Command Palette
Search for a command to run...
PyTorch의 새로운 라이브러리 TorchMultimodal 사용 지침: 다중 모드 일반 모델 FLAVA를 100억 개의 매개변수로 확장

이전 기사에서는 TorchMultimodal을 소개했습니다. 오늘은 Torch Distributed 기술의 지원을 받아 TorchMultimodal 라이브러리의 멀티모달 기본 모델을 확장하는 방법을 보여주는 구체적인 사례부터 시작해 보겠습니다.
최근 몇 년 동안 대형 모델이 많은 관심을 모으는 연구 분야가 되었습니다. 자연어 처리를 예로 들면, 언어 모델은 수억 개의 매개변수(BERT)에서 수천억 개의 매개변수(GPT-3)로 발전하여 다운스트림 작업의 성능을 개선하는 데 중요한 역할을 했습니다.
업계에서는 대규모 언어 모델을 확장하는 방법에 대한 광범위한 연구가 진행되었습니다. 비슷한 추세가 시야에서도 관찰되며, 점점 더 많은 개발자가 변환기 기반 모델(예: Vision Transformer 및 Masked Auto Encoders)을 사용하고 있습니다.
당연히 대규모 모델이 개발됨에 따라 단일 모달리티(예: 텍스트, 이미지, 비디오)에 대한 연구가 지속적으로 개선되었으며 프레임워크도 더 큰 모델에 빠르게 적응했습니다.
동시에 이미지-텍스트 검색, 시각적 질의응답, 시각적 대화, 텍스트-이미지 생성 등의 작업이 실제 세계에 적용되면서 다중 모달리티에 대한 관심이 점점 높아지고 있습니다.
다음 단계는 대규모 멀티모달 모델을 훈련하는 것입니다. 이 분야에서는 OpenAI의 CLIP, Google의 Parti, Meta의 CM3 등 일부 노력도 있었습니다.
이 문서에서는 사례 연구를 통해 PyTorch 분산 기술을 사용하여 FLAVA를 100억 개의 매개변수로 확장하는 방법을 보여줍니다.
추가 자료:HyperAI: Meta에서 사용하는 FX 도구 살펴보기: 그래프 변환을 통한 PyTorch 모델 최적화
편집하다
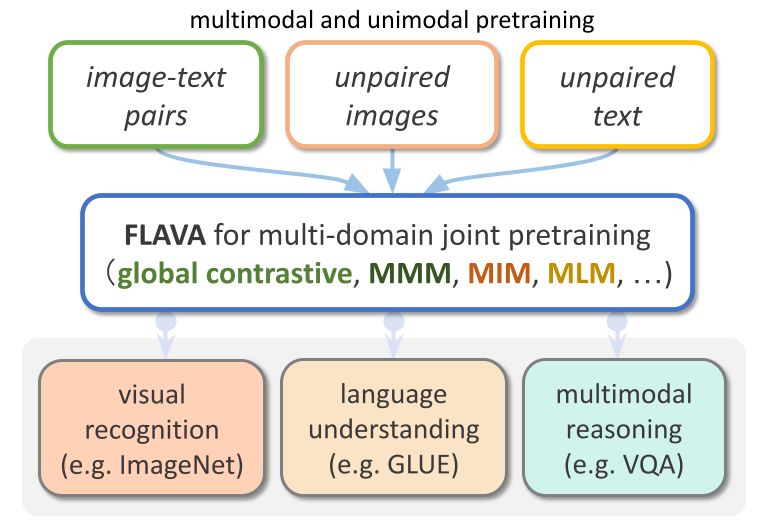
FLAVA는 TorchMultimodal에서 사용 가능한 비전 및 언어 기반 모델입니다.
FLAVA는 단일 모달 및 다중 모달 벤치마크에서 뛰어난 성능 이점을 보여주었습니다. 이 문서에서는 관련 코드 예제를 통해 FLAVA를 확장하는 방법을 보여드리겠습니다.
자세한 내용은 코드를 참조하세요.
multimodal/examples/flava/native at main · facebookresearch/multimodal · GitHub
FLAVA 개요 확장
FLAVA는 변환기 기반 이미지 및 텍스트 인코더와 변환기 기반 멀티모달 퓨전 모듈로 구성된 기본 멀티모달 모델입니다.
