신 작업을 독립적으로 수행할 수 있기를 바랍니다. 마지막으로, 저희나 경쟁사와 같은 팀은 TVM을 사용하여 AI 컴파일러를 구축하는 방법, 자체 개발한 오픈 소스 TVM 코드를 관리하는 방법, 효율적인 CI를 구축하는 방법 등에 대해 고민할 수도 있습니다. 오늘은 이러한 내용을 공유하고자 합니다. 이제 동료가 컴파일 최적화 부분에 대해 이야기하겠습니다.
Shim Computing의 Wang Chengke: DSA 컴파일 최적화 프로세스
이 부분은 Shim의 컴퓨팅 엔지니어인 왕 청커가 현장에서 공유했습니다.
먼저 심씨의 편찬 실무의 전반적인 과정을 소개해드리겠습니다.
위에서 언급한 아키텍처적 특징에 대응하여, 우리는 TVM 데이터 구조를 기반으로 자체 개발한 최적화 패스를 구축하고 TVM을 재사용하여 새로운 모델 구현인 tensorturbo를 형성했습니다.
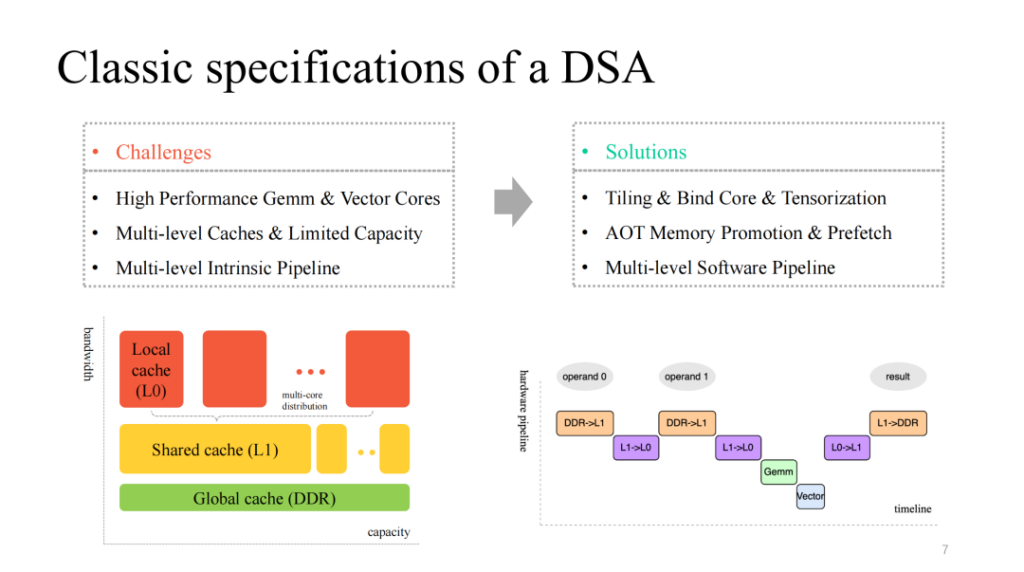
우리는 일반적으로 효율적이고 사용자 정의된 매트릭스 및 벡터 계층 멀티코어 컴퓨팅 코어를 제공하고, 이에 맞는 멀티 계층 캐시 메커니즘을 갖추고 있으며, 병렬로 실행될 수 있는 멀티 모듈 실행 단위를 제공하는 비교적 고전적인 DSA 아키텍처를 볼 수 있습니다. 따라서 우리는 다음과 같은 문제를 다루어야 합니다.
- 데이터 계산을 분할하고, 코어를 효율적으로 바인딩하고, 맞춤형 지침을 효율적으로 벡터화합니다.
- 제한된 온칩 캐시를 세밀하게 관리하고 다양한 캐시 레벨에서 데이터를 사전 페치합니다.
- 여러 모듈이 실행하는 다단계 파이프라인을 최적화하고, 더 나은 가속 비율을 얻기 위해 노력합니다.
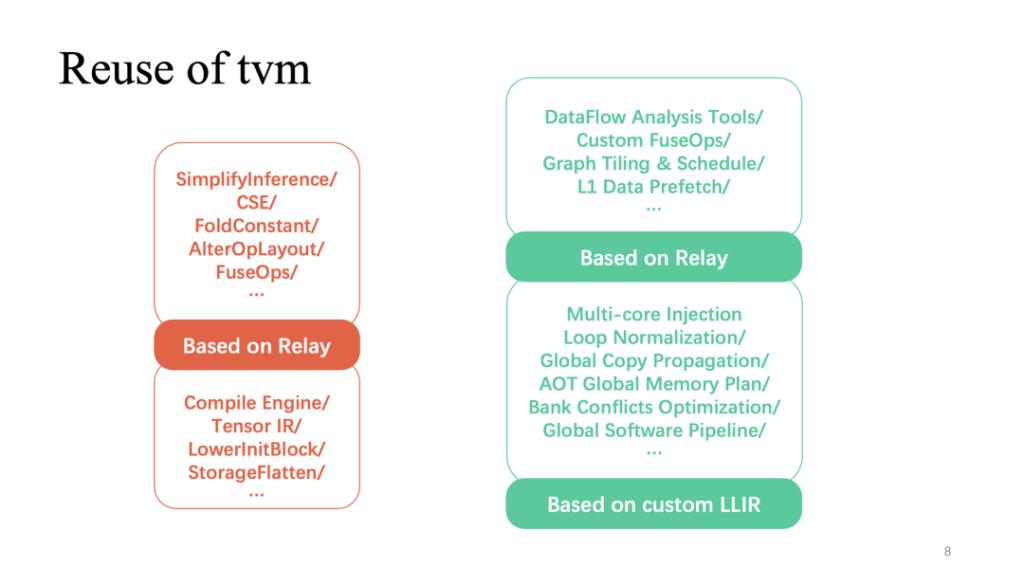
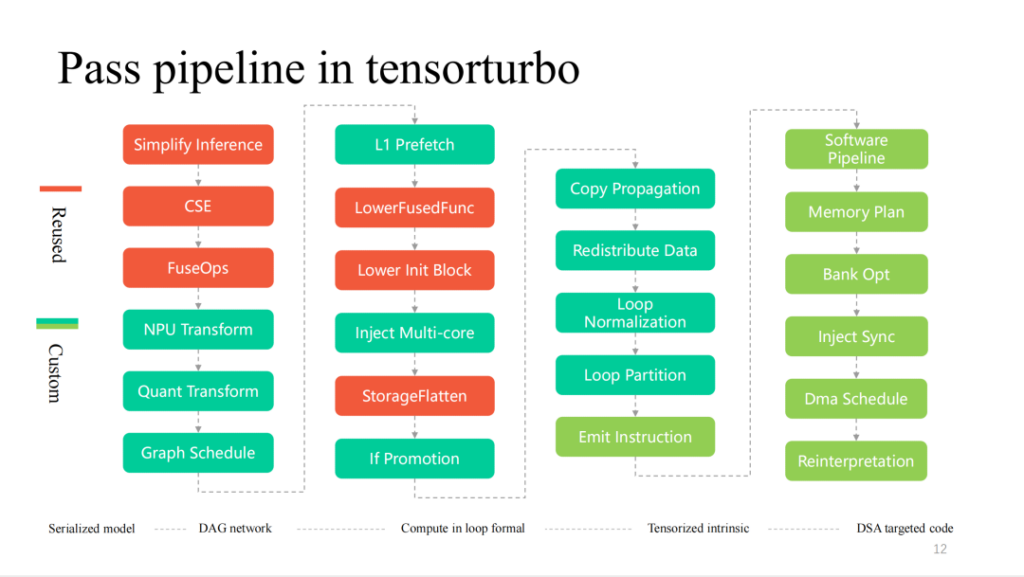
위의 빨간색 부분은 전체 프로세스에서 TVM 재사용률이 가장 높은 부분을 보여줍니다. 릴레이에 구현된 보다 일반적인 계층 관련 최적화는 바로 재사용될 수 있습니다. 또한 TensorIR과 사용자 정의 LLIR을 기반으로 한 연산자 구현도 매우 재사용성이 높습니다. 앞서 언급했듯이 하드웨어 기능과 관련된 맞춤형 최적화에는 더 많은 자체 조사 작업이 필요합니다.
