Command Palette
Search for a command to run...
DALL-E 논문을 읽은 후 우리는 대규모 데이터 세트에도 대체 버전이 있다는 것을 발견했습니다.

OpenAI 팀의 새로운 모델인 DALL-E가 화면에 등장했습니다. 이 새로운 유형의 신경망은 120억 개의 매개변수를 사용하고 "특별히 훈련"되었습니다. 설명적 텍스트를 입력하면 해당 이미지를 생성할 수 있습니다. 이제 팀은 프로젝트 논문과 일부 모듈 코드를 오픈 소스로 공개하여 이 아티팩트의 원리를 이해할 수 있게 되었습니다.
올해 초, OpenAI는 자연어와 이미지 간의 차원적 장벽을 완전히 허무는 이미지 생성 모델 DALL-E를 출시했습니다.
아무리 과장되거나 비현실적인 텍스트 설명이라도 DALL-E에 입력하면 그에 상응하는 이미지가 생성되는데, 그 효과는 기술계 전체를 놀라게 했습니다.

엄청난 노력은 기적을 가져온다: 연금술 산업의 비용 상한선
컴퓨팅 파워: 1024 블록 V 100
모델이 출시되자 개발자들은 모델 구현 과정에 대해 추측했고 공식 논문을 기대했습니다. 최근 DALL-E의 논문과 일부 구현 코드가 마침내 공개되었습니다.

논문 주소: https://arxiv.org/abs/2102.12092
예상대로 OpenAI는 일부 개발자들이 이전에 추측했던 것처럼 다시 한번 강력한 "자본력"을 입증했습니다.이 논문에서는 학습 과정 전체에 걸쳐 총 1024개의 16GB NVIDIA V100 GPU를 사용했다고 밝혔습니다.
코드에 관해서, 공식 버전은 현재 이미지 재구성을 위해 dVAE 모듈만 엽니다.이 모듈의 목적은 텍스트-이미지 생성 작업에서 학습된 Transformer의 메모리 사용량을 줄이는 것입니다. 아직 트랜스포머 코드 부분은 공개되지 않았으므로 후속 업데이트를 기대할 수밖에 없습니다. 하지만 코드가 있어도 모든 사람이 이 GPU 사용을 재현할 수 있는 것은 아닙니다.
데이터 세트: 2억 5천만 개의 이미지-텍스트 쌍 + 120억 개의 매개변수
논문에서 OpenAI 팀은 머신 러닝 합성 방법을 사용하여 텍스트를 이미지로 변환하는 연구가 2015년에 시작되었다고 소개했습니다.
하지만 이전 연구에서 제안한 모델들은 텍스트-이미지 생성을 수행할 수 있었지만, 객체 변형, 불합리한 객체 배치, 전경과 배경 요소의 부자연스러운 혼합 등 생성 결과에 여전히 많은 문제점이 있었습니다.

연구 결과, 연구팀은 이전 연구는 일반적으로 더 작은 데이터 세트(예: MS-COCO 및 CUB-200)를 대상으로 평가되었다는 사실을 발견했습니다. 이를 바탕으로 연구팀은 다음과 같은 아이디어를 제안했다.데이터 세트 크기와 모델 크기가 현재 방법에 대한 제한 요인일 가능성이 있습니까?
그래서 팀은 이를 획기적인 발견으로 활용했다., 2억 5천만 개의 이미지-텍스트 쌍으로 구성된 데이터 세트가 인터넷에서 수집되었습니다.120억 개의 매개변수를 갖는 자기회귀 변환기가 이 데이터 세트를 기반으로 학습되었습니다.
또한 본 논문에서는 dVAE 모델의 학습에 다음을 사용한다고 소개합니다. 64개의 16GB NVIDIA V100 GPU,CLIP이 사용하는 판별 모델 14개 GPU를 학습한 256개 하늘.
집중적인 훈련 끝에 연구팀은 마침내 자연어로 제어할 수 있는 유연하고 사실적인 이미지 생성 모델인 DALL-E를 얻었습니다.
연구팀은 DALL-E 모델에서 생성된 결과를 다른 모델에서 생성된 결과와 비교하고 평가했습니다. 결과는 다음과 같습니다.90%의 경우, DALL-E에서 생성된 결과는 이전 연구의 결과보다 더 유리했습니다.

그림과 텍스트 데이터 세트는 평면 대체물이며 정말 좋습니다.
DALL-E 모델의 성공은 모델을 위한 대규모 학습 데이터의 중요성을 입증합니다.
일반 연금술사에게는 DALL-E와 동일한 데이터 세트를 얻는 것이 어려울 수 있지만, 대형 브랜드는 모두 대체 버전(저렴한 대체 버전)을 제공합니다.
OpenAI는 아직 학습 데이터 세트를 공개하지 않을 것이라고 밝혔지만,하지만 그들은 해당 데이터 세트에 구글이 공개한 개념 캡션 데이터 세트가 포함되어 있다고 밝혔습니다.
대규모 이미지-텍스트 데이터 세트 미니 대안
개념적 캡션 데이터 세트는 Google에서 ACL 2018에 발표한 논문 "개념적 캡션: 자동 이미지 캡션을 위한 정리되고 상위어가 결합된 이미지 대체 텍스트 데이터 세트"에서 제안되었습니다.