FLAVA는 마스크된 언어, 이미지, 모델이 맥락에서 원래 입력을 재구성해야 하는 다중 모드 모델 손실(자체 지도 학습)을 포함하여 다양한 손실을 가진 단일 모드 및 다중 모드 데이터 모두에 대해 사전 학습되었습니다.
또한, 정렬된 이미지-텍스트 쌍의 긍정적 및 부정적 예를 포함하는 이미지 텍스트 매칭 손실과 CLIP 스타일 대조 손실을 사용합니다.
다중 모드 작업(예: 이미지-텍스트 검색) 외에도 FLAVA는 단일 모드 벤치마크(예: NLP 및 시각적 이미지 분류의 GLUE 작업)에서도 우수한 성능을 보여줍니다.
편집하다
원래 FLAVA 모델은 약 3억 5천만 개의 매개변수를 가지고 있었고 이미지와 텍스트 인코더 모두에 ViT-B16 구성을 사용했습니다.
참조:https://arxiv.org/pdf/2010.11929.pdf
멀티모달 퓨전 변환기는 동일한 싱글모달 인코더를 사용하지만, 레이어 수는 이전 것의 절반에 불과합니다. PyTorch 개발팀은 더 큰 ViT 변형을 수용하기 위해 인코더의 크기를 늘리는 방법을 모색해 왔습니다.
FLAVA를 확장하는 또 다른 측면은 배치 크기를 늘리는 것입니다. FLAVA는 일반적으로 많은 수의 크기로만 사용 가능한 배치 내 부정적 대조 손실을 현명하게 활용합니다.
참조:https://openreview.net/pdfid=U2exBrf_SJh
일반적으로 최대 학습 효율성 또는 처리량은 가능한 가장 큰 배치 크기에 가깝게 작동할 때 달성되는데, 이는 사용 가능한 GPU 메모리 양에 따라 결정됩니다(실험 섹션 참조).
다음 표는 다양한 모델 구성의 출력을 보여줍니다. 이를 통해 우리는 각 구성에 대해 메모리에 저장될 수 있는 최대 배치 크기를 실험적으로 결정했습니다.

편집하다
최적화 개요
PyTorch는 모델을 효율적으로 확장할 수 있는 여러 가지 기본 기술을 제공합니다. 다음 섹션에서는 세 가지 접근 방식을 자세히 설명하고 이러한 기술을 적용하여 FLAVA 모델을 100억 개의 매개변수로 확장하는 방법을 보여줍니다.
분산 데이터 병렬 처리
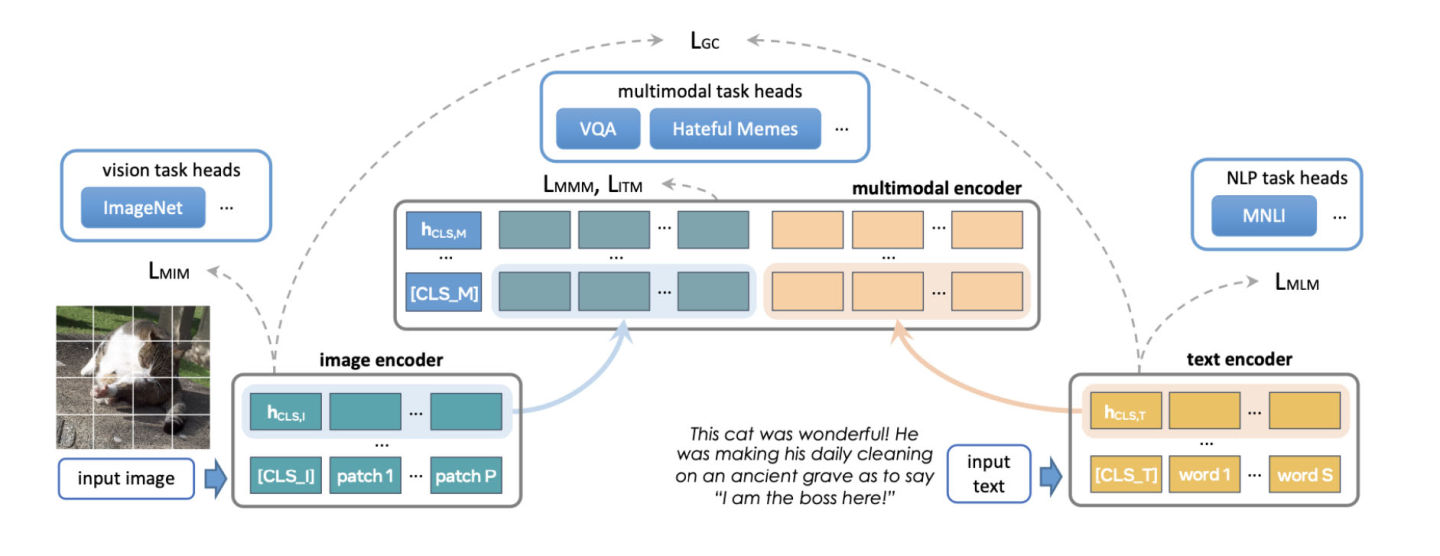
분산 학습을 위한 일반적인 시작점은 데이터 병렬 처리입니다. 데이터 병렬 처리는 GPU 간에 모델을 복제하고 데이터 세트를 분할합니다. 다양한 GPU는 서로 다른 데이터 파티션을 병렬로 처리하고 모델 가중치가 업데이트되기 전에 모든 reduce를 통해 그래디언트를 동기화합니다.