먼저, 레이어에 대한 자체 개발 작업을 살펴보겠습니다.
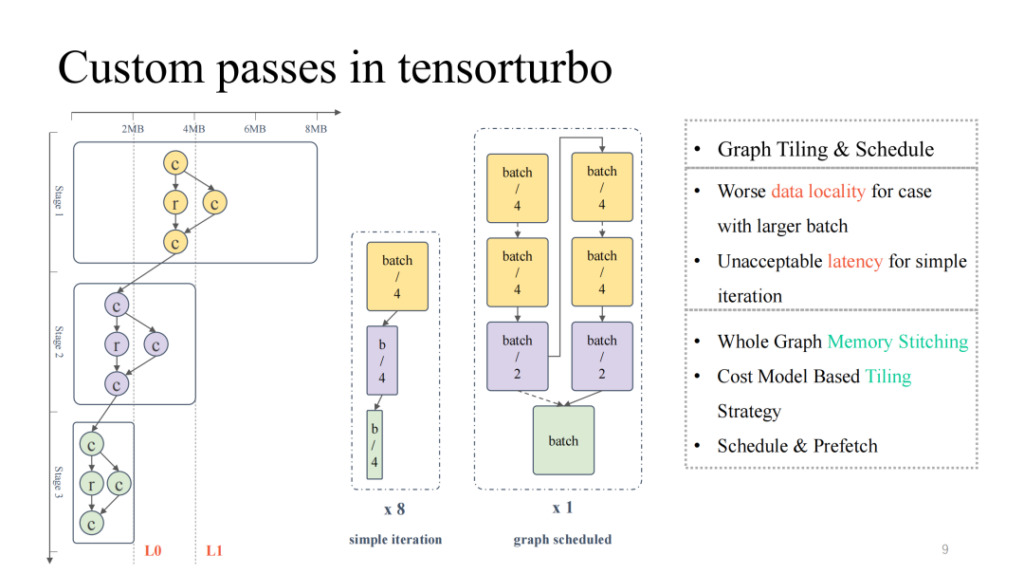
가장 왼쪽에 있는 보다 일반적인 컴퓨팅 흐름도를 살펴보면, 위에서 아래로 전체 캐시 점유율과 컴퓨팅 점유율이 끊임없이 감소하여 역피라미드 상태를 나타내는 것을 볼 수 있습니다. 전반부에서는 모델 크기가 클 경우 칩 내부 캐시 상주 문제를 해결하는 데 집중해야 합니다. 반면, 후반부에서는 모델 크기가 작기 때문에 컴퓨팅 장치 활용도가 낮은 문제를 해결해야 합니다. 배치 크기를 조정하는 것처럼 단순히 모델 크기를 조정하면 배치 크기가 작아져 지연 시간은 줄어들지만, 해당 처리량은 감소합니다. 마찬가지로, 배치 크기가 커지면 지연 시간은 늘어나지만 전체 처리량은 향상될 수 있습니다.
그러면 그래프 스케줄링을 사용해 이 문제를 해결할 수 있습니다. 첫째, 프로세스 전반에 걸쳐 계산 활용도를 비교적 높게 보장하기 위해 비교적 큰 배치 크기를 입력할 수 있습니다. 그런 다음 전체 그래프에 대한 저장 분석을 수행하고 분할 및 스케줄링 전략을 추가하여 모델의 전반부 결과를 칩에 더 잘 캐싱하는 동시에 컴퓨팅 코어의 활용도를 높일 수 있습니다. 실제로 지연 시간과 처리량 모두에서 좋은 결과를 얻을 수 있습니다(자세한 내용은 6월에 발표될 OSDI 23 Shim의 논문 "Effectively Scheduling Computational Graphs of Deep Neural Networks toward Their Domain-Specific Accelerators"를 참조하세요).
다음은 연수 흐름의 또 다른 가속 작업입니다.
