PyTorch 2.0이 출시되었습니다. 컴파일하고, 컴파일하고, 컴파일하세요!

한눈에 보는 콘텐츠: 어젯밤에 열린 PyTorch Conference 2022에서 PyTorch 2.0이 공식 출시되었습니다. 이 글에서는 PyTorch 2.0과 1.x의 가장 큰 차이점을 알아보겠습니다. 키워드: PyTorch 2.0 컴파일러 머신 러닝 이 글은 WeChat 공식 계정 HypeAI에 처음 게시되었습니다.
PyTorch 컨퍼런스 2022에서 PyTorch는 공식적으로 PyTorch 2.0을 출시했습니다. 이 행사 전체의 "컴파일러" 비율이 매우 높았습니다. 이전 버전 1.x와 비교했을 때 2.0은 "파괴적인" 변화를 겪었습니다.
PyTorch 2.0에서는 PyTorch를 사용하는 방식을 바꾸기에 충분한 새로운 기능이 많이 출시되었습니다.torch.compile을 통해 컴파일 모드를 추가하면서 동일한 eager 모드와 사용자 경험을 제공합니다.모델은 학습 및 추론 중에 가속화되어 Dynamic Shapes 및 Distributed에 대한 더 나은 성능과 지원을 제공합니다.
이 문서에서는 PyTorch 2.0에 대한 자세한 소개를 제공합니다.
너무 길어서 읽을 수가 없다
- PyTorch 2.0은 컴파일을 크게 지원하면서도 원래의 장점을 그대로 유지합니다.
- torch.compile은 단 한 줄의 코드로 컴파일을 실행할 수 있는 선택적 함수입니다.
- 4가지 중요 기술: TorchDynamo, AOTAutograd, PrimTorch 및 TorchInductor
- 5년 전에도 컴파일을 시도했지만, 결과가 만족스럽지 못했습니다.
- PyTorch 1.x 코드는 2.0*으로 마이그레이션할 필요가 없습니다. PyTorch 2.0 안정 버전은 내년 3월에 출시될 예정입니다.
더 빠르고, 더 나은, 컴파일된 지원
어젯밤 PyTorch 컨퍼런스 2022에서torch.compile이 공식적으로 출시되었습니다.이를 통해 PyTorch의 성능이 더욱 향상되고 PyTorch의 일부가 C++에서 Python으로 다시 이동되기 시작했습니다.
PyTorch 2.0의 최신 기술은 다음과 같습니다.
TorchDynamo, AOTAutograd, PrimTorch 및 TorchInductor.
1. 토치다이나모
Python 프레임 평가 후크의 도움으로 PyTorch 프로그램을 안전하게 얻을 수 있습니다. 이 중요한 혁신은 PyTorch가 지난 5년간 안전한 그래프 캡처를 위한 연구 개발 결과를 요약한 것입니다.
2. AOTAutograd
PyTorch 자동 등급 엔진을 추적 자동 차이로 오버로드하여 고급 역방향 추적을 생성합니다.
3. 프림토치
2000개가 넘는 PyTorch 연산자는 약 250개의 기본 연산자로 구성된 폐쇄형 집합으로 요약되며, 개발자는 이러한 연산자에 대한 완전한 PyTorch 백엔드를 구축할 수 있습니다. PrimTorch는 PyTorch 함수나 백엔드를 작성하는 과정을 크게 단순화합니다.
4. 토치인덕터 여러 가속기와 백엔드에 대한 빠른 코드를 생성하는 딥 러닝 컴파일러입니다. NVIDIA GPU의 경우 OpenAI Triton을 핵심 구성 요소로 사용합니다.
TorchDynamo, AOTAutograd, PrimTorch, TorchInductor는 Python으로 작성되었습니다.또한 동적 모양(다양한 크기의 벡터를 다시 컴파일하지 않고도 전송할 수 있는 기능)을 지원하므로 유연하고 배우기 쉬워 개발자와 공급업체의 진입 장벽이 낮아집니다.
