Command Palette
Search for a command to run...
PipeTransformer: 대규모 분산 모델 학습을 위한 자동화된 탄력적 파이프라인

논문 제목:
PipeTransformer: 대규모 모델의 분산 학습을 위한 자동화된 탄성 파이프라인
Pipeptransformer는 자동화된 탄성 파이프라인을 사용하여 Transformer 모델의 효율적인 분산 학습을 수행합니다. PipeTransformer에서는 학습 중에 특정 레이어를 점진적으로 식별하여 동결할 수 있는 적응형 동적 동결 알고리즘과 나머지 활성 레이어를 학습하기 위해 동적으로 리소스를 할당할 수 있는 유연한 파이프라인 시스템을 설계했습니다.
구체적으로, PipeTransformer는 파이프라인에서 동결된 레이어를 자동으로 제외하고, 활성 레이어를 더 적은 GPU에 넣고, 더 많은 복제본으로 분기하여 데이터 병렬 폭을 늘립니다.
ViT(ImageNet 데이터세트 사용)와 BERT(SQuAD 및 GLUE 데이터세트 사용)에 대한 평가 결과, PipeTransformer는 정확도 저하 없이 최신 기준선과 비교했을 때 최대 2.83배의 속도 향상을 달성하는 것으로 나타났습니다.
또한 이 논문에는 사용자가 알고리즘과 시스템 설계를 보다 포괄적으로 이해하는 데 도움이 되는 다양한 성능 분석이 포함되어 있습니다.
다음으로, 본 논문에서는 본 시스템의 연구 배경, 동기, 설계 아이디어, 설계 솔루션을 자세히 소개하고, PyTorch 분산 API를 이용하여 알고리즘과 시스템을 구현하는 방법을 설명하겠습니다.
소개

대규모 Transformer 모델은 자연어 처리와 컴퓨터 비전 모두에서 정확도 면에서 획기적인 발전을 이루었습니다. GPT-3는 대부분의 NLP 작업에서 새로운 높은 정확도 기록을 세웠습니다. ImageNet에서도 Vision Transformer(약칭 ViT)는 89%의 최고 1 정확도를 달성하여 가장 진보된 합성곱 신경망 ResNet-152와 EfficientNet보다 우수한 성능을 보였습니다.
모델 크기가 계속 커짐에 따라 발생하는 문제를 해결하기 위해 연구자들은 매개변수 서버, 파이프라인 병렬 처리, 계층 내 병렬 처리, 중복 없는 데이터 병렬 처리 등 다양한 분산 학습 기술을 제안했습니다.
그러나 기존의 분산형 학습 솔루션은 단지 연구 시나리오일 뿐이며, 모든 모델 가중치는 학습 과정에서 최적화되어야 합니다(즉, 계산 및 통신 오버헤드는 여러 반복 작업 동안 비교적 안정적으로 유지되어야 합니다). 최근 점진적 학습에 대한 연구에 따르면 신경망의 매개변수를 동적으로 학습할 수 있다는 사실이 밝혀졌습니다.
- 딥러닝 역학 및 해석을 위한 특이 벡터 정규 상관 분석. 신경IPS 2017
- 점진적 스태킹을 통한 BERT의 효율적인 학습. ICML 2019
- 점진적 레이어 삭제를 통한 트랜스포머 기반 언어 모델의 학습 가속화. 신경IPS 2020
- 점진적인 BERT 훈련을 위한 변압기 성장에 관하여. 2021년 NACCL

그림 2: 해석 가능한 동결 학습: DNN 하향식 수렴(CIFAR10에서 결과를 테스트하기 위해 ResNet 사용) 각 창은 SVCCA를 통해 각 계층의 유사성을 보여줍니다.
예를 들어, 동결 학습에서 신경망은 일반적으로 하향식으로 수렴합니다. (즉, 특정 결과를 얻기 위해 모든 계층을 학습할 필요는 없습니다.)
위의 그림은 비슷한 접근 방식을 사용하여 훈련 과정 전체에서 가중치가 어떻게 안정화되는지에 대한 예를 보여줍니다. 이를 바탕으로,우리는 동결된 학습을 활용하여 Transformer 모델의 분산 학습을 수행하고, 활성 계층의 축소된 집합에 집중하여 리소스를 동적으로 할당함으로써 학습 속도를 높입니다.
이 레이어 동결 전략은 파이프라인 병렬 처리에 특히 적합합니다. 파이프라인에서 연속적인 최하위 레이어를 제외하면 계산, 메모리 및 통신 오버헤드를 줄일 수 있기 때문입니다.
그림 3: PipeTransformer의 자동화되고 유연한 파이프라인 프로세스는 Transformer 모델의 분산 학습을 가속화합니다.
PipeTransformer는 파이프라인 모델의 범위와 파이프라인 복제본의 수를 동적으로 변환하여 동결된 레이어에 자동으로 반응하는 유연한 파이프라인 교육 가속 프레임워크입니다.