다음 그림은 데이터 병렬 처리 과정(전방 반복, 후방 반복, 가중치 업데이트 단계)을 보여줍니다.

편집하다
데이터 병렬 처리를 달성하기 위해 PyTorch는 기본 API인 DistributedDataParallel(DDP)을 제공합니다. 이는 아래와 같이 모듈 래퍼로 사용할 수 있습니다.
from torchmultimodal.models.flava.model import flava_model_for_pretraining
import torch
import torch.distributed as dist
model = flava_model_for_pretraining().cuda()
# Initialize PyTorch Distributed process groups
# Please see https://pytorch.org/tutorials/intermediate/dist_tuto.html for details
dist.init_process_group(backend=”nccl”)
# Wrap model in DDP
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[torch.cuda.current_device()])완전 분할 데이터 병렬 처리
학습 애플리케이션의 GPU 메모리 사용량은 대략 모델 입력, 중간 활성화 저장소(경사 계산에 필요), 모델 매개변수, 경사, 최적화 상태로 구분할 수 있습니다.
모델을 확장할 때 일반적으로 이러한 요소들이 함께 추가됩니다. 단일 GPU에서 메모리가 부족해지면 DDP를 사용하여 모델을 확장하면 모든 GPU에서 매개변수, 그래디언트, 최적화 상태를 복제하기 때문에 메모리가 부족해질 수 있습니다.
복사를 줄이고 GPU 메모리를 절약하기 위해 모델 매개변수, 그래디언트, 최적화 상태를 모든 GPU에 분할하고 각 GPU가 하나의 분할만 관리하도록 할 수 있습니다. 이 방법은 Microsoft에서 제안한 ZeRO-3를 참조합니다.
이 접근 방식에 대한 PyTorch 기본 구현은 PyTorch 1.12에서 베타 기능으로 출시된 FullyShardedDataParallel(FSDP) API로 제공됩니다.
모듈의 전방 및 후방 반복 작업 동안 FSDP는 계산 요구 사항에 따라 모델 매개변수를 통합하고(all-gather 사용) 계산 후에 다시 분할합니다. 이는 분산-감소 앙상블을 사용하여 그래디언트를 동기화하고 샤드의 그래디언트가 전역적으로 평균화되도록 보장합니다. FSDP에서 모델의 순방향 및 역방향 반복 프로세스는 다음과 같습니다.

편집하다
FSDP를 사용하는 경우 특정 하위 모듈이 분할될지 여부를 제어하기 위해 모델의 하위 모듈을 API로 캡슐화해야 합니다. FSDP는 즉시 사용 가능한 자동 래핑 API, 여러 래핑 정책 및 정책 작성 기능을 제공합니다.
다음 예제에서는 FSDP로 FLAVA 모델을 래핑하는 방법을 보여줍니다. 자동 래핑 정책을 지정합니다: transformer_auto_wrap_policy . 이를 통해 단일 변환기 계층(TransformerEncoderLayer), 이미지 변환기(ImageTransformer), 텍스트 인코더(BERTTextEncoder), 멀티모달 인코더(FLAVATransformerWithoutEmbeddings)가 단일 FSDP 단위로 캡슐화됩니다.