이러한 기술을 검증하려면PyTorch는 공식적으로 머신 러닝 분야에서 163개의 오픈 소스 모델을 사용합니다.여기에는 이미지 분류, 객체 감지, 이미지 생성과 같은 작업과 언어 모델링, 질의응답, 시퀀스 분류, 추천 시스템, 강화 학습과 같은 다양한 NLP 작업이 포함됩니다.이러한 벤치마크는 세 가지 범주로 구분됩니다.
- HuggingFace 트랜스포머의 46개 모델
- TIMM의 61개 모델: Ross Wightman의 SoTA PyTorch 이미지 모델 컬렉션
- TorchBench의 56개 모델: GitHub의 인기 있는 저장소 컬렉션입니다.
오픈 소스 모델의 경우,PyTorch는 공식적으로 어떠한 변경도 하지 않았지만 캡슐화를 위해 torch.compile 호출을 추가했습니다.
다음으로, PyTorch 엔지니어는 이러한 모델에서 속도를 측정하고 정확도를 검증했습니다. 속도 향상은 데이터 유형에 따라 달라질 수 있기 때문입니다.따라서 공식적인 속도 향상은 float32와 AMP(자동 혼합 정밀도) 모두에서 측정되었습니다.실제로는 AMP가 더 일반적이므로 테스트 비율은 0.75 * AMP + 0.25 * float32로 설정되었습니다.
이 163개의 오픈소스 모델 중,torch.compile은 93% 모델에서 정상적으로 실행될 수 있습니다.실행 후, 이 모델은 NVIDIA A100 GPU에서 실행 속도가 43% 향상되었습니다. Float32 정밀도에서 실행 속도는 평균 21%만큼 증가합니다. AMP 정밀도에서는 실행 속도가 평균 51%만큼 증가합니다.
참고: 데스크톱용 GPU(예: NVIDIA 3090)에서는 측정된 속도가 서버용 GPU(예: A100)보다 낮습니다. 현재 PyTorch 2.0의 기본 백엔드 TorchInductor는 이미 CPU와 NVIDIA Volta 및 Ampere GPU를 지원하지만, 다른 GPU, xPU 또는 이전 NVIDIA GPU는 현재 지원하지 않습니다.
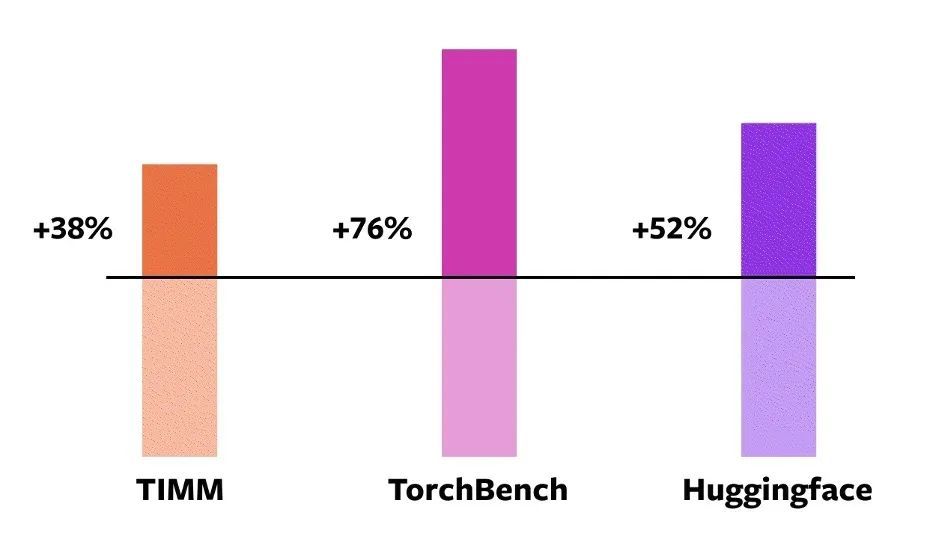 NVIDIA A100 GPU eager mode torch.compile 다양한 모델에 대한 속도 향상
NVIDIA A100 GPU eager mode torch.compile 다양한 모델에 대한 속도 향상
torch.compile을 온라인으로 시도해 보세요.개발자는 야간 바이너리 파일을 통해 설치하고 사용해 볼 수 있습니다. PyTorch 2.0 안정 버전은 2023년 3월 초에 출시될 예정입니다.
