TorchServe를 사용하여 모델을 조정하기 위해 Animated Drawing APP를 예로 들어 보겠습니다.
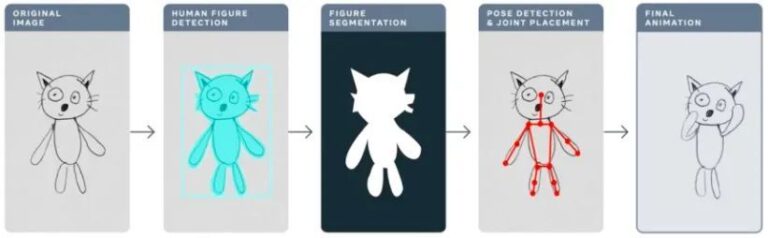
내용물 이전 섹션에서는 TorchServe 모델을 배포하고 모델을 프로덕션 환경에 배포하기 위한 튜닝의 5단계를 소개했습니다. 이 섹션에서는 애니메이션 도면 APP를 예로 들어 TorchServe의 모델 최적화 효과를 설명합니다. 본 기사는 WeChat 공식 계정에 처음 게시되었습니다.PyTorch 개발자 커뮤니티
작년에 Meta는 Animated Drawing 앱을 사용하여 어린이의 손으로 그린 그림을 AI로 "애니메이션"으로 만들어 몇 초 만에 정적인 스틱 그림을 애니메이션으로 바꾸었습니다.


애니메이션 드로잉 sketch.metademolab.com/
AI에게는 쉬운 일이 아닙니다. AI는 원래 현실 세계의 이미지를 처리하기 위해 설계되었습니다. 실제 그림과 비교해 보면, 어린이의 그림은 형태와 스타일이 매우 다르고, 더 복잡하고 예측할 수 없습니다. 따라서 기존의 AI 시스템은 애니메이션 그림과 유사한 작업을 처리하는 데 적합하지 않을 수 있습니다.
이 문서에서는 애니메이션 드로잉을 예로 들어 TorchServe를 사용하여 프로덕션 환경에 배포될 모델을 조정하는 방법을 자세히 설명합니다.
생산 환경에서 모델 튜닝에 영향을 미치는 4가지 요소
다음 워크플로는 TorchServe를 사용하여 프로덕션 환경에 모델을 배포하는 전반적인 아이디어를 보여줍니다.

대부분의 경우, 프로덕션 환경에 배포된 모델은 처리량이나 지연 시간 서비스 수준 계약(SLA)에 따라 최적화됩니다.
일반적으로 실시간 애플리케이션은 지연 시간에 더 관심을 갖는 반면, 오프라인 애플리케이션은 처리량에 더 관심을 갖습니다.
프로덕션 환경에 배포된 모델의 성능에 영향을 미치는 요소는 여러 가지가 있습니다. 이 기사에서는 그 중 네 가지에 초점을 맞춥니다.
1. 모델 최적화
이는 모델을 프로덕션에 배포하기 위한 사전 단계이며 양자화, 가지치기, IR 그래프(PyTorch의 TorchScript) 사용, 커널 융합 및 기타 여러 기술을 포함합니다. 현재 TorchPrep에서는 많은 유사한 기술을 CLI 도구로 사용할 수 있습니다.
2. 배치 추론
이는 모델에 여러 개의 입력을 공급하는 것을 말합니다. 이는 학습 과정에서 자주 사용되며 추론 단계에서 비용을 제어하는 데에도 유용합니다.
하드웨어 가속기는 병렬 처리를 위해 최적화되어 있으며, 배칭은 컴퓨팅 성능을 최대한 활용하는 데 도움이 되며, 그 결과 처리량이 높아지는 경우가 많습니다. 추론의 주요 차이점은 클라이언트로부터 배치를 받기 위해 너무 오랫동안 기다릴 필요가 없다는 것입니다. 이를 동적 배치라고 부릅니다.
3. 근로자 수
TorchServe는 작업자를 통해 모델을 배포합니다. TorchServe의 워커는 추론에 사용되는 모델 가중치의 사본을 가지고 있는 Python 프로세스입니다. 근로자가 너무 적으면 충분한 병렬 처리로부터 이익을 얻을 수 없습니다. 근로자가 너무 많으면 근로자 간의 경쟁이 감소하고 업무 전반의 성과가 떨어집니다.
4. 하드웨어
모델, 애플리케이션, 지연 시간 및 처리량 예산에 따라 TorchServe, CPU, GPU, AWS Inferentia 중에서 적합한 하드웨어를 선택하세요.