저희가 아는 한, 이 논문은 파이프라인과 데이터 병렬 학습의 맥락에서 레이어 동결을 연구한 최초의 논문입니다.
그림 3은 이러한 조합의 장점을 보여줍니다.
첫째, 파이프라인에서 동결된 레이어를 제외하면 동일한 모델을 더 적은 수의 GPU에 넣을 수 있어 GPU 간 통신이 줄어들고 파이프라인 버블도 작아집니다.
둘째, 모델을 더 적은 수의 GPU에 패킹하면 동일한 클러스터가 더 많은 파이프라인 복제본을 수용할 수 있으므로 데이터 병렬 처리의 폭이 늘어납니다.
더 중요한 점은, 두 가지 장점이 덧셈이 아닌 곱셈이어서 훈련 진행 속도를 더욱 높일 수 있다는 것입니다.
PipeTransformer의 디자인은 네 가지 주요 과제에 직면합니다.
첫째, 동결 알고리즘은 동적이고 적응적인 동결 결정을 내려야 합니다. 그러나 기존 연구는 사후 분석 도구만을 제공합니다.
두 번째로, 파이프라인 재분할의 효율성은 파티션 세분성, 파티션 간 활성화 크기, 미니 배치 청크 수를 포함한 여러 요인의 영향을 받으며, 이를 위해서는 더 큰 솔루션 공간에서 추론하고 검색해야 합니다.
다음으로, 동적으로 추가 파이프라인 복제본을 도입하기 위해 PipeTransformer는 집단적 커뮤니케이션의 정적인 특성을 극복하고 새로운 프로세스가 온라인 상태가 될 때 잠재적으로 복잡한 프로세스 간 메시징 프로토콜(파이프라인은 하나의 프로세스에서만 처리할 수 있음)을 피해야 합니다.
마지막으로, 캐시는 동결된 레이어의 반복적인 전방 전파에 소요되는 시간을 절약할 수 있지만, 시스템이 각 복제본에 대한 전용 캐시를 생성하고 예열할 수 없기 때문에 기존 파이프라인과 새로 추가된 파이프라인 간에 캐시를 공유해야 합니다.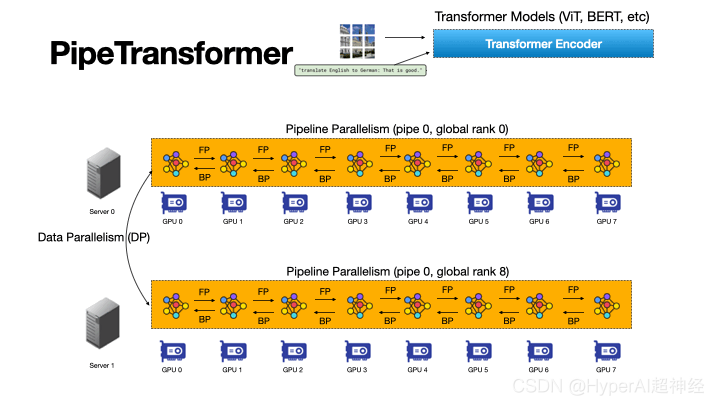
그림 4: PipeTransformer Dynamics의 개략도
그림 4에서 보는 바와 같이, 위의 과제를 해결하기 위해서는PipeTransformer의 디자인은 4가지 핵심 구성 요소로 구성됩니다.
첫 번째는 서로 다른 반복에서 동결된 레이어의 선택을 안내하는 신호를 생성하는 조정 가능한 적응 알고리즘입니다(동결 알고리즘). 이러한 신호에 의해 트리거되면, 탄력적 파이프라인 모듈(AutoPipe)은 이기종 파티션(동결된 레이어와 활성 레이어)의 활동 크기와 작업 부하의 변화를 평가하여 남아 있는 활성 레이어를 더 적은 GPU로 패킹합니다.
다음으로, 다양한 파이프라인 길이에 대한 이전 분석 결과를 바탕으로 미니 배치를 일련의 더 나은 마이크로 배치로 분해합니다.
다음 모듈인 AutoDP는 해제된 GPU를 차지하기 위해 추가 파이프라인 복사본을 생성하고 계층적 통신 프로세스 그룹을 유지하여 집단 통신을 위한 동적 멤버십을 달성합니다.
마지막 모듈인 AutoCache는 기존 및 새로 추가된 데이터 병렬 프로세스 간의 활성화를 효율적으로 공유하고 변환 중에 오래된 캐시를 자동으로 교체합니다.
일반적으로 PipeTransformer는 동결 알고리즘, AutoPipe, AutoDP, AutoCache 모듈을 결합하여 상당한 학습 가속을 제공합니다.
ViT(ImageNet 데이터세트 사용)와 BERT(SQuAD 및 GLUE 데이터세트 사용) 모델을 사용하여 PipeTransformer를 평가한 결과, PipeTransformer가 정확도 저하 없이 최신 기준선과 비교했을 때 최대 2.83배의 속도 향상을 달성한다는 것을 보여주었습니다.