PyTorch 2.x 로드맵에서는 컴파일 모드의 성능과 확장성이 앞으로도 계속해서 강화되고 개선될 것입니다.
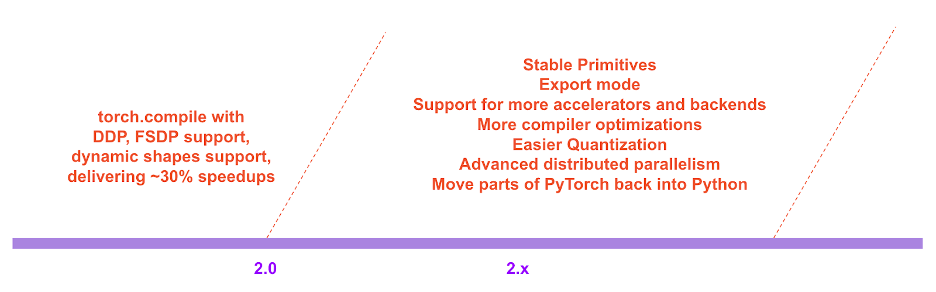 PyTorch 2.x 로드맵
PyTorch 2.x 로드맵
개발 배경
PyTorch의 개발 철학은 항상 유연성과 해킹 가능성을 우선시하고 성능은 그 다음으로 두는 것이었습니다.다음에 전념합니다:
1. 고성능의 긴급 실행
2. 내부 구조를 지속적으로 파이썬화합니다.
3. 분산, 자동 분산, 데이터 로딩, 가속기 등의 우수한 추상화
PyTorch가 2017년에 도입된 이래로 하드웨어 가속기(예: GPU) 덕분에 계산 속도는 약 15배, 메모리 접근 속도는 약 2배 빨라졌습니다.
고성능의 즉시 실행을 유지하기 위해 PyTorch의 내부 콘텐츠 대부분을 C++로 옮겨야 했는데, 이로 인해 PyTorch의 해킹 가능성이 감소하고 개발자가 코드 기여에 참여할 수 있는 문턱이 높아졌습니다.
PyTorch 임원진은 처음부터 즉시 실행의 성능 한계를 알고 있었습니다. 2017년 7월, 관계자들은 PyTorch용 컴파일러 개발 작업을 시작했습니다. 컴파일러는 PyTorch 경험을 저하시키지 않고도 PyTorch 프로그램의 실행 속도를 높여야 합니다.가장 중요한 기준은 일정 수준의 유연성을 유지하는 것이었습니다. 즉, 개발자들이 널리 사용하는 동적 모양과 동적 프로그램을 지원하는 것입니다.

PyTorch 기술 세부 사항
PyTorch가 출시된 이후로 여러 컴파일러 프로젝트가 PyTorch로 빌드되었습니다.이러한 컴파일러는 3가지 범주로 나눌 수 있습니다.
- 그래프 수집
- 그래프 낮추기
- 그래프 편집
그 중에서도 그래프 구조의 습득이 가장 큰 어려움에 직면한다.
지난 5년 동안 우리는 torch.jit.trace, TorchScript, FX 추적 및 Lazy Tensors를 시도해 보았지만, 그 중 일부는 유연하지만 충분히 빠르지 않았고, 일부는 충분히 빠르지만 유연하지 않았으며, 일부는 빠르지도 유연하지도 않았고, 일부는 사용자 경험이 좋지 않았습니다.
TorchScript는 유망하지만,하지만 이를 위해서는 많은 코드와 종속성 수정이 필요하며, 실현 가능성이 낮습니다.