이는 효율적인 메모리 관리를 위해 재귀적 캡슐화 접근 방식을 사용합니다. 예를 들어, 단일 변압기 계층의 전방 또는 후방 반복이 완료된 후 매개변수가 삭제되어 메모리가 확보되고 최대 메모리 사용량이 줄어듭니다.
FSDP는 또한 이 예에서 limit_all_gathers를 사용하는 것과 같이 애플리케이션의 성능을 조정하기 위한 몇 가지 구성 가능한 옵션을 제공합니다. 이를 통해 모든 모델 매개변수의 조기 수집을 방지하고 애플리케이션의 메모리 부담을 줄일 수 있습니다.
import torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torchmultimodal.models.flava.text_encoder import BertTextEncoder
from torchmultimodal.models.flava.image_encoder import ImageTransformer
from torchmultimodal.models.flava.transformer import FLAVATransformerWithoutEmbeddings
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining().cuda()
dist.init_process_group(backend=”nccl”)
model = FSDP(
model,
device_id=torch.cuda.current_device(),
auto_wrap_policy=partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
TransformerEncoderLayer,
ImageTransformer,
BERTTextEncoder,
FLAVATransformerWithoutEmbeddings
},
),
limit_all_gathers=True,
)활성화 체크포인팅
위에서 언급했듯이 중간 활성화 저장소, 모델 매개변수, 그래디언트 및 최적화기 상태는 GPU 메모리 사용량에 영향을 미칩니다. FSDP는 마지막 세 가지로 인해 발생하는 메모리 소모를 줄일 수 있지만, 활성화로 인해 사용되는 메모리는 줄일 수 없습니다. 활성화에 사용되는 메모리는 배치 크기나 숨겨진 레이어의 수에 따라 증가합니다.
활성화 검사점은 특정 검사점이 지정된 모듈의 메모리에 활성화를 보관하는 대신 역방향 반복 작업 중에 활성화를 다시 계산하여 메모리 사용량을 줄입니다.
예를 들어, 27억 개의 매개변수 모델에 활성화 체크포인팅을 적용함으로써 순방향 반복 이후의 최대 활성 메모리가 4배로 감소했습니다.
PyTorch는 래퍼 기반 활성화 체크포인팅 API를 제공합니다. checkpoint_wrapper를 사용하면 사용자가 단일 모듈을 검사로 래핑할 수 있고, apply_activation_checkpointing을 사용하면 사용자가 전체 모듈에서 모듈을 검사로 래핑하는 전략을 지정할 수 있습니다.
이 두 API는 모델 정의 코드를 변경할 필요가 없으므로 대부분의 모델에 적용할 수 있습니다.
하지만 모듈 내의 특정 기능에 대한 체크포인트와 같이 체크포인트가 지정된 세그먼트에 대해 더 세부적인 제어가 필요한 경우, 모델 코드를 수정해야 하는 torch.utils.checkpoint API를 사용할 수 있습니다.
단일 FLAVA 변환기 계층(TransformerEncoderLayer로 표시)에 활성화 체크포인팅 래퍼를 적용하는 방법은 아래와 같습니다.
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import apply_activation_checkpointing, checkpoint_wrapper, CheckpointImpl
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining()
checkpoint_tformer_layers_policy = lambda submodule: isinstance(submodule, TransformerEncoderLayer)
apply_activation_checkpointing(
model,
checkpoint_wrapper_fn=checkpoint_wrapper,
check_fn=checkpoint_tformer_layers_policy,
)
위에 표시된 것처럼 FLAVA 변환기 계층을 활성화 체크포인팅으로 래핑하고 전체 모델을 FSDP로 래핑하면 FLAVA를 100억 개의 매개변수로 확장할 수 있습니다.
실험
위에서 언급한 다양한 최적화 방법에 대해 시스템 성능에 미치는 영향을 추가로 실험해 보겠습니다.
배경:
- 8개의 A100 40GB GPU를 사용하는 단일 노드 사용
- 1000번의 사전 학습 반복 실행
- bfloat16 데이터 유형을 사용한 PyTorch 혼합 정밀도 학습(자동 혼합 정밀도)
- A100에서 matmul 성능을 개선하기 위해 TensorFloat32 형식을 활성화하세요.
- 처리량을 초당 처리되는 평균 항목 수로 정의합니다(처리량 측정 시 처음 100번의 반복은 무시합니다).