일부 하드웨어 구성은 동급 최고의 성능을 얻도록 설계된 반면, 다른 구성은 예상 비용을 더욱 효율적으로 통제하도록 설계되었습니다. 실험 결과 배치 크기가 클 때 GPU가 더 적합한 것으로 나타났습니다. 배치 크기가 작거나 낮은 지연 시간이 요구되는 경우 CPU와 AWS Inferentia가 더 비용 효율적입니다.
팁: TorchServe 성능 최적화 시 주의할 사항
시작하기 전에,먼저 TorchServe를 사용하여 모델을 배포하고 최상의 성능을 얻기 위한 몇 가지 팁을 알려드리겠습니다.
하드웨어 선택은 모델 최적화 선택과도 밀접하게 연관되어 있습니다.
* 모델 배포를 위한 하드웨어 선택은 지연 시간, 처리량 기대치, 각 추론 비용과 밀접한 관련이 있습니다.
모델 크기와 응용 프로그램의 차이로 인해 CPU 프로덕션 환경에서는 일반적으로 유사한 컴퓨터 비전 모델을 배포할 여력이 없습니다.OpenBayes.com을 사용하기 위해 등록하면 등록 시 RTX3090을 3시간 무료로 이용할 수 있으며, 일반적인 GPU 요구 사항을 충족하기 위해 매주 10시간의 RTX3090을 무료로 이용할 수 있습니다.
게다가 TorchServe에 최근 추가된 IPEX와 같은 최적화 덕분에 이러한 모델의 배포 비용이 절감되고 CPU 비용도 절감되었습니다.
IPEX 최적화 모델 배포에 대한 자세한 내용은 다음을 참조하세요.
* TorchServe의 워커는 Python 프로세스에 속합니다.병렬로 제공할 수 있습니다.근로자의 수는 신중하게 설정해야 합니다.기본적으로 TorchServe는 호스트에서 사용 가능한 VCPU 또는 GPU 수와 동일한 수의 작업자를 시작하므로 TorchServe 시작에 상당한 시간이 추가될 수 있습니다.
TorchServe는 작업자 수를 설정하기 위한 구성 속성을 제공합니다. 여러 작업자에게 효율적인 병렬 처리를 제공하고 리소스 경쟁을 피하기 위해 CPU와 GPU에 다음 기준을 설정하는 것이 좋습니다.
CPU:핸들러에 설정 토치.set_num_threads(1) . 그런 다음 작업자 수를 설정하세요. 물리적 코어 수 / 2 . 하지만 최상의 스레드 구성은 Intel CPU 런처 스크립트를 활용하면 달성할 수 있습니다.
GPU:사용 가능한 GPU 수는 config.properties에서 설정할 수 있습니다. 숫자_GPU 설정하려면. TorchServe는 라운드 로빈 방식을 사용하여 작업자를 GPU에 할당합니다. 제안:작업자 수 = (사용 가능한 GPU 수) / (고유 모델 수). Ampere 이전 GPU는 Multi Instance GPU와 리소스 분리를 제공하지 않습니다.
* 배치 크기는 지연 시간과 처리량에 직접적인 영향을 미칩니다.컴퓨팅 리소스를 더 잘 활용하려면 배치 크기를 늘려야 합니다. 지연 시간과 처리량 사이에는 상충 관계가 있습니다. 배치 크기가 커지면 처리량은 늘어나지만 지연 시간도 길어질 수 있습니다.
TorchServe에서 배치 크기를 설정하는 방법은 두 가지가 있습니다.하나는 config.properties에서 모델 구성을 사용하는 것이고, 다른 하나는 Management API를 사용하여 모델을 등록하는 것입니다.
다음 섹션에서는 TorchServe 벤치마크 제품군을 사용하여 모델 최적화를 위한 하드웨어, 작업자 및 배치 크기의 최적 조합을 결정하는 방법을 보여줍니다.
TorchServe 벤치마크 스위트를 만나보세요
TorchServe 벤치마크 모음을 사용하려면 먼저 위에 언급된 보관 파일이 필요합니다. .마르 문서. 이 파일에는 추론을 로드하고 실행하는 데 사용되는 모델, 핸들러 및 기타 모든 아티팩트가 포함되어 있습니다. 애니메이션 드로잉 APP는 Detectron2의 Mask-rCNN 객체 감지 모델을 사용합니다.
벤치마크 스위트 실행
TorchServe의 자동 벤치마크 제품군은 다양한 배치 크기와 작업자 설정에서 여러 모델을 벤치마킹하고 보고서를 출력할 수 있습니다.
