Command Palette
Search for a command to run...
전적으로! OpenAI는 연말에 새로운 제품을 출시할 예정이다. 단일 카드로 1분 안에 3D 포인트 클라우드를 생성할 수 있습니다. 텍스트-3D 변환, 고전력 컴퓨팅 시대와 작별
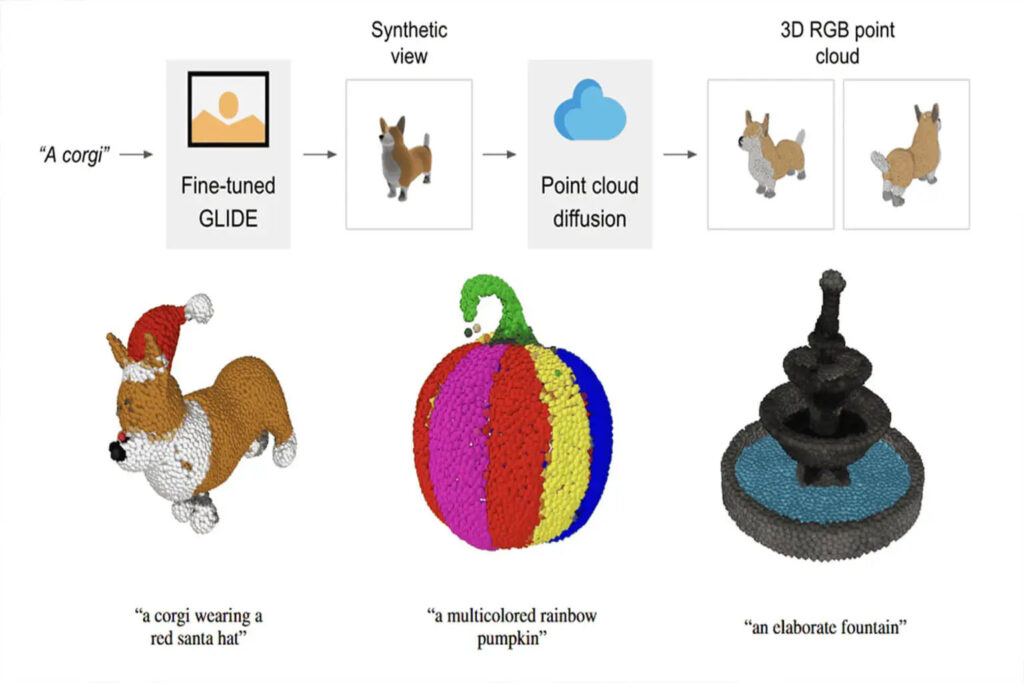
내용을 한눈에 보기:DALL-E와 ChatGPT에 이어 OpenAI도 또 다른 노력을 기울여 최근 텍스트 프롬프트를 기반으로 3D 포인트 클라우드를 직접 생성할 수 있는 Point·E를 출시했습니다. 키워드:OpenAI 3D 포인트 클라우드 포인트 E
OpenAI는 연말 실적을 목표로 노력하고 있습니다. 한 달 전쯤에 ChatGPT가 출시되었지만, 아직도 많은 네티즌이 이를 알아내지 못했습니다. 최근에는 텍스트 프롬프트를 기반으로 3D 포인트 클라우드를 직접 생성할 수 있는 Point·E라는 강력한 도구를 조용히 출시했습니다.
텍스트-3D: 올바른 접근 방식을 사용하면 두 가지 작업을 수행할 수 있습니다.
3D 모델링은 누구나 다 알고 있다고 생각합니다. 최근 몇 년 동안 3D 모델링은 영화 제작, 비디오 게임, 산업 디자인, VR 및 AR 등의 분야에서 볼 수 있습니다.
하지만 인공지능의 도움으로 사실적인 3D 이미지를 만드는 것은 여전히 시간이 많이 걸리고 노동 집약적인 과정입니다.예를 들어 Google DreamFusion을 살펴보면, 주어진 텍스트로부터 3D 이미지를 생성하려면 일반적으로 여러 개의 GPU가 필요하고 몇 시간 동안 실행해야 합니다.

일반적으로 텍스트-3D 합성 방법은 두 가지 범주로 나뉩니다.
방법 1:쌍으로 구성된 (텍스트, 3D) 데이터나 레이블이 지정되지 않은 3D 데이터에 대해 직접 생성 모델을 학습합니다.
