Command Palette
Search for a command to run...
"인스턴트 유니버스"를 개발한 AI 회사는 Stable Diffusion의 개발에 참여했으며 작년에 5,000만 달러의 자금을 지원받았습니다.

본 글은 HyperAI 위챗 공식 계정에 처음 게재되었습니다~
베이징 시간으로 3월 13일 오전, 2023년 오스카 시상식이 로스앤젤레스에서 열렸습니다.영화 "블링크 오브 앤 아이"는 한꺼번에 7개 상을 휩쓸며 가장 큰 수상작이 되었습니다.주연 여배우 미셸 요는 이 영화로 아카데미 여우주연상을 수상하면서, 오스카 역사상 최초의 중국인 여배우가 되었습니다.

이 격렬한 논쟁의 SF 영화의 시각 효과 팀은 단 5명인 것으로 알려졌다. 가능한 한 빨리 특수 효과 장면을 완성하기 위해 그들은 Runway의 기술을 선택하여 특정 장면을 만드는 데 도움을 받았습니다. 예를 들어, 이미지의 배경을 제거하기 위해 그린 스크린 도구(The Green Screen)를 사용했습니다.
감독이자 시나리오 작가인 에반 할렉은 인터뷰에서 "단 몇 번의 클릭만으로 시간을 절약할 수 있고, 그 시간을 활용해 3~4가지 효과를 시도해 영화를 더 좋게 만들 수 있다"고 말했다.

Runway : 1세대 안정 확산 개발에 참여
2018년 말, 크리스토발 발렌주엘라와 다른 멤버들은 런웨이를 창립했습니다.디자이너, 아티스트, 개발자의 콘텐츠 제작 문턱을 낮추고 창의적인 콘텐츠 개발을 촉진하기 위해 컴퓨터 그래픽과 머신 러닝의 최신 기술을 사용하는 데 전념하는 인공 지능 비디오 편집 소프트웨어 제공업체입니다.

직원은 약 40명 정도
게다가,런웨이는 덜 알려진 정체성을 가지고 있는데, 바로 스테이블 디퓨전의 초기 버전에서 주요 참여자였다는 것입니다.
2021년에 Runway는 독일 뮌헨 대학교와 협력하여 Stable Diffusion의 첫 번째 버전을 구축했습니다. 이후 영국의 스타트업 Stability AI가 "그룹에 자본을 투자"하여 Stable Diffusion에 모델 학습에 필요한 컴퓨팅 리소스와 자금을 더 제공했습니다. 하지만 Runway와 Stability AI는 더 이상 협력하지 않습니다.
2022년 12월, 런웨이는 시리즈 C 자금 조달로 5,000만 달러를 유치했습니다. "블링크" 팀 외에도 CBS와 MBC 같은 미디어 그룹, Assembly와 VaynerMedia 같은 광고 회사, 그리고 Pentagram 같은 디자인 회사도 고객으로 참여하고 있습니다.
2023년 2월 6일, 런웨이 공식 트위터 계정에서 Gen-1 모델이 공개되었습니다.텍스트 큐나 참조 이미지로 지정된 스타일을 적용하여 기존 비디오를 새로운 비디오로 변환할 수 있습니다.
Gen-1: 구조 + 내용
연구자들은 예상되는 출력의 시각적 또는 텍스트 설명을 기반으로 비디오를 편집할 수 있는 구조 및 내용 기반 비디오 확산 모델인 Gen-1을 제안했습니다.
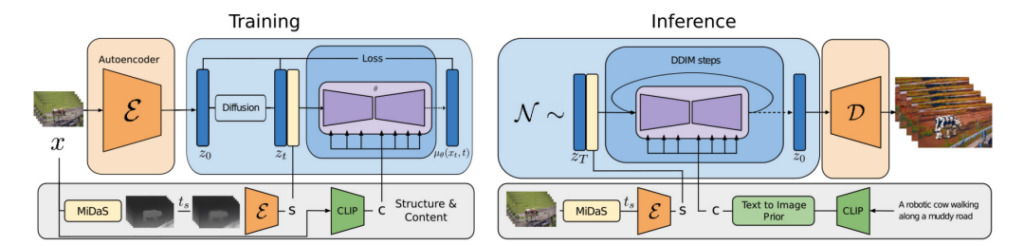
소위 콘텐츠란 대상 객체의 색상과 스타일, 장면의 조명 등 비디오의 모양과 의미를 설명하는 특징을 말합니다.
구조는 대상 객체의 모양, 위치, 시간적 변화와 같은 기하학적, 동적 특성에 대한 설명을 말합니다.
Gen-1 모델의 목표는 비디오 구조를 보존하면서 비디오 콘텐츠를 편집하는 것입니다.
모델 학습 과정에서 연구진은 자막이 없는 비디오와 텍스트-이미지 쌍으로 구성된 대규모 데이터 세트를 사용했습니다. 동시에, 단안적 장면 깊이 추정치를 사용하여 구조를 표현하였고, 사전 훈련된 신경망이 예측한 임베딩을 사용하여 콘텐츠를 표현하였습니다.
이 접근 방식은 생성 프로세스에 대한 여러 가지 강력한 제어 모드를 제공합니다.
1. 이미지 합성 모델을 참조하여 추론된 비디오 콘텐츠(프레젠테이션이나 스타일 등)가 사용자가 제공한 이미지나 프롬프트와 일치하도록 모델을 학습합니다.