또한 사용자가 알고리즘 및 시스템 설계를 보다 포괄적으로 이해할 수 있도록 다양한 성능 분석도 제공합니다. 마지막으로, 동결 알고리즘, 모델 정의, 학습 가속을 명확하게 분리하는 PipeTransformer용 오픈 소스 유연 API를 개발하여 유사한 동결 전략이 필요한 알고리즘으로 마이그레이션할 수 있게 했습니다.
전반적인 디자인
우리의 목표가 분산 학습 시스템에서 대규모 모델을 학습하는 것이라고 가정해보자. 이 시스템은 파이프라인 모델 병렬 처리와 데이터 병렬 처리를 결합하며 다음과 같은 시나리오를 처리하는 데 사용할 수 있습니다.
모델이 단일 GPU 장치의 메모리에 맞지 않거나 배치 크기가 너무 작아 메모리 부족을 피할 수 없습니다. 구체적으로 정의된 설정은 다음과 같습니다.
- 학습 과제 및 모델 정의. 대규모 이미지나 텍스트 데이터세트에 대해 Transformer 모델(Vision Transformer, BERT 등)을 훈련합니다. Transformer 모델 mathcalF는 총 L개의 층을 가지고 있으며, i번째 층은 순방향 계산 함수 fi와 해당 매개변수 집합으로 구성됩니다.
- 훈련 인프라. 학습 인프라가 N개의 GPU 서버(즉, 노드)가 있는 GPU 클러스터로 구성되어 있다고 가정합니다. 각 노드에는 1개의 GPU가 있습니다. 클러스터는 동질적입니다. 즉, 각 GPU와 서버의 하드웨어 구성이 동일합니다. 각 GPU의 메모리 용량은 MGPU입니다. 서버는 InfiniBand와 같은 고대역폭 네트워크 인터페이스를 통해 서로 연결됩니다.
- 파이프라인 병렬 처리. 각 머신에서 K개의 파티션이 있는 파이프라인에 모델 F를 로드합니다(K는 파이프라인 길이를 나타냅니다). k번째 파티션은 Pk개의 연속된 레이어로 구성됩니다. 각 파티션이 하나의 GPU 장치에 의해 처리된다고 가정합니다. 1≤K≤I는 단일 장치에서 여러 모델 복제본에 대해 여러 개의 파이프라인을 구축할 수 있음을 의미합니다.
파이프라인에 있는 모든 GPU 장치가 동일한 머신에 속하고, 파이프라인이 동기 파이프라인이며, 만료된 그래디언트가 포함되지 않고, 마이크로 배치의 수가 M이라고 가정합니다. Linux 운영 체제에서 각 파이프라인은 프로세스에 의해 처리됩니다. 자세한 내용은 GPipe를 참조하세요.
- 데이터 병렬성. DDP는 R 병렬 워커 내부의 크로스 머신 분산 데이터 병렬 처리 그룹입니다. 각 작업자는 파이프라인(단일 프로세스)의 복사본입니다. r번째 Worker의 인덱스(ID)는 순위 r입니다.
DDP의 두 파이프라인은 동일한 GPU 서버에 속할 수도 있고 다른 GPU 서버에 속할 수도 있으며, AllReduce 알고리즘을 사용하여 그래디언트를 교환할 수도 있습니다.
이런 경우, 우리의 목표는 동결된 훈련의 이점을 활용하여 훈련 속도를 높이는 것입니다. 동결된 훈련은 전체 훈련 과정 동안 모든 계층을 훈련할 필요성을 없애줍니다.
또한 이를 통해 계산, 통신, 메모리 손실을 줄일 수 있으며, 레이어의 지속적인 동결로 인해 발생하는 과도한 적합을 어느 정도 방지할 수 있습니다.
그러나 이러한 장점을 활용하려면 위에서 언급한 네 가지 과제를 극복해야 합니다. 즉, 적응형 동결 알고리즘 설계, 동적 파이프라인 재분할, 효율적인 리소스 재할당, 프로세스 간 캐싱이 필요합니다.
그림 5: PipeTransformer 교육 시스템 개요
PipeTransformer는 파이프라인 모델의 범위와 파이프라인 복제본의 수를 동적으로 변환할 수 있는 즉각적 동결 알고리즘과 자동 탄성 파이프라인 학습 시스템을 공동 설계합니다. 전체 시스템 아키텍처는 그림 5에 나와 있습니다.
PipeTransformer의 유연한 파이프라인을 지원하기 위해 PyTorch Pipeline의 맞춤형 버전을 유지 관리합니다. 데이터 병렬 처리를 위해 PyTorch DDP를 기준으로 사용합니다. 다른 라이브러리는 운영 체제의 표준 메커니즘(멀티 프로세싱 등)으로, 사용자 정의 소프트웨어나 하드웨어의 필요성을 없애줍니다.
프레임워크의 다용성을 보장하기 위해 학습 시스템을 동결 알고리즘, AutoPipe, AutoDP, AutoCache의 네 가지 핵심 구성 요소로 분리했습니다.