이러한 방법은 기존의 생성 모델 방법을 활용해 효과적으로 샘플을 생성할 수 있지만, 대규모 3D 데이터 세트가 부족해 복잡한 텍스트 프롬프트로 확장하기 어렵습니다.
방법 2:미리 훈련된 텍스트-이미지 모델을 활용하여 차별화 가능한 3D 표현을 최적화합니다.
이러한 방법은 일반적으로 복잡하고 다양한 텍스트 프롬프트를 처리할 수 있지만, 각 샘플에 대한 최적화 프로세스는 비용이 많이 듭니다. 더욱이 강력한 3차원 사전 지식이 부족하기 때문에 이러한 방법은 국소적 최소값(의미 있거나 일관된 3차원 객체와 일대일로 대응할 수 없음)에 빠질 수 있습니다.
Point·E는 텍스트-이미지 모델과 이미지-3D 모델을 결합합니다.위의 두 가지 방법의 장점을 결합하면,3D 모델링의 효율성이 더욱 향상되어 텍스트를 3D 포인트 클라우드로 변환하는 데 GPU 1개와 1~2분만 필요합니다.
원리 분석: 3D 포인트 클라우드를 생성하는 3단계
E 지점에서 텍스트-이미지 모델은 대규모 코퍼스(텍스트, 이미지 쌍)를 활용하여 복잡한 텍스트 프롬프트를 적절히 처리할 수 있습니다. 이미지-3D 모델은 더 작은 데이터 세트(이미지, 3D 쌍)를 통해 학습됩니다.
Point·E를 사용하여 텍스트 프롬프트를 기반으로 3D 포인트 클라우드를 생성하는 프로세스는 세 단계로 나뉩니다.
1. 텍스트 프롬프트를 기반으로 합성 뷰 생성
2. 합성 뷰를 기반으로 거친 포인트 클라우드(1024개 포인트)를 생성합니다.
3. 저해상도 포인트 클라우드와 합성 뷰를 기반으로 미세 포인트 클라우드(4096 포인트) 생성

데이터 형식과 데이터 품질은 학습 결과에 큰 영향을 미치므로,Point·E는 Blender를 사용하여 모든 교육 데이터를 공통 형식으로 변환했습니다.
Blender는 다양한 3D 포맷을 지원하고 최적화된 렌더링 엔진을 갖추고 있습니다. Blender 스크립트는 모델을 바운딩 큐브로 통합하고, 표준 조명 설정을 구성하고, 마지막으로 Blender의 내장 실시간 렌더링 엔진을 사용하여 RGBAD 이미지를 내보냅니다.
""" Blender 내에서 3D 모델을 RGBAD 이미지로 렌더링하기 위해 실행되는 스크립트입니다. 사용 예 blender -b -P blender_script.py -- \ --input_path ../../examples/example_data/corgi.ply \ --output_path render_out CLIP R-Precision 결과 계산에 사용되는 렌더링에 대해 `--camera_pose z-circular-elevated`를 전달합니다. 출력 디렉터리에는 렌더링된 각 뷰의 메타데이터 JSON 파일과 렌더링에 대한 전역 메타데이터 파일이 포함됩니다. 각 이미지는 각 채널(rgbad)의 16비트 PNG 파일 모음과 뷰의 전체 회색조 렌더링으로 저장됩니다. """
블렌더 스크립트 코드
스크립트를 실행하면 3D 모델이 RGBAD 이미지로 균일하게 렌더링됩니다.
전체 스크립트를 보려면 다음을 참조하세요.
이전 텍스트-3D AI 비교
지난 2년 동안 텍스트-3D 모델 생성에 대한 많은 연구가 진행되었습니다.Google과 NVIDIA와 같은 주요 회사도 자체 AI를 출시했습니다.
우리는 여러분이 수평적으로 차이점을 비교할 수 있도록 텍스트-3D 합성 AI 3개를 수집하고 편집했습니다.
드림필즈
출판사:Google
출시 시간:2021년 12월
프로젝트 주소:https://ajayj.com/dreamfields
DreamFields는 신경망 렌더링과 다중 모드 이미지 및 텍스트 표현을 결합합니다.텍스트 설명만으로 3D 감독 없이도 다양한 3D 객체 모양과 색상을 생성할 수 있습니다.

DreamFields가 3D 객체를 생성하는 과정에서대규모 텍스트 이미지 데이터세트를 기반으로 사전 학습된 이미지-텍스트 모델을 활용하고 다양한 관점에서 신경 복사장을 최적화합니다.이를 통해 사전 훈련된 CLIP 모델이 렌더링한 이미지가 대상 텍스트에서 좋은 결과를 얻을 수 있습니다.