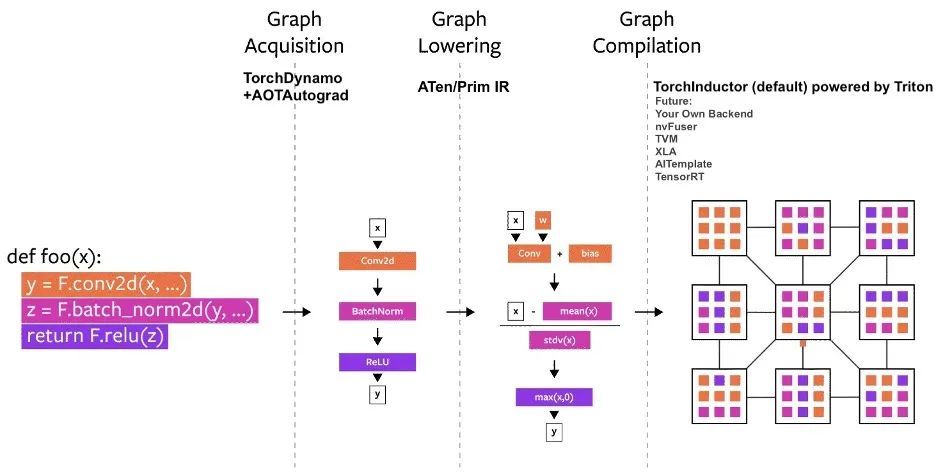 PyTorch 컴파일 프로세스 다이어그램
PyTorch 컴파일 프로세스 다이어그램
TorchDynamo: 그래프 구조를 안정적이고 빠르게 얻습니다.
TorchDynamo는 PEP-0523에 도입된 프레임 평가 API라는 CPython 기능을 사용합니다. 해당 공무원은 PyTorch로 작성된 7,000개 이상의 Github 프로젝트를 검증 세트로 사용하여 Graph Capture에서의 효과를 검증하기 위해 데이터 기반 접근 방식을 채택했습니다.
실험 결과TorchDynamo는 99% 시간 안에 그래프 구조를 정확하고 안전하게 얻을 수 있으며 오버헤드는 무시할 만합니다.원래 코드를 수정할 필요가 없기 때문입니다.
TorchInductor: 실행별 정의 IR을 통한 더 빠른 코드 생성
점점 더 많은 개발자들이 고성능 커스텀 커널을 작성하고 있습니다.트리톤 언어를 사용할 수 있습니다.또한, 관계자는 PyTorch 2.0의 새로운 컴파일러 백엔드에서 PyTorch eager와 유사한 추상화를 사용하고 PyTorch의 광범위한 기능을 지원할 만큼 충분한 일반 성능을 갖기를 바라고 있습니다.
TorchInductor는 Pythonic의 실행별 정의 루프 수준 IR을 사용하여 PyTorch 모델을 GPU의 생성된 Triton 코드와 CPU의 C++/OpenMP에 자동으로 매핑합니다.
TorchInductor의 코어 루프 수준 IR은 약 50개의 연산자만 포함하고 있으며 Python으로 구현되어 있어 해킹과 확장성이 매우 뛰어납니다.
AOTAutograd: 사전 그래프를 위한 Autograd 재사용
학습 속도를 높이기 위해 PyTorch 2.0은 사용자 수준 코드뿐만 아니라 역전파 알고리즘도 캡처합니다. 이미 검증된 PyTorch 오토그래프 시스템을 활용한다면 더욱 좋을 것 같습니다.
AOTAutograd는 PyTorch torch_dispatch 확장 메커니즘을 사용하여 Autograd 엔진을 추적합니다.개발자가 "미리" 역방향 패스를 캡처할 수 있으므로 개발자가 TorchInductor를 사용하여 정방향 및 역방향 패스를 가속화할 수 있습니다.
PrimTorch: 안정적인 기본 연산자
PyTorch 백엔드를 작성하는 것은 쉽지 않습니다. Torch에는 1,200개 이상의 연산자가 있으며, 각 연산자의 다양한 오버로드를 고려하면 그 수는 2,000개 이상에 달합니다.
 2000개 이상의 PyTorch 연산자 분류 개요
2000개 이상의 PyTorch 연산자 분류 개요
그러므로 백엔드나 크로스커팅 기능을 작성하는 것은 시간이 많이 걸리는 작업이 됩니다. PrimTorch는 더 작고 안정적인 운영자 세트를 정의하기 위해 노력합니다. PyTorch 프로그램은 지속적으로 이러한 연산자 집합으로 축소될 수 있습니다. 공식적인 목표는 두 가지 연산자 세트를 정의하는 것입니다.
* Prim ops에는 약 250명의 비교적 저수준 운영자가 포함되어 있습니다. 이러한 연산자는 충분히 저수준이므로 컴파일러에 더 적합합니다. 개발자는 좋은 성능을 달성하기 위해 이러한 연산자를 융합해야 합니다.
* ATen ops에는 직접 출력에 적합한 약 750개의 표준 연산자가 포함되어 있습니다. 이러한 연산자는 ATen 수준에서 통합된 백엔드나 기본 연산자 세트(예: Prim op)에서 성능을 복구하도록 컴파일되지 않은 백엔드에 적합합니다.
자주 묻는 질문
1. PyTorch 2.0을 설치하는 방법은? 추가 요구 사항은 무엇입니까?
최신 야간 버전을 설치하세요.
쿠다 11.7
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117쿠다 11.6
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu116CPU
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cpu2. PyTorch 2.0 코드는 1.x와 하위 호환이 되나요?
예, 2.0에서는 PyTorch 워크플로를 수정할 필요가 없으며 코드 한 줄만 수정하면 됩니다. 모델 = torch.compile(모델)그런 다음 2.0 스택을 사용하여 모델을 최적화하고 다른 PyTorch 코드로 원활하게 실행할 수 있습니다. 이 옵션은 필수가 아니며 개발자는 이전 버전을 계속 사용할 수 있습니다.
3. PyTorch 2.0은 기본적으로 활성화되어 있나요?
아니요, PyTorch 코드에서 단일 함수 호출로 모델을 최적화하여 2.0을 명시적으로 활성화해야 합니다.
4. PT1.X 코드를 PT2.0으로 마이그레이션하는 방법은 무엇입니까?
이전 코드는 마이그레이션이 필요하지 않습니다. 2.0에 도입된 새로운 컴파일 모드 기능을 사용하려면 먼저 한 줄의 코드로 모델을 최적화할 수 있습니다.모델 = torch.compile(모델).
속도 향상은 주로 훈련 과정에 반영됩니다. 모델이 즉시 모드보다 빠르게 실행되면 추론에 사용할 수 있다는 의미입니다.
import torch
def train(model, dataloader):
model = torch.compile(model)
for batch in dataloader:
run_epoch(model, batch)
def infer(model, input):
model = torch.compile(model)
return model(\*\*input)5. PyTorch 2.0에서 더 이상 지원되지 않는 기능은 무엇입니까?
현재 PyTorch 2.0은 아직 안정적이지 않으며 여전히 야간 버전입니다. torch.compile에서 동적 모양에 대한 지원은 아직 초기 단계이며 2023년 3월에 출시될 안정적인 2.0 버전까지는 권장되지 않습니다.
즉, 정적 형태의 워크로드라도 여전히 컴파일 모드로 빌드되므로 일부 버그가 발생할 수 있습니다. 충돌이 발생하는 코드 부분에 대해서는 컴파일 모드를 비활성화하고 문제를 제출하세요.
문제 제출 포털:https://github.com/pytorch/pytorch/issues
위의 내용은 PyTorch 2.0에 대한 자세한 소개입니다. PyTorch 2.0 시작하기 소개는 나중에 완료하겠습니다. 계속해서 저희를 팔로우해주세요!
또한 WeChat에서 Hyperai01을 검색하여 Neural Star와 함께 PyTorch 기술 개발 그룹 토론에 참여할 수 있습니다.