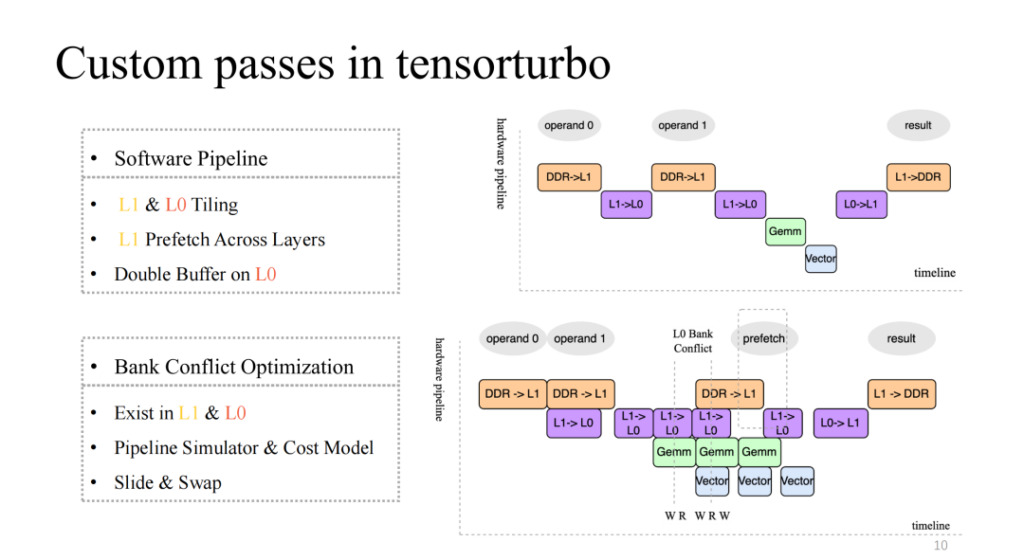
비교적 기본적인 4단계 파이프라인을 구현한 오른쪽 위 그림을 주의 깊게 살펴보세요. 하지만 분명 효율적인 파이프라인은 아닙니다. 일반적으로 효율적인 파이프라인은 여러 번의 반복을 거친 후 4개의 실행 단위를 동기화하고 병렬화할 수 있어야 합니다. 여기에는 L1 및 L0에서의 분할, L1에서의 계층 간 데이터 사전 페칭, L0 수준에서의 이중 버퍼 작업 등의 작업이 필요합니다. 이 작업을 통해 우리는 오른쪽 아래 그림에 표시된 것처럼 상대적으로 높은 가속도를 가진 파이프라인을 구현할 수 있습니다.
이로 인해 새로운 문제가 발생합니다. 예를 들어, 여러 실행 단위의 캐시에 대한 동시 읽기 및 쓰기 동시성 수가 현재 캐시가 지원하는 동시성보다 높을 경우 경쟁이 발생합니다. 이 문제는 메모리 접근 효율성이 기하급수적으로 떨어지게 만드는데, 이것이 바로 은행 충돌 문제입니다. 이 문제를 해결하기 위해 컴파일 시점에 파이프라인을 정적으로 시뮬레이션하고, 충돌하는 객체를 추출하고, 비용 모델을 사용하여 할당된 주소를 스왑 및 이동하면 이 문제의 영향을 크게 줄일 수 있습니다.
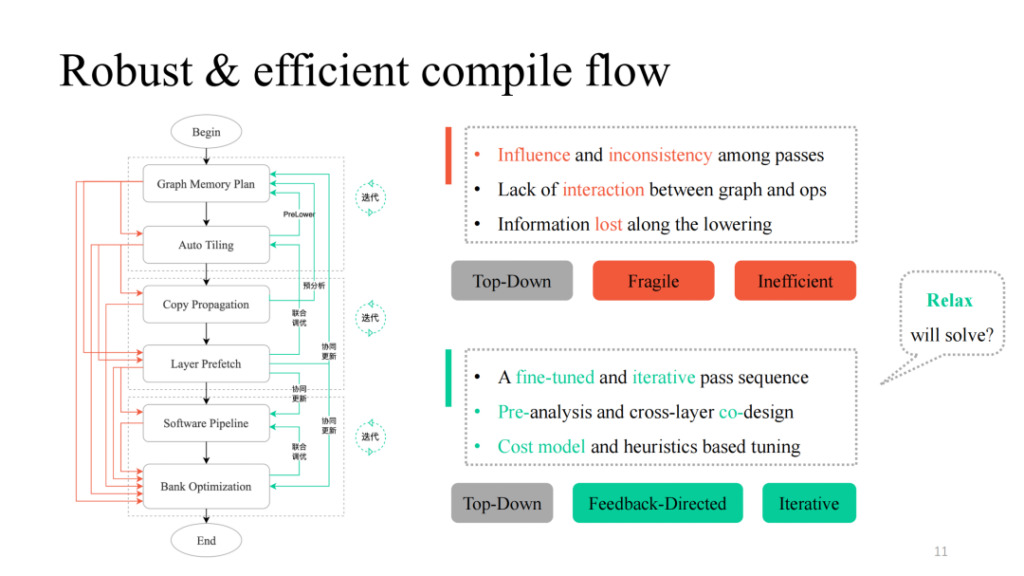
다양한 패스를 거친 후, 간단한 상향식 방식으로 이를 결합할 수 있습니다. 왼쪽 그림의 검은색 프로세스를 따르면 기능적으로 실행 가능한 컴파일 파이프라인을 얻을 수 있습니다. 그러나 실제로는 시위안이 언급한 패스 간의 상호 영향, 상호작용 논리의 부재, 계층과 운영자 간의 소통 논리의 부재 등 많은 문제점이 발견되었습니다. 왼쪽 그림의 빨간색 부분이 그 과정을 나타낸 것입니다. 실제로는 각 경로 또는 각 경로의 조합이 컴파일 실패를 유발하는 것으로 나타났습니다. 더욱 견고하게 만들려면 어떻게 해야 하나요? Shim은 실패할 수 있는 각 패스에서 피드백 경로를 제공하고, 계층과 연산자 간에 대화형 논리를 도입하고, 사전 분석 및 사전 낮추기 작업을 수행하며, 핵심 부분에 일부 반복적 튜닝 메커니즘을 도입하여 궁극적으로 높은 일반화와 강력한 튜닝 기능을 갖춘 전체 파이프라인 구현을 얻습니다.
또한 위 작업에서 데이터 구조의 변형과 관련된 디자인 아이디어가 현재의 TVM Unity 디자인과 많은 유사점을 가지고 있다는 것을 발견했습니다. 또한 Relax가 더 많은 가능성을 가져다 줄 것으로 기대합니다.
Xim의 컴파일 과정에 대한 더 자세한 내용은 다음과 같습니다. 왼쪽에서 오른쪽으로 겹겹이 감소하는 과정입니다. 빨간색 부분은 TVM에서 매우 많이 재활용됩니다. 하드웨어 기능에 가까울수록 더욱 맞춤화된 패스가 제공됩니다.
다음은 일부 모듈에 대한 자세한 소개입니다.
Sim Computing Liu Fei: DSA의 벡터화 및 텐서화
이 부분은 Shim의 컴퓨팅 엔지니어인 Liu Fei가 현장에서 공유했습니다.