드림퓨전
출판사:Google
출시 시간:2022년 9월
프로젝트 주소:https://dreamfusion3d.github.io/
DreamFusion은 사전 훈련된 2D 텍스트-이미지 확산 모델의 도움으로 텍스트-3D 합성을 달성할 수 있습니다.
DreamFusion은 확률 밀도 증류를 기반으로 한 손실을 도입하여 2D 확산 모델을 매개 변수 이미지 생성기를 최적화하기 위한 사전으로 사용할 수 있게 해줍니다.

Dreamfusion은 DeepDream과 유사한 절차로 이 손실을 적용하여, 경사 하강법을 통해 무작위 각도에서 2D 렌더링을 수행할 때 무작위로 초기화된 3D 모델(Neural Radiance Field, NeRF)을 비교적 낮은 손실로 최적화합니다.
Dreamfusion에는 3D 학습 데이터가 필요하지 않으며, 이미지 확산 모델을 수정할 필요도 없습니다.사전 학습된 이미지 확산 모델의 사전 효율성이 입증되었습니다.
매직3D
출판사:엔비디아
출시 시간:2022년 11월
프로젝트 주소:deepimagination.cc/Magic3D/
Magic3D는 고품질 3D 메시 모델을 만드는 데 사용할 수 있는 텍스트-3D 콘텐츠 생성 도구입니다.Magic3D는 이미지 컨디셔닝 기술과 텍스트 기반 프롬프트 편집 방법을 사용하여 3D 합성을 제어하는 새로운 방법을 제공하여 다양한 창의적 응용 분야에 새로운 길을 열어줍니다.
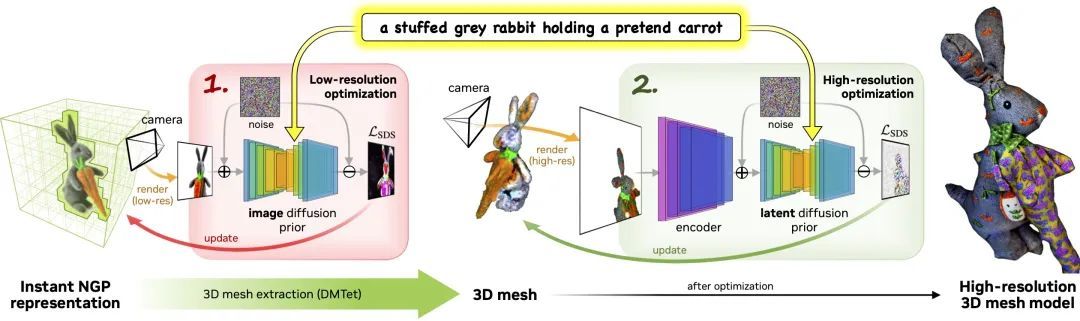
이 과정은 두 단계로 구성됩니다.
1단계:거친 모델을 얻기 전에 저해상도 확산을 사용하고, 해시 그리드와 희소 가속 구조를 사용하여 이를 가속합니다.
2단계:거친 신경 표현에서 초기화된 텍스처 메시 모델은 고해상도 잠재 확산 모델과 상호 작용하는 효율적인 미분 가능 렌더러를 통해 최적화됩니다.
기술 발전은 여전히 한계를 극복해야 합니다.
텍스트-3D AI는 점진적으로 출시되고 있지만, 텍스트 기반 3D 합성은 아직 초기 개발 단계에 있습니다.업계에는 관련 업무를 보다 공정하게 평가하는 데 사용할 수 있는 보편적으로 인정된 벤치마크가 없습니다.
Point·E는 빠른 텍스트-3D 합성에 매우 중요한 의미를 갖습니다.이를 통해 처리 효율성이 크게 향상되고 컴퓨팅 전력 소비가 감소합니다.
그러나 그것은 부인할 수 없습니다E 지점에는 아직 몇 가지 한계가 있습니다.예를 들어, 파이프라인에는 합성 렌더링이 필요하고 생성된 3D 포인트 클라우드는 해상도가 낮아 세밀한 모양이나 텍스처를 캡처하기에 충분하지 않습니다.
텍스트-3D 합성의 미래에 대해 어떻게 생각하시나요? 미래의 개발 추세는 어떻게 될까요? 토론을 위해 댓글 섹션에 댓글을 남겨주세요.