동결 알고리즘(회색)은 교육 루프에서 메트릭을 샘플링하고 레이어별로 동결 결정을 내리며, 이 결정은 AutoPipe(녹색)와 공유됩니다.
AutoPipe는 파이프라인에서 동결된 레이어를 제외하고 활성 레이어를 더 적은 수의 GPU(분홍색)에 패킹하여 학습 속도를 높이는 유연한 파이프라인 모듈로, 이를 통해 GPU 간 통신을 줄이고 파이프라인 정체를 작게 유지합니다.
그런 다음 AutoPipe는 파이프라인 길이 정보를 AutoDP(보라색)에 전달하고, AutoDP는 가능한 경우 데이터 병렬 처리 폭을 늘리기 위해 더 많은 파이프라인 복사본을 생성합니다.
이 그림에는 AutoDP가 새로운 복제본을 도입하는 예(보라색)도 포함되어 있습니다. AutoCache(주황색 윤곽선)는 크로스 파이프라인 캐시 모듈입니다. 가독성과 일반성을 위해 소스 코드 아키텍처는 그림 5와 일관성을 유지했습니다.
PyTorch API를 사용한 구현
그림 5에서 볼 수 있듯이 PipeTransformer는 Freeze Algorithm, AutoPipe, AutoDP, AutoCache의 네 가지 구성 요소로 이루어져 있습니다.
그 중 AutoPipe와 AutoDP는 각각 PyTorch DDP(torch.nn.parallel.DistributedDataParallel)와 파이프라인(torch.distributed.pipeline)에 의존합니다.
이 블로그에서는 AutoPipe와 AutoDP의 주요 구현 세부 사항만 강조해서 설명합니다. 동결 알고리즘과 AutoCache에 대한 자세한 내용은 해당 논문을 참조하세요.
AutoPipe: 유연한 파이프라인
AutoPipe는 파이프라인에서 동결된 레이어를 제외하고 활성 레이어를 더 적은 GPU에 압축하여 학습 속도를 높일 수 있습니다.이 섹션에서는 AutoPipe의 주요 구성 요소에 대해 자세히 설명합니다.
1) 동적 파티션 파이프라인
2) 파이프라인 장비 수를 줄입니다.
3) 미니 배치 청크 크기를 적절히 최적화합니다.
PyTorch 파이프라인의 기본 사용법
AutoPipe의 세부 사항을 살펴보기 전에 먼저 PyTorch Pipeline(torch.distributed.pipeline.sync.Pipe)의 기본적인 사용법에 대해 알아보겠습니다.
파이프라인 설계가 실제로 어떻게 이루어지는지 이해하려면 다음의 간단한 예를 살펴보세요.
# Step 1: build a model including two linear layers
fc1 = nn.Linear(16, 8).cuda(0)
fc2 = nn.Linear(8, 4).cuda(1)
# Step 2: wrap the two layers with nn.Sequential
model = nn.Sequential(fc1, fc2)
# Step 3: build Pipe (torch.distributed.pipeline.sync.Pipe)
model = Pipe(model, chunks=8)
# do training/inference
input = torch.rand(16, 16).cuda(0)
output_rref = model(input)이 간단한 예에서는 Pipe를 초기화하기 전에 nn.Sequential 모델을 여러 GPU 장치로 분할하고 최적의 청크 수를 설정해야 한다는 것을 알 수 있습니다.
파이프라인 학습 속도를 높이려면 여러 파티션에 걸쳐 계산을 균형 있게 조정하는 것이 중요합니다. 단계별로 작업 부하가 고르지 않게 분배되면 지연이 발생하고, 작업이 적은 장치가 대기해야 하기 때문입니다. 청크의 수는 파이프라인 처리량에 상당한 영향을 미칠 수도 있습니다.
파이프라인 파티션 균형 조정
PipeTransformer와 같은 동적 학습 시스템에서는 각 파티션에 동일한 수의 매개변수가 있다고 해서 가장 빠른 학습 속도가 보장되지 않습니다. 다른 요소도 중요한 역할을 합니다.
그림 6: 파티션 경계는 스킵 연결의 중앙에 위치합니다.
1. 파티션 간 통신 오버헤드. 스킵 연결의 중간에 파티션 경계를 배치하면 스킵 연결의 텐서를 다른 GPU에 복사해야 하므로 추가 통신이 발생합니다.
예를 들어, 그림 6의 BERT 파티션의 경우, 파티션 k는 파티션 k-2와 파티션 k-1에서 중간 출력을 얻어야 합니다. 이와 대조적으로 경계가 추가 계층 뒤에 배치되면 파티션 k-1과 파티션 k 사이의 통신 오버헤드가 상당히 작아집니다.
측정 결과, 교차 장치 통신은 약간 불균형한 파티션보다 비용이 더 많이 들기 때문에 스킵 연결을 끊는 것은 고려하지 않았습니다.
2. 레이어 메모리 사용량을 고정합니다. 학습하는 동안 AutoPipe는 두 가지 유형의 레이어(고정 레이어와 활성 레이어)의 균형을 맞추기 위해 파티션 경계를 여러 번 다시 계산해야 합니다.