- 훈련 융합과 다운스트림 작업 지표에 미치는 영향은 미래 연구의 새로운 방향으로 활용될 것입니다.
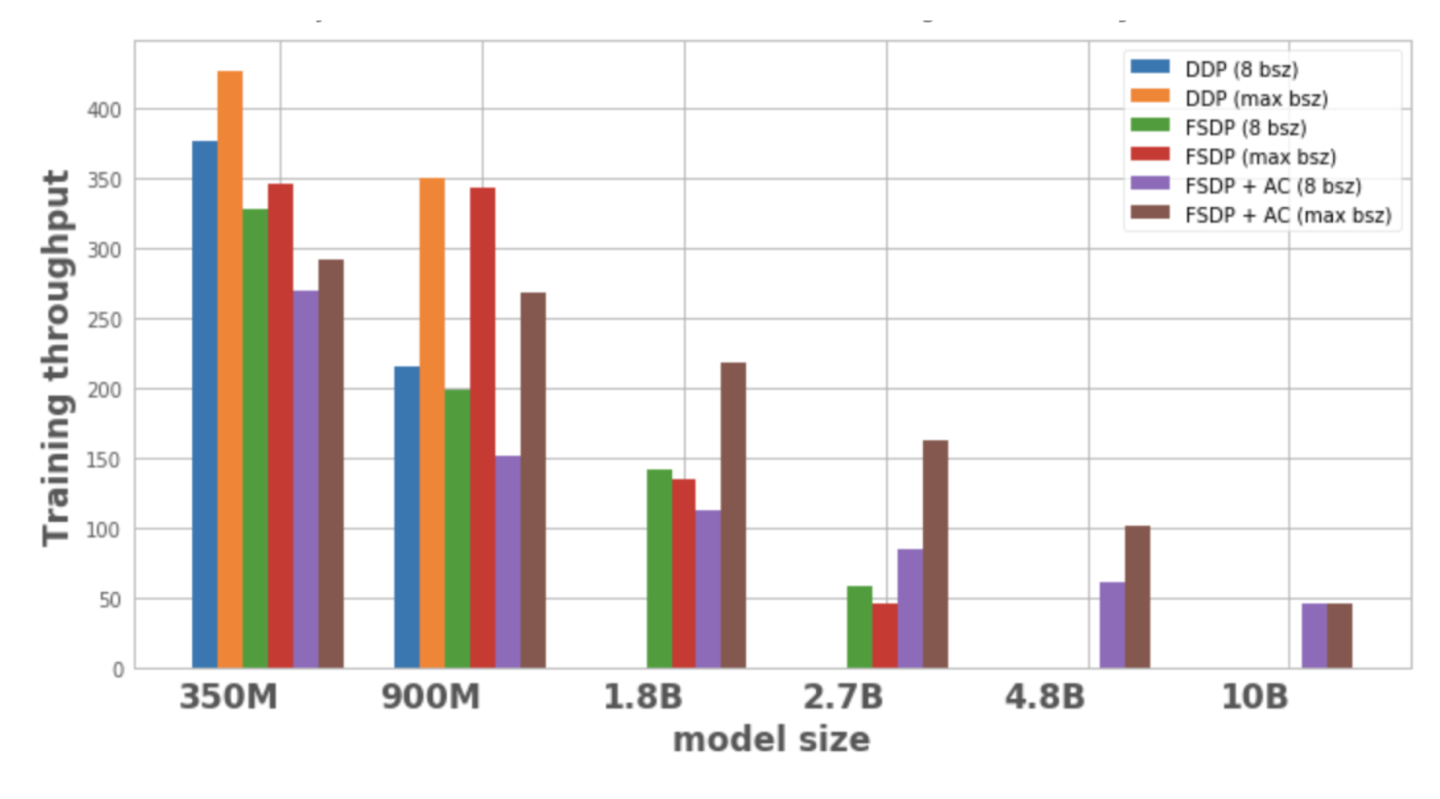
그림 1은 각 모델 구성 및 최적화에 대한 처리량을 보여줍니다. 로컬 배치 크기는 8이며, 이는 1개 노드에서 가능한 최대 배치 크기입니다. 최적화된 모델 변형에는 데이터 포인트가 없으므로 단일 노드에서 모델을 학습할 수 없습니다.