배우다 자동화된 벤치마크 제품군
달리기 시작:
git clone https://github.com/pytorch/serve.git cd serve/benchmarks pip install -r requirements-ab.txt apt-get install apache2-utils
yaml 파일에서 모델 수준 설정을 구성합니다.
Model_name: eager_mode: benchmark_engine: "ab" url: ".mar 파일 경로" workers: - 1 - 4 batch_delay: 100 batch_size: - 1 - 2 - 4 - 8 requests: 10000 concurrency: 10 input: "모델 입력 경로" backend_profiling: False exec_env: "local" processors: - "cpu" - "gpus": "all"
이 yaml 파일은 benchmark_config_template.yaml 인용하다. YAML 파일에는 AWS Cloud를 사용하여 보고서를 생성하고 로그를 보기 위한 추가 설정이 포함되어 있습니다.
파이썬 벤치마크/auto_benchmark.py --input benchmark_config_template.yaml
벤치마크를 실행하면 결과가 CSV 파일로 저장됩니다. _/tmp/벤치마크/ab_report.csv_ 또는 전체 보고서 /tmp/ts_benchmark/report.md 에서 발견됨.
결과에는 TorchServe 평균 지연 시간, 모델 P99 지연 시간, 처리량, 동시성, 요청 수, 핸들러 시간 및 기타 측정 항목이 포함됩니다.
모델 튜닝에 영향을 미치는 다음 요소를 추적하는 데 중점을 둡니다. 동시성, 모델 P99 대기 시간 및 처리량입니다.
이러한 숫자는 배치 크기, 사용 장비, 작업자 수, 모델 최적화가 수행되었는지 여부와 함께 고려해야 합니다.
이 모델의 지연 SLA는 100ms로 설정되었습니다. 이는 실시간 애플리케이션이므로 지연 시간이 중요한 문제이며, 처리량은 지연 시간 SLA를 위반하지 않으면서 최대한 높아야 합니다.
공간을 검색하여 다양한 배치 크기(1~32), 작업자 수(1~16), 장치(CPU, GPU)에 대한 일련의 실험을 실행하고 다음 표에 표시된 대로 가장 좋은 실험 결과를 요약했습니다.

이 모델은 CPU 지연 시간, 배치 크기, 동시성 및 작업자 수에 대한 모든 것을 시도했지만 모두 SLA를 충족하지 못했으며 실제로 지연 시간을 13배로 줄였습니다.
모델 배포를 GPU로 옮기자 대기 시간이 305ms에서 23.6ms로 즉시 줄었습니다.
모델에 대해 수행할 수 있는 가장 간단한 최적화 중 하나는 정밀도를 한 줄 코드인 fp16으로 줄이는 것입니다. (모델.반()) , 32%의 모델 P99 대기 시간을 줄이고 처리량을 거의 같은 양만큼 늘릴 수 있습니다.
모델을 최적화하는 또 다른 방법은 모델을 TorchScript로 변환하고 사용하는 것입니다. 추론을 위한 최적화 또는 공격적인 퓨전을 활용하는 다른 기술(onnx 또는 텐서 런타임 최적화 포함)입니다.
CPU와 GPU에서 설정 근로자 수=1 이 글에서는 이 방법이 가장 적합합니다.
* 모델을 GPU에 배포하고 설정 근로자 수 = 1, 배치 크기 = 1CPU에 비해 처리량은 12배 증가하고 대기 시간은 13배 감소했습니다.
* 모델을 GPU에 배포하고 설정 모델.반(), 근로자 수 = 1 , 배치 크기 = 8처리량과 허용 가능한 지연 시간 측면에서 가장 좋은 결과를 얻을 수 있습니다. CPU에 비해 처리량은 25배 증가했지만 지연 시간은 여전히 SLA(94.4ms)를 충족했습니다.
참고: 벤치마크 제품군을 실행하는 경우 적절한 설정을 해야 합니다. 배치 지연, 요청의 동시성을 배치 크기에 비례하는 숫자로 설정합니다. 여기서 동시성이란 서버로 전송되는 동시 요청 수를 말합니다.
요약하다
이 문서에서는 프로덕션 환경에서 TorchServe 모델을 튜닝할 때 고려해야 할 사항과 성능 최적화를 위한 TorchServe 벤치마크 제품군을 소개합니다. 이를 통해 사용자는 모델 최적화, 하드웨어 선택 및 전반적인 비용에 대한 가능한 선택 사항을 더 깊이 이해할 수 있습니다.
에 집중하다 PyTorch 개발자 커뮤니티PyTorch 기술 업데이트, 모범 사례 및 관련 정보를 더 많이 받아볼 수 있는 공식 계정입니다!