동결된 레이어에는 역방향 활성화 맵, 최적화 상태 및 그래디언트가 필요하지 않으므로 동결된 레이어의 메모리 비용은 비활성 레이어의 메모리 비용의 일부에 불과합니다.
메모리와 컴퓨팅 비용의 기본 지표를 얻기 위해 침입적 프로파일러를 실행하는 대신, 동일한 활성 레이어와 관련하여 동결된 레이어의 메모리 사용량을 평가하기 위해 조정 가능한 비용 요인 lambdafrozen을 정의합니다. 실험 하드웨어에 대한 실증적 측정을 바탕으로 1/6으로 설정했습니다.
위의 두 가지 사항을 기반으로 AutoPipe는 매개변수 크기에 따라 파이프라인 파티션의 균형을 맞출 수 있습니다.구체적으로, AutoPipe는 탐욕적 알고리즘을 사용하여 동결된 레이어와 활성 레이어를 할당하여 스코어링 영역의 하위 레이어가 K GPU 장치에 균등하게 분산될 수 있도록 합니다.
의사코드는 알고리즘 1의 load_balance() 함수입니다. 동결된 레이어는 원래 모델에서 추출되어 파이프라인의 첫 번째 장치에 있는 별도의 모델 인스턴스 Ffrozen에 저장됩니다.
이 기사에서 사용한 분할 알고리즘이 유일한 옵션은 아니라는 점에 유의하세요.PipeTransformer는 모듈식이므로 다른 대안과 함께 실행할 수 있습니다.
파이프라인 압축
파이프라인 압축은 GPU의 여유 공간을 늘려 더 많은 파이프라인 복사본을 수용할 수 있도록 돕고 파티션 간의 장치 간 통신 양을 줄여줍니다. 압축하는 데 걸리는 시간을 결정하려면 압축 후 가장 큰 파티션의 메모리 소비량을 추정한 다음, 이를 타임스텝 T=0에서 파이프라인의 가장 큰 파티션의 메모리 소비량과 비교할 수 있습니다.
광범위한 메모리 프로파일링을 피하기 위해 압축 알고리즘은 매개변수 크기를 훈련 메모리 사용의 프록시로 사용합니다. 이러한 단순화를 기반으로 파이프라인 압축에 대한 지침은 다음과 같습니다.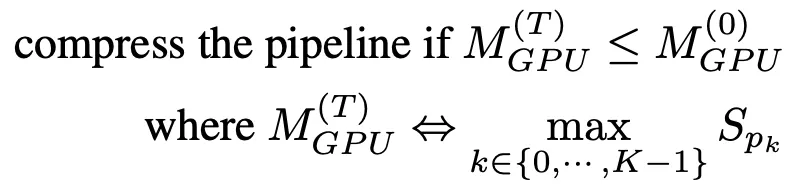
동결 알림을 받으면 AutoPipe는 파이프 길이 K를 2로 나누려고 시도합니다(예: 8에서 4로 나누면 2). K/2를 입력함으로써 압축 알고리즘은 압축 결과가 식(1)의 조건을 만족하는지 검증할 수 있다.
알고리즘 1의 25~33번째 줄에 의사 코드가 나와 있습니다. 이 압축으로 인해 학습 중에 속도가 기하급수적으로 향상됩니다. 즉, GPU 서버에 더 많은 GPU(예: 8개 이상)가 포함되어 있으면 속도 향상이 더욱 커집니다. 그림 7: 파이프라인 버블
그림 7: 파이프라인 버블
Fd, b 및 Ud는 각각 장치 d의 micro=batch b의 전방, 후방 및 최적화 업데이트를 나타냅니다.
각 반복에서의 총 버블 크기는 마이크로 배치당 전방 및 후방 비용에 K-1을 곱한 값입니다.
또한, 이 기술은 파이프라인 버블의 크기를 줄임으로써 훈련 속도를 높일 수도 있습니다. 파이프라인의 버블 크기를 설명하기 위해 그림 7은 4개의 마이크로 배치가 K=4인 4개의 디바이스 파이프라인을 어떻게 실행하는지 보여줍니다.
일반적으로 총 버블 크기는 각 마이크로 배치의 전방 비용과 후방 비용의 K-1배입니다. 따라서 파이프라인이 짧을수록 기포의 크기도 작아지는 것은 당연합니다.
마이크로 배치의 동적 개수
이전의 파이프라인 병렬 시스템은 미니 배치당 고정된 수의 마이크로 배치(M)를 사용했습니다. GPipe에서는 M ≥ 4 x K를 권장합니다. 여기서 K는 파티션 수(파이프라인 길이)입니다. 하지만 PipeTransformer가 K를 동적으로 설정한다는 점을 감안하면, 학습 중에 M을 정적으로 유지하는 것은 효과적이지 않다는 것을 발견했습니다.