편집하다
그림 1: 다양한 구성에서의 교육 처리량
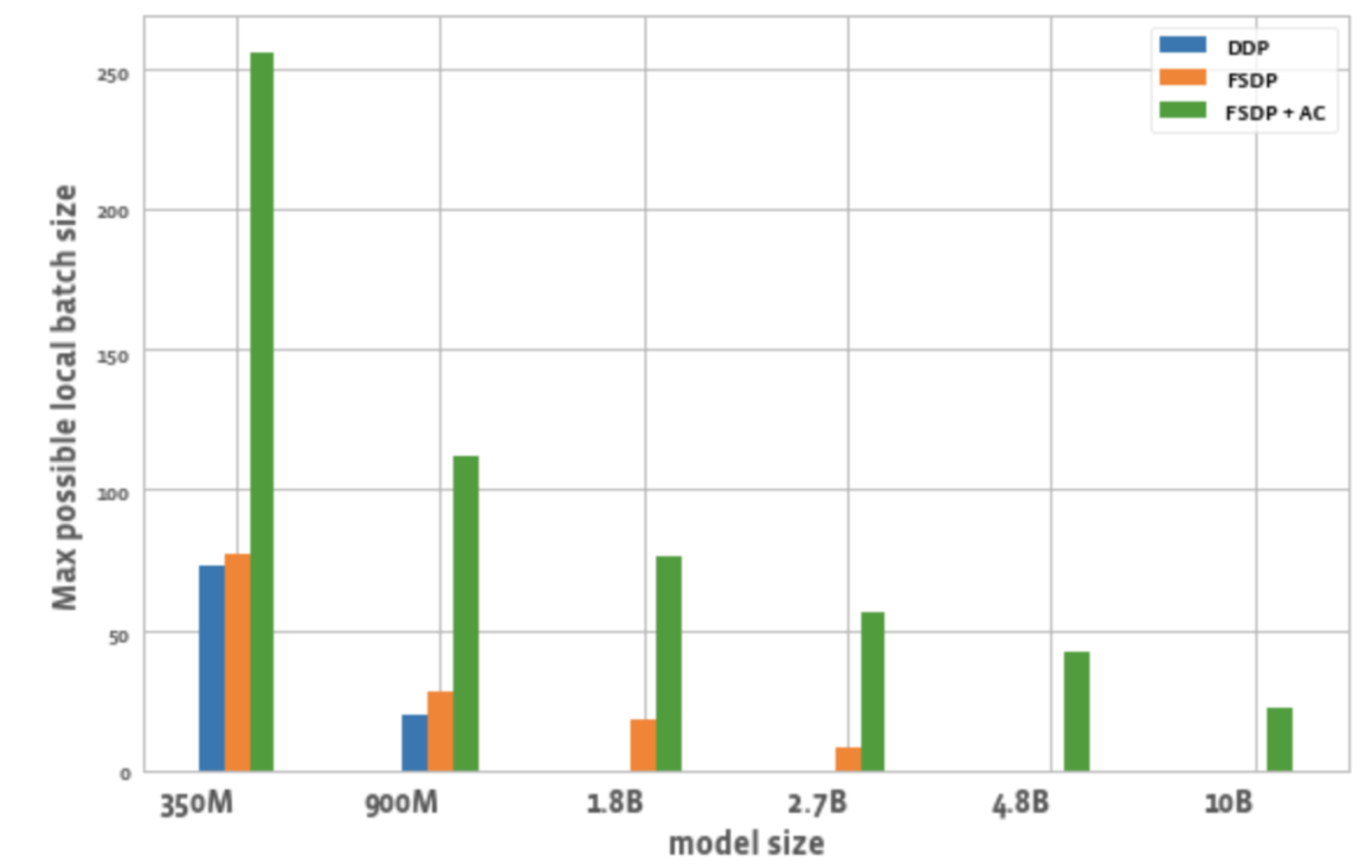
그림 2는 각 최적화에서 모든 GPU에 대해 가능한 최대 배치 크기를 보여줍니다.
편집하다
그림 2: 다양한 구성에서 가능한 최대 로컬 배치 크기
이것으로부터 우리는 다음을 관찰할 수 있습니다.