이 장에서는 Shim 벡터화와 텐서 양자화의 작업을 소개합니다. 명령어 세분성의 관점에서 보면 명령어 세분성이 거칠수록 Tensor IR의 다층 루프 표현에 가까워지므로 벡터화된 텐서 양자화의 어려움이 덜합니다. 오히려 지시의 세분성이 높을수록 어려움은 커집니다. NPU 명령어는 1차원/2차원/3차원 텐서 데이터 계산을 지원합니다. 심은 또한 네이티브 TVM 텐서화 프로세스를 고려했지만, 컴퓨트 텐서화의 복잡한 표현식을 표현하는 데 있어 제한된 능력을 고려할 때, if 조건과 같은 복잡한 표현식을 텐서화하는 것이 어렵고, 텐서화 벡터화 후에는 스케줄링이 불가능합니다.
또한, 당시 TensorIR Tensorize는 개발 중이어서 개발 요구를 충족할 수 없었기 때문에 Shim은 명령어 방출이라고 부르는 자체적인 명령어 벡터화 프로세스 세트를 제공했습니다. 이 프로세스에서는 다양한 차원의 명령어를 포함하여 약 120개의 텐서 명령어를 지원합니다.

우리의 교육 흐름은 대략 세 가지 모듈로 나뉩니다.
- 출시 전 최적화. 사이클 축의 변환은 명령 발행을 위한 더 많은 조건과 가능성을 제공합니다.
- 명령 전송 모듈. 루프의 결과와 정보를 분석하여 최적의 명령어 생성 방법을 선택합니다.
- 명령이 내려진 후의 모듈입니다. CPU에서 올바른 실행을 보장하지 못한 후 지정된 전송을 처리합니다.
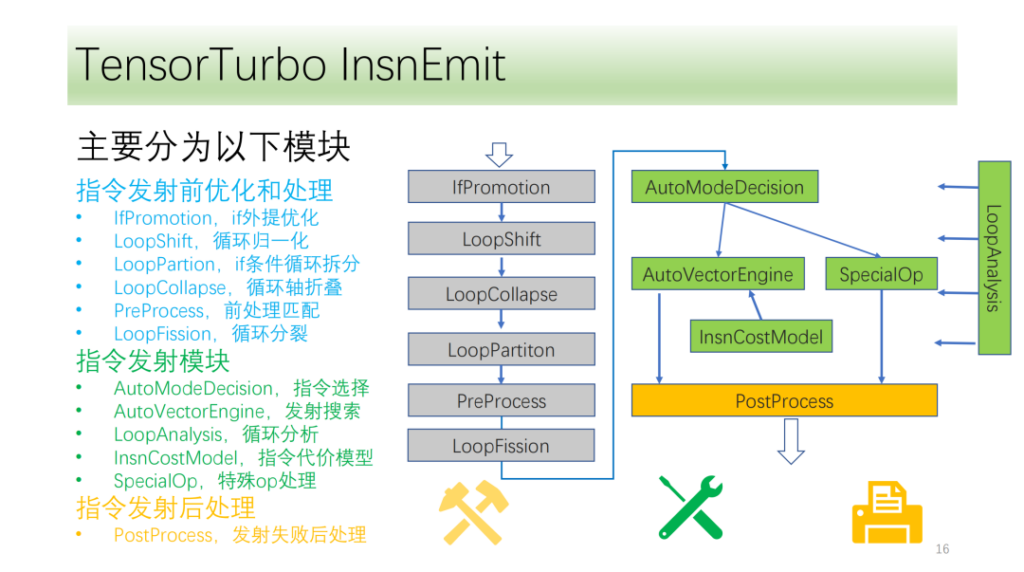
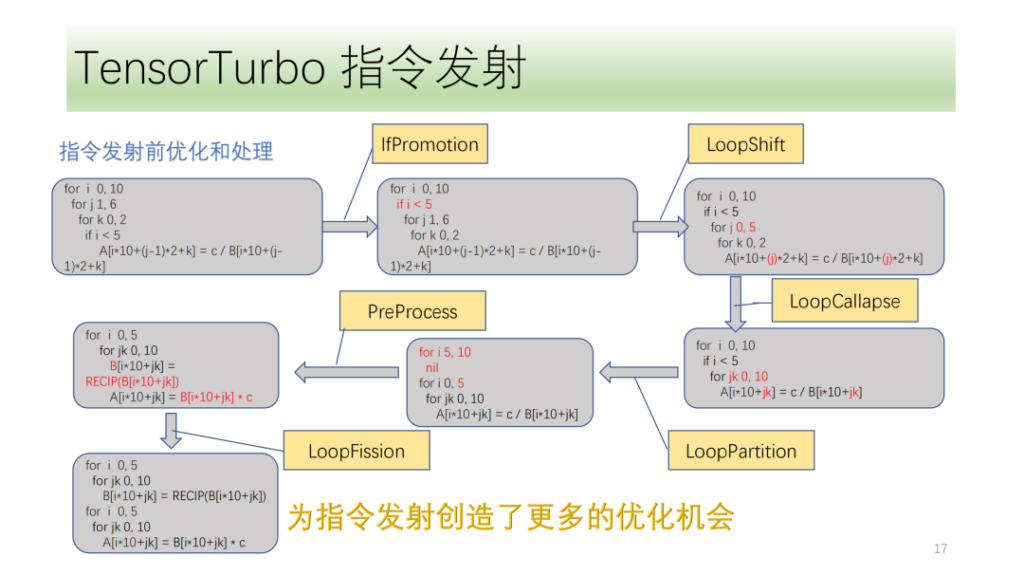
아래는명령 발행 전 최적화 및 처리 모듈이러한 모든 것은 최적화 패스 세트로 구성되어 있으며, IfPromotion은 루프 축의 출력을 방해하는 if 문을 최대한 제거하고, PreProcess는 해당 명령어가 없는 연산자를 분할하고, LoopShift는 루프 축 경계를 정규화하고, LoopCallapse는 연속된 루프 축을 최대한 병합하고, LoopPartition은 if와 관련된 루프 축을 분할하고, LoopFission은 루프에서 여러 store 문을 분할합니다.
이 예에서 우리는 IR이 처음에는 아무런 명령도 내보낼 수 없다는 것을 알 수 있습니다. 최적화 후 마침내 두 개의 텐서 명령어를 내보낼 수 있으며 모든 루프 축이 명령어를 내보낼 수 있습니다.