또한, DDP와 통합할 경우 M의 값은 DDP 그래디언트 동기화의 효율성에도 영향을 미칩니다. DDP는 그래디언트 동기화 전에 매개변수의 역방향 계산을 완료하기 위해 마지막 마이크로 배치를 기다려야 하므로, 마이크로 배치가 미세할수록 계산과 통신이 겹치는 부분이 줄어듭니다.
따라서 PipeTransformer는 정적 값을 사용하는 대신, K-6K 범위에서 M의 값을 열거하여 DDP 환경의 하이브리드에서 M의 최적 값을 동적으로 검색합니다. 특정한 훈련 환경의 경우 프로파일링은 한 번만 완료하면 됩니다(알고리즘 1의 35번째 줄 참조).
AUTODP: 더 많은 파이프라인 복사본 생성
AutoPipe가 동일한 파이프라인을 더 적은 GPU로 압축할 수 있다는 점을 고려하면 AutoDP는 자동으로 새로운 파이프라인 복사본을 생성하여 데이터 병렬 처리 폭을 늘릴 수 있습니다.
개념적으로는 간단하지만, 의사소통과 상태에 대한 의존성은 미묘하며 신중한 설계가 필요합니다.세 가지 주요 잠재적 과제는 다음과 같습니다.
1. DDP 커뮤니케이션: PyTorch DDP의 집합적 통신에는 정적 멤버십이 필요하므로 새로운 파이프라인이 기존 파이프라인에 연결될 수 없습니다.
2. 상태 동기화: 새로 활성화된 프로세스는 학습 절차(예: 에포크 수 및 학습률), 가중치 및 최적화기 상태, 동결 계층 경계, 파이프라인 GPU 범위 측면에서 기존 파이프라인과 일관성이 있어야 합니다.
3. 데이터 세트 재분배: 파이프라인의 동적인 수에 맞춰 데이터 세트를 재조정해야 합니다. 이렇게 하면 낙오자가 생기는 것을 방지할 수 있을 뿐만 아니라 모든 DDP 프로세스의 기울기가 동일하게 가중치를 갖도록 할 수 있습니다.
그림 8: AutoDP: 두 프로세스 그룹 간 정보를 통한 동적 데이터 병렬 처리
참고: 프로세스 0-7은 머신 0에 속하고 프로세스 8-15는 머신 1에 속합니다.
이러한 과제를 해결하기 위해 우리는 DDP를 위한 이중 커뮤니케이션 프로세스 그룹을 만들었습니다. 그림 8에서 보듯이, 정보 프로세스 그룹(보라색)은 가벼운 제어 정보를 담당하고 모든 프로세스를 포괄하는 반면, 활성 학습 프로세스 그룹(노란색)은 활성 프로세스만 포함하고 학습 중에 무거운 텐서 통신을 위한 도구 역할을 합니다.
정보 세트는 정적인 반면, 훈련 세트는 활동 프로세스에 맞게 분할되고 재구성됩니다. T0에서는 프로세스 0과 8만 활성화됩니다. T1로 전환하는 동안 프로세스 0은 프로세스 1과 9(새로 추가된 파이프라인 복사본)를 활성화하고 메시지 그룹을 사용하여 위에 언급된 필요한 정보를 동기화합니다.
그러면 4개의 활동적인 프로세스가 새로운 훈련 그룹을 형성하여 정적인 집단적 의사소통을 역동적인 멤버십에 맞게 조정합니다. 데이터 세트를 재분배하기 위해 활성 파이프라인 복제본 수에 맞춰 데이터 샘플링을 원활하게 조정하는 DistributedSampler 변형을 구현했습니다.
위의 설계는 DDP의 통신 손실을 줄이는 데 도움이 됩니다. 구체적으로, T0에서 T1로 전환할 때 프로세스 0과 1은 기존 DDP 인스턴스를 파괴할 수 있으며, 활성 프로세스는 캐시된 파이프라인 모델을 사용하여 새로운 DDP 교육 그룹을 구성합니다(AutoPipe는 동결된 모델과 캐시된 모델을 별도로 저장합니다).
위의 작업을 달성하기 위해 다음 API를 사용했습니다.
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# initialize the process group (this must be called in the initialization of PyTorch DDP)
dist.init_process_group(init_method='tcp://' + str(self.config.master_addr) + ':' +
str(self.config.master_port), backend=Backend.GLOO, rank=self.global_rank, world_size=self.world_size)
...
# create active process group (yellow color)
self.active_process_group = dist.new_group(ranks=self.active_ranks, backend=Backend.NCCL, timeout=timedelta(days=365))
...
# create message process group (yellow color)
self.comm_broadcast_group = dist.new_group(ranks=[i for i in range(self.world_size)], backend=Backend.GLOO, timeout=timedelta(days=365))
...
# create DDP-enabled model when the number of data-parallel workers is changed. Note:
# 1. The process group to be used for distributed data all-reduction.
If None, the default process group, which is created by torch.distributed.init_process_group, will be used.