본 논문은 데이터 분류와 모델링 분류에 모두 기여합니다. 첫 번째,이 팀은 MS-COCO 데이터 세트보다 훨씬 더 많은 이미지를 포함하고 있는 새로운 이미지 캡션 주석 데이터 세트인 Conceptual Captions를 제안했는데, 여기에는 총 약 330만 개의 이미지와 설명 쌍이 포함됩니다.
개념 캡션(개념적 제목) 데이터 세트 세부 정보
데이터 출처:구글 AI
출시 시간:2018
포함된 수량:330만 개의 이미지-텍스트 쌍
데이터 형식:.tsv 데이터 크기:1.7GB
다운로드 주소:https://orion.hyper.ai/datasets/14682
ResNet+RNN+Transformer를 사용하여 역방향 DALL-E 구축
모델링 측면에서는 기존 연구 결과를 바탕으로이 팀은 Inception-ResNet-v2를 사용하여 이미지 특징을 추출한 다음 RNN과 Transformer 기반 모델을 사용하여 이미지 캡션을 생성했습니다(DALL-E는 텍스트 설명에서 이미지를 생성하고 Conceptual Captions는 이미지에서 텍스트 주석을 생성합니다).
데이터 세트를 생성하기 위해 팀은 약 10억 개의 인터넷 웹 페이지를 병렬로 처리하는 Flume 파이프라인부터 시작했습니다. 이 파이프라인은 해당 페이지에서 후보 이미지와 캡션 쌍을 추출, 필터링, 처리하여 여러 필터를 통과한 쌍을 보존합니다.
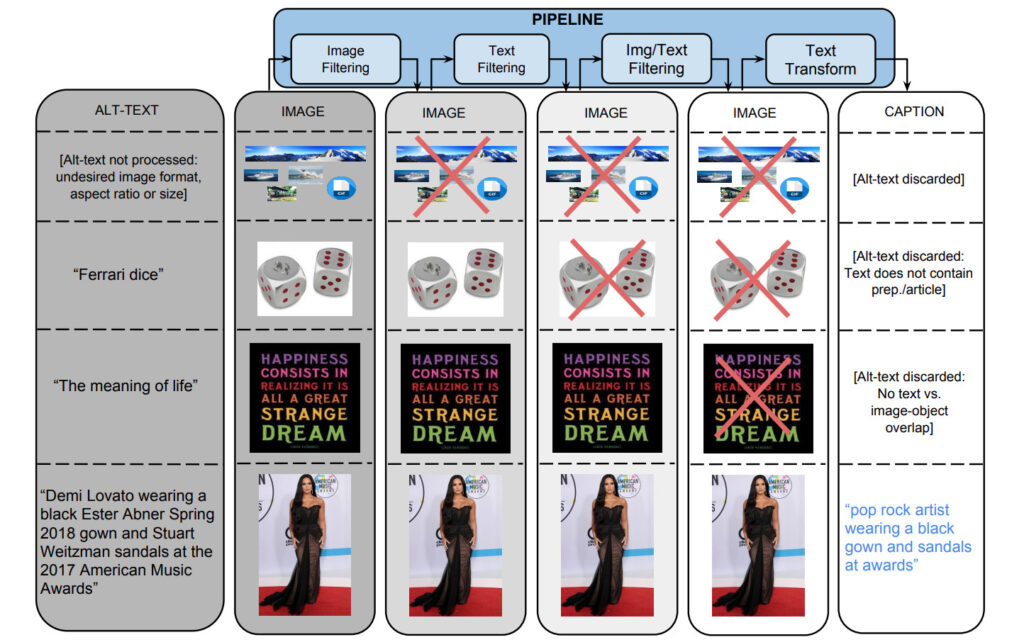
1. 이미지 기반 필터링
알고리즘은 인코딩 형식, 크기, 종횡비, 불쾌한 내용을 기준으로 이미지를 필터링합니다. 두 치수 모두 400픽셀보다 크고, 치수의 비율이 2를 넘지 않는 JPEG 이미지만 저장합니다. 음란물이나 욕설 감지를 유발하는 이미지는 제외됩니다. 결국 이러한 필터를 통해 651개 이상의 TP3T 후보 데이터가 제거되었습니다.
2. 텍스트 기반 필터링
이 알고리즘은 HTML 웹 페이지에서 설명적 텍스트(Alt-text)를 얻고, 설명적이지 않은 텍스트(SEO 태그나 해시태그 등)가 포함된 제목을 제거하고, 음란물, 욕설, 모독적인 언어, 프로필 사진 등이 포함된 주석과 같은 사전 설정된 지표를 기반으로 주석을 걸러냅니다. 마지막으로 3% 후보 텍스트만이 검토를 통과했습니다.
이미지와 텍스트 콘텐츠를 기반으로 하는 별도 필터링 외에도, 텍스트 태그 중 이미지 콘텐츠에 매핑될 수 없는 데이터도 필터링됩니다.
Google Cloud Vision API를 통해 제공되는 분류기를 사용하여 이미지에 클래스 레이블을 지정합니다.
3. 텍스트 변환 및 하이퍼렉시컬화
데이터 세트를 수집하는 과정에서 약 10억 개의 영어 웹 페이지에서 50억 개 이상의 이미지가 처리되었습니다. 고정밀 필터링 기준에 따르면 이미지와 제목 쌍 중 0.2%만이 선별을 통과했으며, 나머지 제목은 고유 명사(사람, 장소, 지역 등)가 포함되어 있어 제외되는 경우가 많았습니다.
저자는 하이퍼 동기화되지 않은 대체 텍스트 데이터에 대해 RNN 기반 자막 모델을 훈련하고 아래 그림에 출력 예를 제시했습니다.