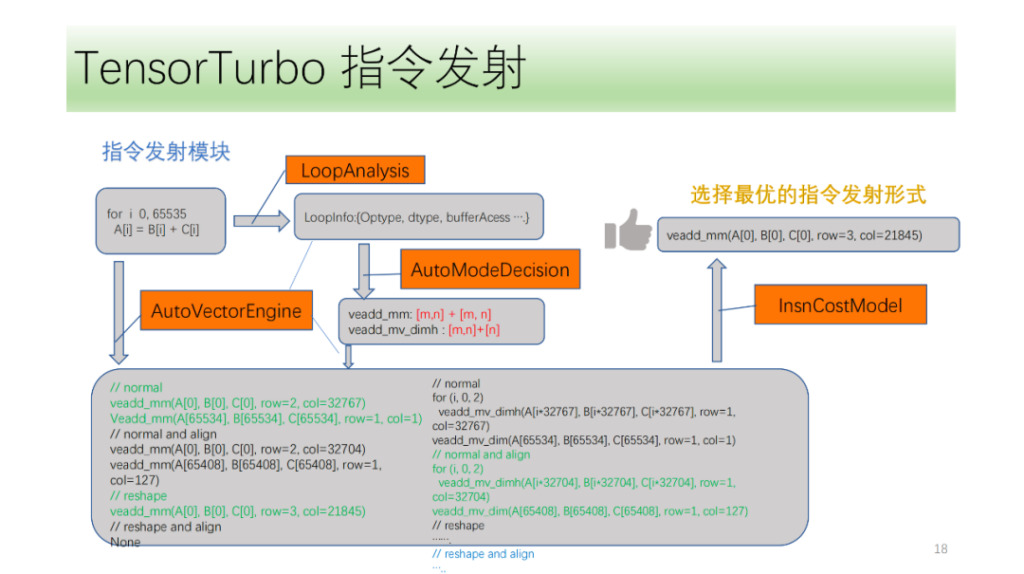
그리고 명령 전송 모듈이 있습니다. 먼저, 명령어 방출 모듈은 루프의 구조를 주기적으로 분석하여 Optype, dtype, bufferAcess 등의 정보를 얻습니다. 이 정보를 얻은 후, 명령어 인식 모듈은 루프 축이 어떤 명령어를 방출할 수 있는지 식별합니다. 하나의 IR 구조가 여러 개의 NPU 명령어에 대응할 수 있으므로, 방출될 수 있는 모든 명령어를 식별하고, VectorEngine 검색 엔진이 명령어 정렬 및 재구성과 같은 일련의 정보를 기반으로 각 명령어 방출 가능성을 검색하도록 합니다. 마지막으로 CostModel은 배출에 대한 최적의 배출 형태를 계산하고 찾습니다.
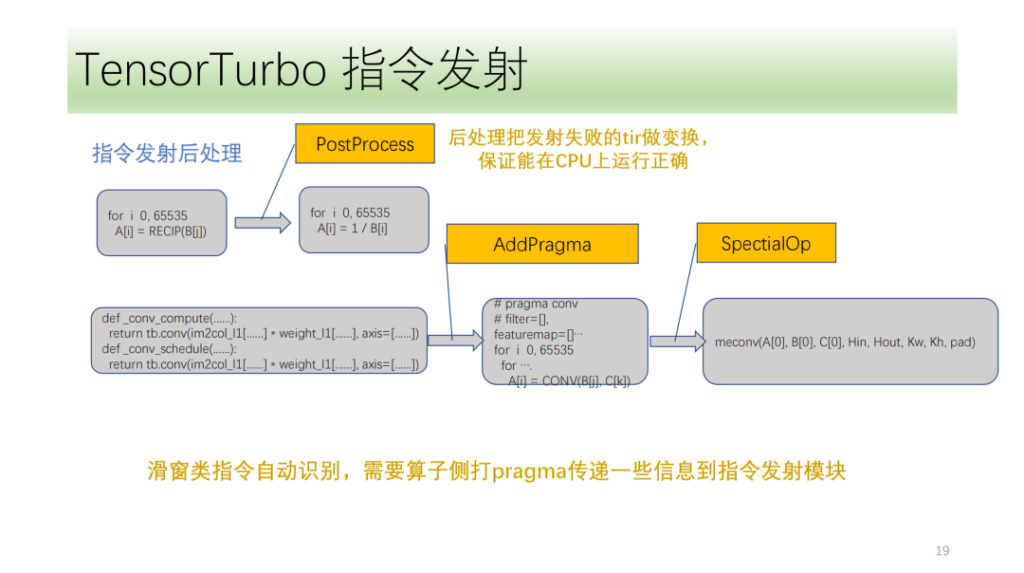
마지막은 지시 후 처리 모듈입니다. 주된 목적은 명령을 내리지 못한 tir을 처리하여 CPU에서 올바르게 실행될 수 있도록 하는 것입니다. 또한 Shim은 알고리즘의 프런트 엔드에 표시해야 하는 몇 가지 특수 지침도 있습니다. 명령어 전송 모듈은 이러한 마크와 자체 IR 분석을 사용하여 해당 명령어를 올바르게 전송합니다.
위의 내용은 Shim의 전체 DSA 텐서 양자화 및 벡터화 과정입니다. 우리는 또한 최근 뜨거운 논쟁거리인 마이크로커널 솔루션과 같은 몇 가지 방향을 모색해 왔습니다. 기본적인 아이디어는 컴퓨팅 프로세스를 두 개의 계층으로 나누는 것입니다. 한 계층은 결합된 마이크로커널 형태로 이어지고 다른 계층은 검색됩니다. 마지막으로 두 레이어의 결과를 이어붙여 최적의 결과를 선택합니다. 이 방법의 장점은 검색 복잡성을 줄이고 검색 효율성을 향상시키는 동시에 하드웨어 리소스를 최대한 활용할 수 있다는 것입니다.
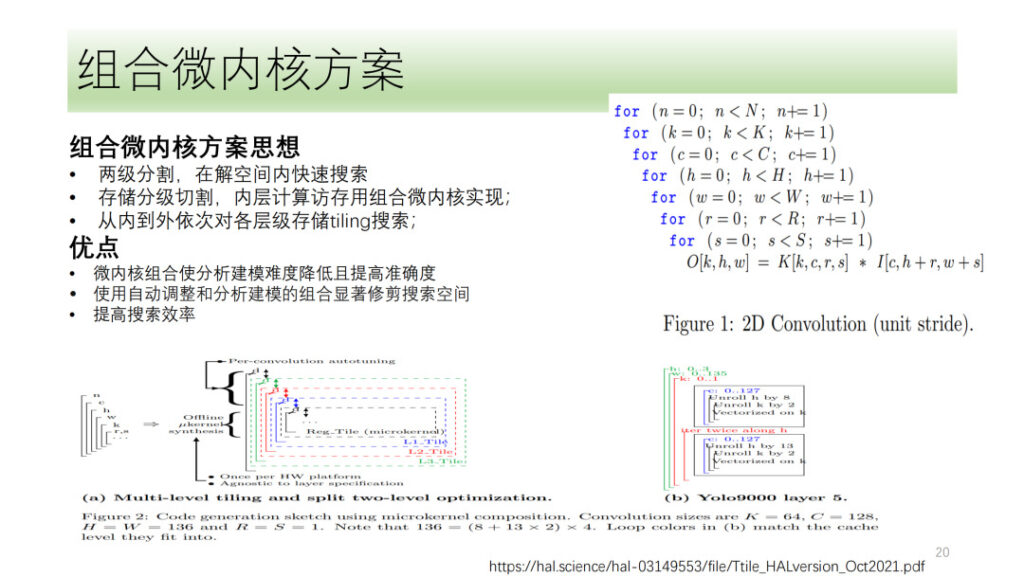

심 교수는 마이크로커널도 탐구했지만, 마이크로커널 솔루션이 기존 솔루션에 비해 성능을 크게 향상시키지 못했다는 점을 고려하면 심 교수는 여전히 마이크로커널 방향으로 탐색 단계에 있다고 볼 수 있다.
Yuan Sheng, Shim Computing: DSA를 위한 사용자 정의 연산자
이 부분은 Shim 컴퓨팅 엔지니어 Yuan Sheng이 사이트에서 공유했습니다.
우선, 우리는 현재 운영자 개발이 네 가지 주요 문제에 직면해 있다는 것을 알고 있습니다.
- 지원이 필요한 신경망 연산자가 많습니다. 분류를 통해 100개 이상의 기본 연산자가 존재하게 되었습니다.
- 하드웨어 아키텍처는 끊임없이 반복되므로 연산자에 관련된 해당 명령어와 논리도 변경되어야 합니다.
- 성능 고려사항 앞서 말씀드린 연산자 융합(로컬 메모리, 공유 메모리)과 그래프 컴퓨팅 정보 전송(세그먼트화 등)은
- 운영자는 사용자에게 개방적이어야 하며, 사용자는 소프트웨어에 들어가서 운영자를 사용자 지정할 수 있습니다.
저는 그것을 크게 다음의 세 가지 측면으로 나누었습니다. 첫 번째는 릴레이 API를 기반으로 기본 언어 연산자에 맞춰 제작된 그래프 연산자입니다.
다음 그림을 예로 들어 보겠습니다.
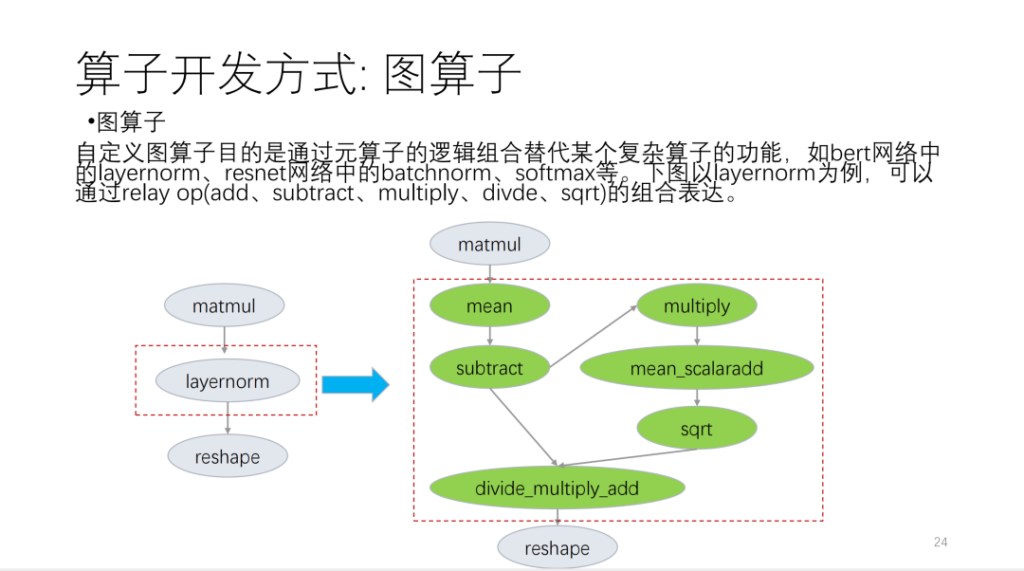
두 번째는 메타연산자입니다. 소위 메타 연산자는 TVM Topi를 기반으로 하며 컴퓨팅/스케줄을 사용하여 연산자 알고리즘 논리와 루프 변환 관련 논리를 설명합니다. 연산자를 개발할 때, 많은 연산자 일정을 재사용할 수 있다는 것을 알게 되었습니다. 이러한 상황을 바탕으로 Shim은 일정과 유사한 템플릿 세트를 제공합니다. 이제 우리는 사업자를 여러 가지 범주로 구분해 보겠습니다. 이러한 카테고리를 기반으로 새로운 운영자는 다수의 일정 템플릿을 재사용하게 될 것입니다.
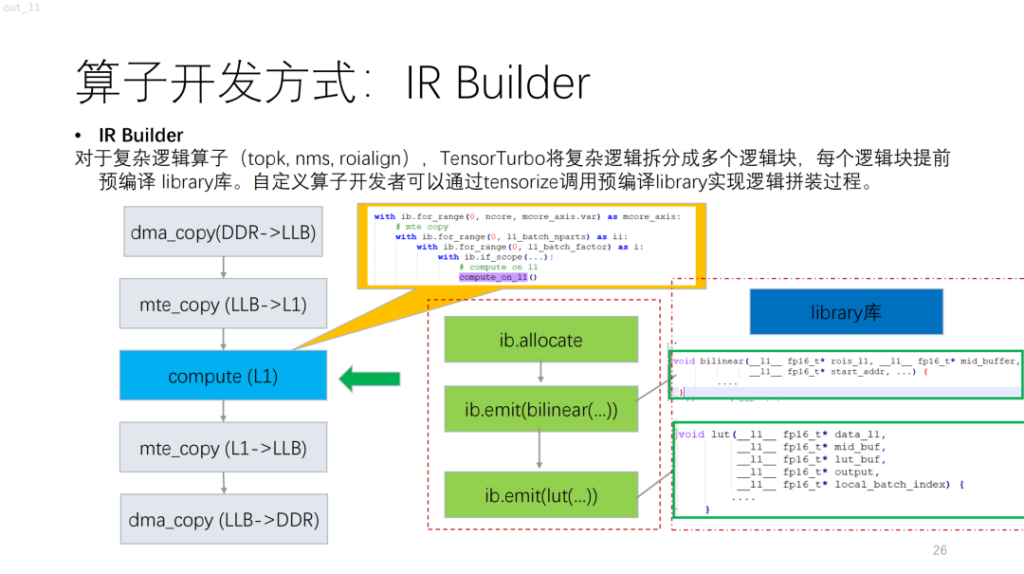
다음은 더 복잡한 연산자입니다. NPU를 기반으로 topk 및 nms와 같은 제어 흐름이 있는 알고리즘은 현재 컴퓨트/스케줄을 사용하여 설명하기 어려운 많은 스칼라 계산을 수행한다는 것을 알 수 있습니다. 이 문제를 해결하기 위해 Shim은 비슷한 라이브러리를 제공합니다. 이는 라이브러리에서 복잡한 논리를 먼저 컴파일한 다음 IR Builder로 결합하여 전체 연산자의 논리를 출력하는 것과 같습니다.
다음은 운영자 세분화입니다. NPU의 경우, GPU와 CPU에 비해 TVM의 각 명령어는 연속된 메모리 블록에서 작동하며 메모리 크기 제한이 있습니다. 동시에 이 경우에는 검색 공간이 크지 않습니다. 심씨는 이러한 문제점을 바탕으로 해결책을 제시했다. 첫째, 후보 집합이 존재하고, 실행 가능한 해결책이 후보 집합에 배치됩니다. 둘째, 성능 요구 사항과 NPU 명령어 제한 사항을 주로 고려하여 실현 가능성을 설명합니다. 마지막으로, 운영자의 특성과 사용될 수 있는 컴퓨팅 장치의 특성을 고려하는 비용 함수가 도입되었습니다.
연산자 개발에서 가장 어려운 측면 중 하나는 퓨전 연산자입니다. 현재 우리는 두 가지 폭발적인 문제에 직면해 있습니다. 첫 번째는 우리 연산자를 다른 연산자와 결합하는 방법을 모른다는 것입니다. 두 번째는 NPU 안에 많은 메모리 레벨이 있고, 메모리 레벨들이 폭발적으로 융합되는 모습을 볼 수 있다는 것입니다. Shim LLB는 공유 메모리와 로컬 메모리의 융합된 조합을 갖게 됩니다. 이러한 상황을 바탕으로 자동 생성 프레임워크도 제공합니다. 먼저, 레이어에서 제공한 스케줄링 정보에 따라 데이터 이동 작업을 삽입하고, 스케줄에 있는 마스터 op와 슬레이브 op에 따라 스케줄 정보를 세분화합니다. 마지막으로, 현재 지침의 한계와 기타 문제를 기반으로 후처리를 수행합니다.

마지막으로 심씨가 지원하는 연산자를 주로 표시하였습니다. ONNX 운영자는 약 124개이며, 현재는 약 112개가 지원되고 있으며, 이는 90.3%에 해당합니다. 동시에 Shim은 큰 소수, 융합 조합, 일부 패턴 융합 조합을 테스트할 수 있는 무작위 테스트 세트를 보유하고 있습니다.
요약하다
이 부분은 Shim 컴퓨팅 엔지니어인 Dan Xiaoqiang이 사이트에서 공유했습니다.
이는 Shim이 TVM을 기반으로 구축한 CI로, 200개 이상의 모델과 많은 단위 테스트를 실행합니다. MR이 CI 리소스를 차지하지 않으면 코드를 제출하는 데 40분 이상 걸립니다. 계산량이 매우 방대하며, 자체 개발한 컴퓨팅 카드 20개 이상과 CPU 머신 몇 대가 필요합니다.
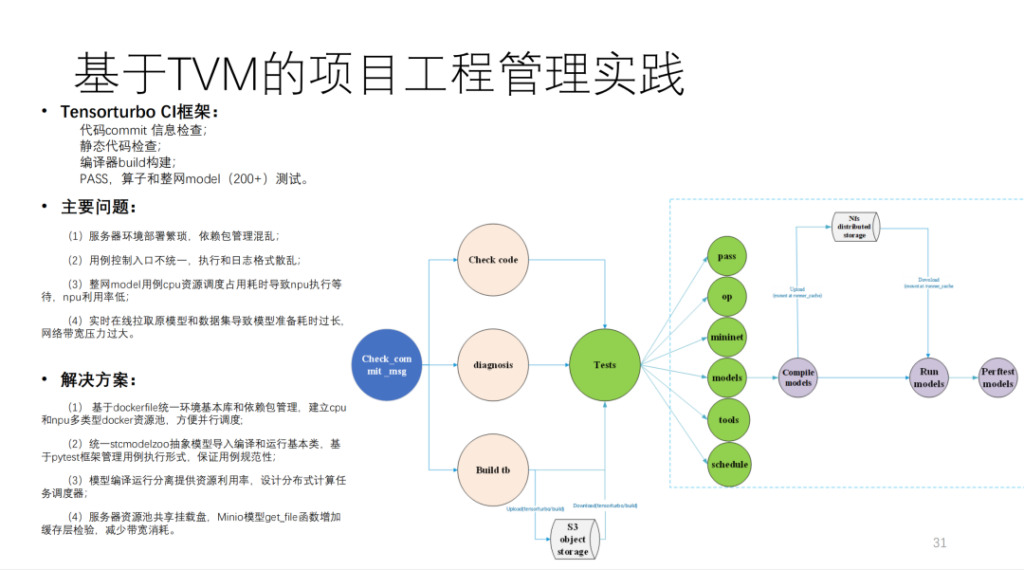
요약하자면 Shim의 아키텍처 다이어그램은 아래와 같습니다.