In our case, we set it as self.active_process_group
# 2. device_ids should be set when the pipeline length = 1 (the model resides on a single CUDA device).
self.pipe_len = gpu_num_per_process
if gpu_num_per_process > 1:
model = DDP(model, process_group=self.active_process_group, find_unused_parameters=True)
else:
model = DDP(model, device_ids=[self.local_rank], process_group=self.active_process_group, find_unused_parameters=True)
# to broadcast message among processes, we use dist.broadcast_object_list
def dist_broadcast(object_list, src, group):
"""Broadcasts a given object to all parties."""
dist.broadcast_object_list(object_list, src, group=group)
return object_list실험 섹션
이 섹션에서는 먼저 실험 설정을 요약한 다음 컴퓨터 비전 및 자연어 처리 작업에서 PipeTransformer의 성능을 평가합니다.
하드웨어. 실험은 InfiniBand CX353A(GB/s)로 연결된 두 대의 동일한 컴퓨터에서 수행되었으며, 각 컴퓨터에는 NVIDIA Quadro RTX 5000(16GB GPU 메모리) 8개가 장착되어 있었습니다. 머신 내 GPU 간 대역폭(PCI 3.0, 16레인)은 15.754GB/s입니다.
성취하다. 우리는 PyTorch Pipe를 빌딩 블록으로 사용합니다. BERT 모델의 정의, 구성 및 관련 토크나이저는 모두 HuggingFace 3.5.0에서 가져왔습니다. 우리는 PyTorch에서 TensorFlow를 사용하여 Vision Transformer를 구현했습니다.
모델과 데이터 세트. 이 실험에서는 CV와 NLP 분야의 두 가지 대표적인 Transformer 모델인 Vision Transformer(ViT)와 BERT를 사용했습니다. ViT는 이미지 분류 작업에 적용되며, ImageNet21K에서 사전 학습된 가중치로 초기화되고 ImageNet 및 CIFAR-100에서 미세 조정됩니다. BERT는 두 가지 작업을 실행합니다. GLUE(General Language Understanding Evaluation) 벤치마크의 SST-2 데이터세트에 대한 텍스트 분류와 SQuAD v1.1 데이터세트(Stanford Question Answering)에 대한 지능형 질의 응답입니다. SQuAD v1.1 데이터 세트는 100,000개의 크라우드소싱 질문-답변 쌍으로 구성되어 있습니다.
훈련 계획. 대규모 모델을 처음부터 학습하는 경우 일반적으로 수천 GPU 일(예: GPT-3)이 필요하므로 사전 학습된 모델을 사용하여 다운스트림 작업을 미세 조정하는 것이 CV 및 NLP 분야의 추세가 되었습니다. 또한 PipeTransformer는 여러 핵심 구성 요소가 포함된 복잡한 교육 시스템입니다. 따라서 PipeTransformer의 첫 번째 버전에 대한 시스템 개발 및 알고리즘 연구를 위해 대규모 사전 학습을 사용하여 처음부터 개발하고 평가하는 것은 비용 효율적이지 않습니다. 따라서 이 섹션에서 제시하는 실험은 사전 학습된 모델에 초점을 맞춥니다. 사전 학습과 미세 조정의 모델 아키텍처가 동일하므로 PipeTransformer는 두 가지 요구 사항을 모두 충족할 수 있습니다. 사전 훈련 결과는 부록에서 논의합니다.
기준선. 이 섹션의 실험에서는 PipeTransformer를 최신 프레임워크인 PyTorch Pipeline(PyTorch의 구현인 GPipe) 및 PyTorch DDP와 비교합니다. 이 논문은 레이어를 동결하여 분산 학습을 가속화하는 방법을 연구한 최초의 논문이므로 아직 완벽하게 일관된 해당 솔루션은 없습니다.
하이퍼파라미터. ImageNet 및 CIFAR-100 데이터 세트의 경우, 실험에는 ViT-B/16(12개 변압기 레이어 및 16x16 입력 패치 크기)이 사용되었습니다. SQuAD 1.1의 경우, 실험에는 BERT-large-uncased(24개 레이어)가 사용되었습니다. SST-2는 BERT 기반 언케이스드(12개 레이어)를 사용합니다. PipeTransformer, ViT 및 BERT 학습을 사용하면 파이프라인당 배치 크기를 각각 약 400과 64로 설정할 수 있습니다. 다른 하이퍼파라미터(예: 에포크, 학습률 등)에 대해서는 부록을 참조하세요.