2. 확산 과정을 참조하고 구조 표현에 대한 정보 모호화를 수행하여 개발자가 주어진 구조에 대한 모델 준수의 유사성 정도를 설정할 수 있습니다.
3. 분류자 없는 지침을 참조하고 사용자 지정 지침 방법을 사용하여 추론 프로세스를 조정하여 생성된 클립의 시간적 일관성을 제어합니다.
이 실험에서 연구자들은:
- 사전 훈련된 이미지 모델에 시간 계층을 도입하고 이미지와 비디오를 공동으로 훈련하여 잠재 확산 모델을 비디오 생성으로 확장합니다.
- 우리는 예시 이미지나 텍스트의 지침에 따라 비디오를 수정할 수 있는 구조 및 내용 인식 모델을 제안합니다. 비디오 편집은 비디오별 훈련이나 사전 처리 없이 추론 단계에서만 수행됩니다.
- 시간적, 내용적, 구조적 일관성에 대한 완벽한 제어. 실험 결과, 이미지와 비디오 데이터에 대한 공동 훈련은 추론 중에 시간적 일관성을 유지할 수 있는 것으로 나타났습니다. 구조적 일관성을 위해 표현의 다양한 세부 수준에서 학습하면 사용자는 추론 중에 원하는 설정을 선택할 수 있습니다.
- 사용자 설문 조사에 따르면 이 방법은 다른 여러 방법보다 더 인기가 있는 것으로 나타났습니다.
- 작은 이미지 하위 집합을 미세 조정함으로써 훈련된 모델을 더욱 맞춤화하여 특정 주제에 대한 더욱 정확한 비디오를 생성할 수 있습니다.
Gen-1의 성능을 평가하기 위해 연구진은 DAVIS 데이터 세트의 비디오와 다양한 다른 자료를 사용했습니다.연구진은 편집 프롬프트를 자동으로 생성하기 위해 먼저 자막 모델을 실행하여 원본 비디오 콘텐츠에 대한 설명을 얻은 다음 GPT3를 사용하여 편집 프롬프트를 생성했습니다.
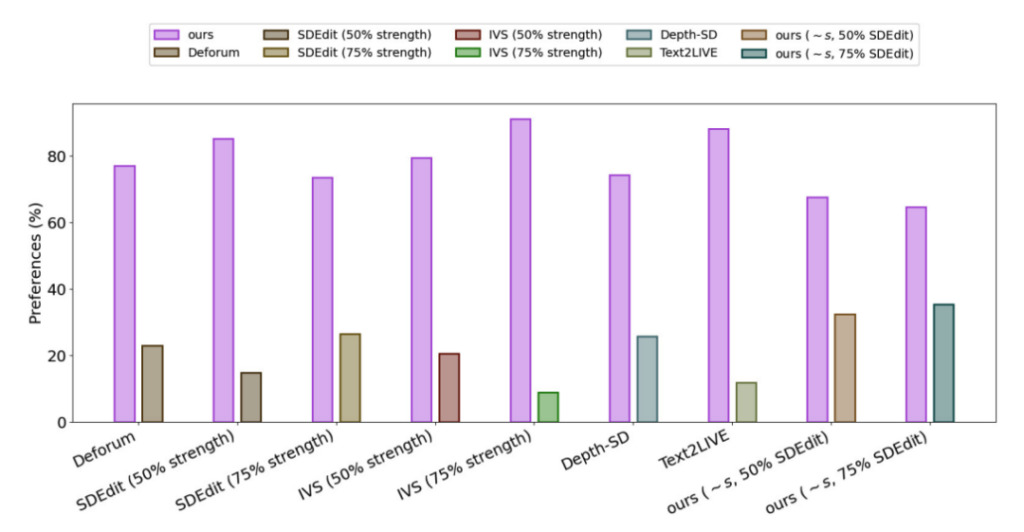
실험 결과, 모든 방법의 만족도 조사에서75% 사용자는 Gen-1 세대 효과를 선호합니다.
AIGC: 논란 속 전진
2022년, 생성적 AI는 10년 전 모바일과 클라우드 컴퓨팅이 등장한 이래 가장 눈길을 끄는 기술이 되었고, 우리는 이 기술의 응용 계층이 싹트는 것을 목격하게 되어 다행입니다.많은 대형 모델이 실험실에서 빠르게 개발되어 현실 세계의 다양한 시나리오에 적용되고 있습니다.
그러나 효율성 향상, 비용 절감 등 많은 이점에도 불구하고 생성적 인공지능은 여전히 많은 과제에 직면해 있다는 점을 알아야 합니다. 과제에는 모델의 출력 품질과 다양성을 개선하는 방법, 생성 속도를 높이는 방법, 적용 과정에서 보안, 개인정보 보호, 윤리 및 종교적 문제가 포함됩니다.
일부 사람들은 AI 예술 창작에 의문을 제기하고, 심지어 일부는 이를 AI가 예술을 "침략"하는 것이라고 생각합니다. 이런 목소리에 직면하여 Runway의 공동 창립자이자 CEO인 크리스토발 발렌주엘라는 AI가 이미지와 기타 콘텐츠를 색칠하거나 수정하는 데 사용되는 도구 상자 속의 도구일 뿐이며 Photoshop이나 LightRoom과 다를 바 없다고 생각합니다.생성적 AI는 아직 논란의 여지가 있지만, 기술에 익숙하지 않은 사람과 창의적인 사람에게 창작의 문을 열어주고, 콘텐츠 제작 분야에 새로운 가능성을 열어줄 것입니다.
참조 링크:
[1]https://hub.baai.ac.cn/view/23940
[2]https://cloud.tencent.com/developer/article/2227337?