1. 모델 크기 확장:
DDP는 하나의 노드에 350M 및 900M 모델만 수용할 수 있습니다. FSDP를 사용하면 메모리를 절약할 수 있으므로 DDP보다 3배 더 큰 모델(즉, 18억 개와 27억 개의 변형)을 훈련할 수 있습니다. 활성화 체크포인팅(AC)을 FSDP와 결합하면 DDP보다 약 10배 더 큰 더 큰 모델(예: 4.8B 및 10B 변형)을 훈련할 수 있습니다.
2. 처리량:
– 배치 크기가 8인 작은 모델의 경우 DDP의 처리량은 FSDP보다 약간 높거나 같으며, 이는 FSDP에 필요한 추가 통신으로 설명할 수 있습니다. FSDP와 AC를 결합하면 처리량이 가장 낮습니다. 이는 AC가 역방향 반복 프로세스 동안 체크포인트가 지정된 순방향 반복 채널을 다시 실행하여 메모리를 절약하기 위해 추가 계산을 희생하기 때문입니다. 그러나 2.7B 모델의 경우 FSDP + AC가 FSDP만 사용할 때보다 실제로 처리량이 더 높습니다. FSDP를 적용한 2.7B 모델은 배치 크기가 8일 때도 메모리 제한에 가까워서 CUDA malloc 재시도가 발생하고, 이로 인해 학습 속도가 느려집니다. AC는 재시도하지 못하게 하는 메모리 압력을 줄이는 데 도움이 됩니다.
– DDP 및 FSDP + AC의 경우 배치 크기가 증가함에 따라 모델의 처리량이 증가합니다. FSDP의 더 작은 변형에도 동일한 것이 적용됩니다. 그러나 1.8B 및 2.7B 매개변수 모델의 경우 배치 크기를 늘리면 처리량이 감소합니다. 잠재적인 이유 중 하나는 메모리 한계에 도달했을 때 PyTorch의 CUDA 메모리 관리가 cudaMalloc 호출을 다시 시도하거나 비용이 많이 드는 조각 모음을 실행하여 작업 부하의 메모리 요구 사항을 처리할 수 있는 여유 메모리 블록을 찾아야 할 수 있으며, 이로 인해 학습 속도가 느려질 수 있다는 것입니다.
– FSDP로만 학습할 수 있는 대규모 모델(1.8B, 2.7B, 4.8B)의 경우 가장 높은 처리량 설정은 FSDP+AC로 가장 큰 배치 크기로 확장하는 것입니다. 10B의 경우, 작은 배치 크기와 최대 배치 크기에 대한 처리량이 거의 동일한 것을 확인할 수 있습니다. AC는 계산 노력을 증가시키고, 최대 배치 크기는 CUDA 메모리 제한에서 실행되기 때문에 비용이 많이 드는 조각 모음 작업을 초래할 수 있기 때문입니다. 그러나 이러한 대규모 모델의 경우 배치 크기의 증가는 이러한 오버헤드를 상쇄하고도 남습니다.
3. 배치 크기:
DDP와 비교했을 때 FSDP만으로는 약간 더 높은 배치 크기를 달성할 수 있습니다. 350M 매개변수 모델의 경우 FSDP+AC를 사용하면 DDP보다 3배 더 큰 배치 크기를 달성할 수 있고, 900M 매개변수 모델의 경우 5.5배 더 큰 배치 크기를 달성할 수 있습니다. 10B를 사용하더라도 최대 배치 크기는 약 20으로 꽤 좋습니다. FSDP+AC는 기본적으로 더 적은 GPU로 더 큰 글로벌 배치 크기를 달성할 수 있으며, 이는 대조 학습 작업에 특히 효과적입니다.
결론적으로
다중 모드 기반 모델의 개발로 인해 모델 매개변수 확장과 효율적인 학습이 핵심 영역이 되고 있습니다. PyTorch 생태계는 다양한 도구를 제공하여 멀티모달 모델의 학습과 확장을 가속화하는 것을 목표로 합니다.
앞으로 PyTorch는 멀티모달 생성 모델 등 다른 유형의 모델에 대한 지원을 추가하고 관련 기술의 자동화를 개선할 예정입니다. PyTorch 개발자 커뮤니티 공식 계정을 계속해서 팔로우해 주시기 바랍니다. QR 코드를 스캔하고 "PyTorch"를 적어 PyTorch 커뮤니티에 가입할 수도 있습니다.

PyTorch 공식 블로그, 튜토리얼
최신 개발 사항 및 모범 사례
QR 코드를 스캔하여 토론 그룹에 참여하세요