전반적인 가속 훈련
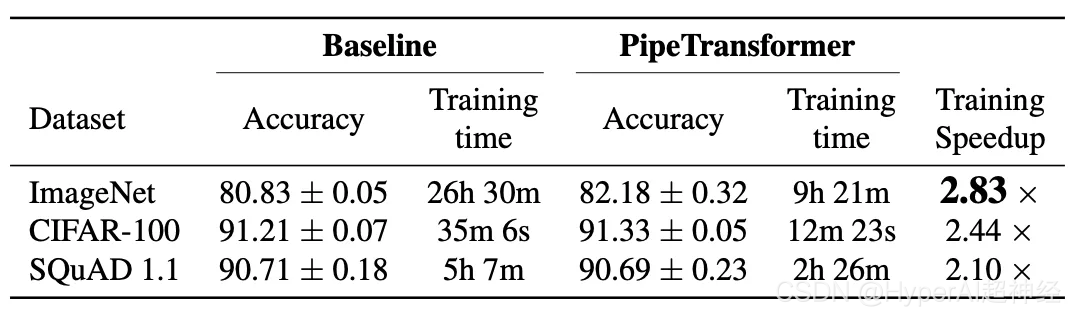
위의 표는 전반적인 실험 결과를 요약한 것입니다. 여기서 속도 향상은 보수적인 값을 기반으로 한다는 점에 유의하십시오.(1/3) 이 값은 비슷하거나 더 높은 정확도를 달성할 수 있습니다. 값이 a이면(2/5,1/2)는 더 빠른 속도를 얻을 수 있지만 정확도가 약간 떨어집니다. 또한 BERT(24층)는 ViT-B/16(12층)보다 크기가 크기 때문에 통신 시간이 더 많이 필요합니다.
성과 분석
속도 향상 고장
이 섹션에서는 /AutoPipe의 다양한 구성 요소에 대한 평가 결과를 제시하고 성능을 분석합니다.
이 네 가지 구성 요소의 효과와 학습 속도에 미치는 영향을 파악하기 위해 다양한 조합으로 실험을 수행했으며 학습 샘플 처리량(샘플/초)과 속도 향상을 측정 기준으로 사용했습니다. 결과는 그림 9에 나타나 있다.실험 결과의 주요 내용은 다음과 같습니다.
1. 주요 속도 향상은 AutoPipe와 AutoDP가 구현한 탄력적 파이프라인의 결과입니다.
2. AutoDP는 AutoCache의 효과를 증폭시킵니다.
3. 동결 훈련은 어떠한 시스템 조정이나 훈련 속도 저하 없이 독립적으로 진행됩니다.
동결 알고리즘에서 a를 조정하세요

그림 10: 동결 알고리즘에서 a 조정
우리는 알고리즘을 동결하는 것이 훈련 속도에 어떤 영향을 미치는지 보여주기 위해 몇 가지 실험을 수행했습니다. 결과는 a(과도한 동결)가 클수록 속도 향상은 크지만, 성능은 약간 저하됨을 보여줍니다. 그림 10에 표시된 예에서 a=1/5일 때 동결 학습은 일반 학습보다 더 나은 성능을 보이며 속도 향상 비율은 2.04입니다.
탄력적 파이프라인의 최적 청크 수

그림 11: 탄력적 파이프라인의 최적 청크 수
우리는 다양한 파이프라인 길이 K에 대한 최적의 마이크로 배치 수 M을 분석합니다. 결과는 그림 11에 나와 있습니다. 보시다시피, 최적의 수 M은 K의 값에 따라 그에 따라 달라집니다. M이 다르면 처리량 격차가 커집니다(그림에서 K=8일 때 표시됨). 이는 탄성 파이프라인에서 전방 프로파일러를 사용해야 할 필요성을 확인시켜 줍니다.
캐시 타이밍 이해

그림 12: 캐시 타이밍
AutoCache를 평가하기 위해 AutoCache를 사용한 경우(파란색 선)와 AutoCache를 사용하지 않은 경우(빨간색 선)에 epoch 0부터 시작하는 학습 작업의 샘플 처리량을 비교했습니다.
그림 12는 캐싱을 너무 일찍 활성화하면 더 적은 수의 동결된 레이어에 대해 전방 전파하는 것보다 비용이 더 많이 들기 때문에 학습 속도가 느려질 수 있음을 보여줍니다. 더 많은 레이어를 동결한 후에는 캐시된 활성화의 성능이 해당 순방향 패스보다 훨씬 더 좋아집니다. 따라서 AutoCache는 프로파일러를 사용하여 캐싱을 활성화할 적절한 시기를 결정합니다.
우리 시스템에서는 ViT(12개 레이어)의 경우 캐싱이 3번째 동결 레이어에서 시작됩니다. BERT(24개 레이어)의 경우 캐싱은 5번째 동결 레이어부터 시작됩니다.
요약하다
이 논문에서는 PyTorch 분산 API를 사용하여 분산 학습을 위한 탄력적 파이프라인 병렬 처리와 데이터 병렬 처리를 결합한 전체적인 솔루션인 PipeTransformer를 소개합니다.
구체적으로, PipeTransformer는 파이프라인에서 레이어를 점진적으로 동결하고, 남아 있는 활성 레이어를 더 적은 수의 GPU에 넣고, 더 많은 파이프라인 복사본을 포크하여 데이터 병렬 폭을 늘릴 수 있습니다. ViT 및 BERT 모델에 대한 평가 결과, PipeTransformer는 정확도 손실 없이 최신 기준선과 비교하여 2.83배 빠른 속도를 달성하는 것으로 나타났습니다.