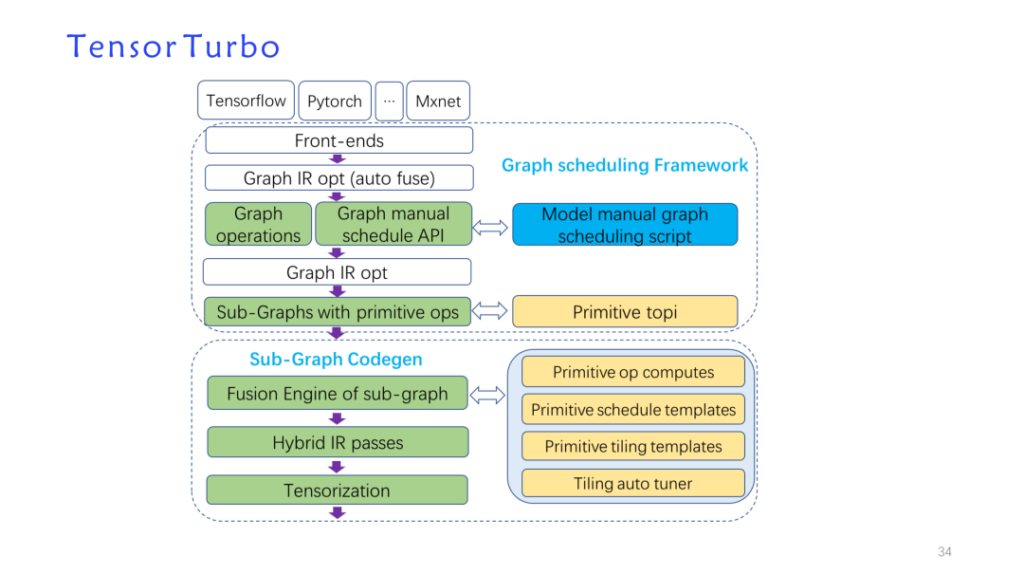
결과를 보면 성과가 크게 향상되었습니다. 또한 자동 생성 기능을 다른 필기 모델 팀과 비교해보면 기본적으로 90% 이상에 도달할 수 있습니다.

Xim 코드의 상황은 다음과 같습니다. 왼쪽은 TVM과 자체 개발 코드가 어떻게 관리되는지 보여줍니다. TVM은 third_party의 데이터 구조로 사용됩니다. Xim에는 자체 소스와 파이썬이 있습니다. TVM을 변경해야 하는 경우 패치 폴더에서 TVM을 수정할 수 있습니다. 여기에는 세 가지 원칙이 있습니다.
- 그들 대부분은 자체 개발한 패스를 사용하고 사용자 정의 모듈도 개발합니다.
- 패치는 TVM 소스 코드의 수정을 제한하고 가능한 경우 적절한 시간에 업스트림합니다.
- TVM 커뮤니티와 정기적으로 동기화하고 저장소에 최신 코드를 업데이트합니다.
전체 코드 양도 위의 그림에 표시되어 있습니다.
요약:
- 우리는 TVM을 기반으로 HIMU의 1세대 및 2세대 칩을 종단간으로 지원합니다.
- Relay 및 Tir을 기반으로 모든 컴파일 최적화 요구 사항을 구현합니다.
- tir을 기반으로 100개 이상의 벡터 텐서 명령어 자동 생성이 완료되었습니다.
- TVM을 기반으로 맞춤형 운영자 솔루션을 구현했습니다.
- 이 모델의 첫 번째 세대는 160+를 지원하고, 두 번째 세대는 20+를 지원합니다.
- 모델의 성능은 필기체에 가깝습니다.
질문과 답변
Q1: 퓨전 연산자에 관심이 있습니다. TVM의 TIR과 어떻게 결합되나요?
A1: 오른쪽 그림의 경우, 동일한 연산자 레벨에 대해, 먼저 연산자에 입력이 두 개, 출력이 하나 있다면, 연산자 형태는 27개가 됩니다. 둘째, 다양한 사업자가 연결된 경우 범위는 세 가지 중 하나일 수 있으므로 고정된 패턴을 가정하지 않습니다. 그러면 TVM에 이를 어떻게 구현할 수 있을까? 먼저 레이어 스케줄링에 따라 프런트, 백 에드와 중간 스코프를 어디에 둘지 결정합니다. 이 층은 매우 복잡한 과정입니다. 출력 결과는 운영자가 어떤 캐시에 있는지, 그리고 얼마나 많은 캐시가 사용 가능한지 확인하는 것입니다. 이러한 스케줄링의 결과를 바탕으로 연산자 계층에서 자동으로 융합된 연산자를 생성합니다. 예를 들어, 범위 정보에 따라 데이터 마이그레이션 작업을 자동으로 삽입하여 데이터 흐름 구성을 완료합니다.
일정 정보의 메커니즘은 TVM 네이티브의 메커니즘과 매우 유사합니다. 각 멤버 범위에서 사용하는 크기는 융합 과정에서 고려되어야 합니다. 이건 TVM에서 나온 거군요. 우리는 이를 통합하고 자동화하기 위해 특별한 프레임워크를 사용합니다.
이를 토대로 개발자가 요구하는 일정을 세우고, 일부 후처리 작업이 있을 수 있습니다.

질문 2: CostModel에 대해 더 자세히 설명해 주시겠습니까? 비용 함수는 운영자 수준 기능을 기반으로 설계되었나요, 아니면 하드웨어 수준 기능을 기반으로 설계되었나요?
A1: 전반적인 아이디어는 다음과 같습니다. 먼저 후보 집합이 생성됩니다. 생성 과정은 NPL 구조와 관련이 있습니다. 그 다음에는 명령어 제한과 그에 따른 최적화, 멀티 코어, 더블 버퍼 등을 고려한 가지치기 프로세스가 있습니다. 마지막으로 이를 정렬하기 위한 비용 함수가 있습니다.
우리는 최적화 루틴의 본질이 계산에서 데이터 이동을 숨기는 방법이라는 것을 알고 있습니다. 이 기준에 따라 작업을 시뮬레이션하고 최종적으로 비용을 계산하는 것에 불과합니다.
질문 3: TVM이 지원하는 기본 퓨전 규칙 외에도 TVM은 컴퓨팅 계층의 다양한 하드웨어에 맞게 사용자 정의된 고유한 퓨전과 같은 새로운 퓨전 규칙을 생성했습니까?
A3: 융합에 관해서는 실제로 두 가지 수준이 있습니다. 첫 번째는 버퍼 퓨전이고, 두 번째는 루프 퓨전입니다. TVM 융합 방식은 실제로 후자를 목표로 합니다. Shim은 기본적으로 귀하가 언급한 TVM 퓨전 패턴을 따르지만 몇 가지 제한이 있습니다.