모델 출력 설명: 가수 저스틴 비버가 MGM에서 열린 Billboard Music Awards에서 공연을 펼치고 있습니다.
Google Cloud Natural Language API를 사용하여 팀은 명명된 엔터티와 문법적 종속성 주석을 얻었습니다. 그런 다음 Google 지식 그래프(KG) 검색 API를 사용하여 명명된 엔터티와 KG 항목을 일치시키고 관련된 상위어를 활용합니다.
예를 들어, "Harrison Ford"와 "Calista Flockhart"는 모두 명명된 엔터티로 식별되므로 해당 KG 항목과 일치합니다. 이러한 KG 항목은 접속사로 "actor"를 갖고 있으며, 원래 표면 토큰을 이 접속사로 대체합니다.
결과 평가
팀은 데이터 세트의 테스트 세트를 가져왔습니다.4,000개의 샘플을 무작위로 추출하여 수동으로 평가했습니다. 3개의 주석 중 90% 위의 주석이 대부분 좋은 평가를 받았습니다.
연구팀은 COCO에서 훈련된 모델과 Conceptual에서 훈련된 모델 간의 차이점을 비교했습니다.
안에,첫 번째 차이점은 Conceptual 기반 학습 결과가 자연스러운 사진을 기반으로 한 COCO 기반 학습 결과보다 더 사회적이라는 점입니다.
예를 들어, 아래 가장 왼쪽 이미지에서 COCO로 훈련된 모델은 이미지 속 사람들을 지칭하기 위해 "남자 그룹"을 사용하는 반면, 개념적으로 훈련된 모델은 더 적절하고 더 많은 정보를 제공하는 용어인 "졸업생"을 사용합니다.

두 번째 차이점은 COCO로 훈련된 모델은 종종 "스스로 연관성을 찾아내고", 아무 생각 없이 일부 설명을 "만들어내는" 것처럼 보인다는 것입니다.예를 들어, 첫 번째 사진에서는 "건물 앞에 있는" 환각 증상이 나타났습니다. 두 번째 그림에서는 "시계와 두 개의 문"이 되는 환각이 나타납니다. 그리고 세 번째 사진에서는 "생일 케이크"가 된 듯한 환각이 나타났습니다. 반면, 해당 팀의 모델은 이 문제를 발견하지 못했습니다.
세 번째 차이점은 사용할 수 있는 이미지 유형입니다.COCO에는 자연스러운 이미지만 포함되어 있으므로 위 그림의 네 번째와 같은 만화 이미지는 COCO로 훈련된 모델에 "봉제 인형", "물고기", "자동차 측면" 및 기타 존재하지 않는 것과 같은 "연관성" 간섭을 일으킵니다. 이와 대조적으로 개념적으로 훈련된 모델은 이러한 이미지를 쉽게 처리할 수 있습니다.
DALL-E 모델의 출시는 이 분야의 많은 연구자들을 한숨 돌리게 했습니다. 데이터가 바로 AI의 초석이라는 것입니다. 당신도 기적을 일으키고 싶나요? 개념적 캡션 데이터 세트부터 시작해 보겠습니다!
입장 https://orion.hyper.ai/datasets 또는 클릭하세요원본 기사를 읽어보세요, 더 많은 데이터 세트를 얻으세요!
뉴스 출처:
https://openai.com/blog/dall-e/
DALL-E 신문 주소:
https://arxiv.org/abs/2102.12092
DALL-E 프로젝트 GitHub 주소:
https://github.com/openai/dall-e
개념 캡션 논문 주소: