Command Palette
Search for a command to run...
PyTorch 행렬 곱셈 방법 요약 및 문제 해결
머신 러닝과 딥 러닝에서 행렬 연산은 컴퓨팅 효율성을 개선하는 가장 일반적이고 효과적인 방법입니다. 특성과 가중치가 벡터로 저장되므로 행렬 연산이 특히 중요합니다.경사 하강법, 역전파법, 행렬 분해와 같은 중요한 머신 러닝 방법에는 모두 행렬 연산이 필요합니다.
딥 러닝에서 신경망은 행렬에 가중치를 저장하고, GPU에서 선형 대수 기반 연산을 통해 행렬에 대한 간단하고 빠른 계산을 수행할 수 있습니다.

소규모 행렬 연산은 for 루프를 사용하여 빠르게 계산할 수 있습니다. 하지만 엄청난 양의 데이터를 접하게 되면,루프 문은 작업 속도를 느리게 만듭니다.이때 우리는 종종 행렬 곱셈을 사용하는데, 이는 계산의 효율성을 크게 향상시킬 수 있습니다.
일반적인 행렬, 벡터 및 스칼라 곱셈 방법
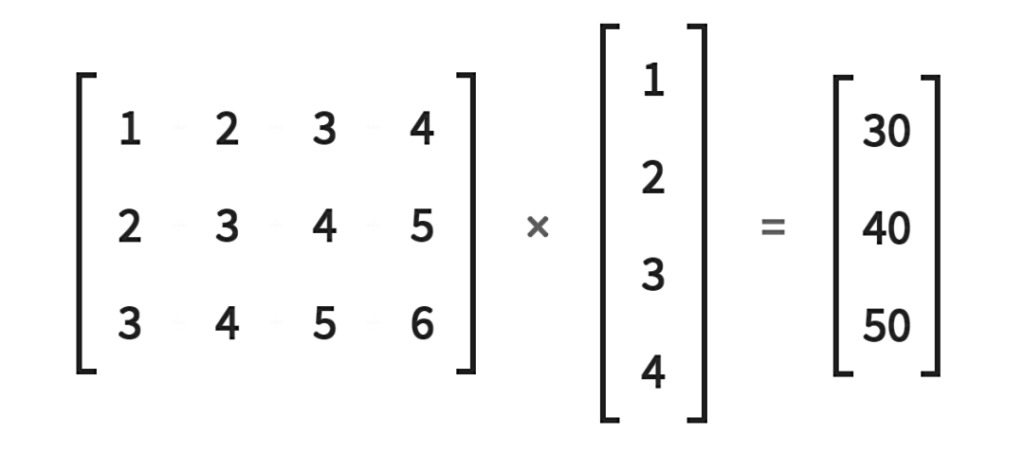
- 토치(mm) 2D 행렬 곱셈
torch.mm(mat1,ma2,out=None), 여기서 mat1(n*m), mat2(m*d)의 출력 차원은 (n*d)입니다.
참고: 두 개의 2D 행렬의 행렬 곱셈을 계산하며 브로드캐스팅을 지원하지 않습니다.
- torch.bmm() 3D 배치 행렬 곱셈
여기서 bmat1(b*n*m), bmat2(B*m*d)인 경우 출력 out의 차원은 (B*n*d)입니다.
참고: 이 함수의 두 입력은 동일한 첫 번째 차원(배치 차원을 나타냄)을 갖는 3차원 행렬이어야 합니다. 방송이 지원되지 않습니다.
- torch.matmul() 혼합 행렬 곱셈
torch.matmul(input,other,out=None), 이 방법은 좀 더 복잡하므로 문서를 참조하는 것이 좋습니다. 이는 두 텐서의 행렬곱입니다. 계산 결과는 텐서의 차원에 따라 달라지며 브로드캐스팅을 지원합니다.
- torch.mul() 행렬 요소별 곱셈
torch.mul(mat1,other, out=None)은 최종 곱셈이 충족되고 브로드캐스팅이 지원되는 한, other multiplier가 스칼라이거나 모든 차원의 행렬일 수 있습니다.
- torch.mv() 행렬-벡터 곱셈
torch.mv(mat, vec, out=None)은 행렬 mat와 벡터 vec를 곱합니다. mat가 n×m 텐서이고 vec가 m개 요소의 1차원 텐서인 경우, 브로드캐스팅 지원 없이 출력은 n개 요소의 1차원 텐서가 됩니다.
- torch.dot() 텐서 도트 곱셈
torch.dot(tensor1, tensor2)는 두 텐서의 내적을 계산합니다. 두 텐서는 모두 1차원 벡터이며 브로드캐스팅을 지원하지 않습니다.
포럼 인기 질문
질문: for 루프를 사용하지 않고 데이터 벡터의 배치를 곱하는 방법은 무엇입니까?
입력 모양: N x M x VectorSize 가중치 모양: M x VectorSize x VectorSize 대상 출력 모양: N x M x VectorSize
N은 배치 크기를 나타내고, M은 벡터의 개수를 나타내고, VectorSize는 벡터의 크기를 나타냅니다.
다음 그림과 같이: 해결책:
N, M, V=2, 3, 5a = torch.randn(N, M, V)b = torch.randn(M, V, V)a_expand = a.unsqueeze(-2)b_expand = b.expand(N, -1, -1, -1)c = torch.matmul(a_expand, b_expand).squeeze(-2)
원래 게시물 주소:https://discuss.pytorch.org/t/batch-matrix-vector-multiplication-without-for-loop/112841
질문: 배치 벡터 입력으로 행렬-벡터 곱셈을 계산할 때 RuntimeError가 발생합니다.
주어진:
# (batch x inp)v = torch.randn(5, 15)# (inp x output)M = torch.randn(15, 20)
믿다:
# (batch x output)out = torch.Tensor(5, 20)for i, batch_v in enumerate(v):out[i] = (batch_v * M).t()
그러나 (i) 곱셈은 동일한 차원의 두 입력에 대해 다음과 같은 오류를 발생시킵니다. RuntimeError: /home/enrique/code/vendor/pytorch/torch/lib/TH/generic/THTensorMath.c:623에서 텐서 크기가 일치하지 않습니다.
이 오류는 왜 발생합니까? 행 벡터에 대한 루프를 피할 수 있는 방법이 있나요?
해결책:
*는 요소별 곱셈을 나타냅니다. Python 3을 사용하는 경우 @ 연산자를 사용하여 행렬-벡터 곱셈과 행렬-행렬 곱셈을 수행할 수 있습니다.
배치된 벡터 행렬은 행렬-행렬 곱셈이므로 batch_v.mm(M)을 사용할 수도 있습니다.
또한, bmm 및 baddbmm과 같은 메서드를 사용하여 Python에서 루프 연산을 제거할 수도 있습니다.
원래 게시물 주소:https://discuss.pytorch.org/t/matrix-vector-multiply-handling-batched-data/203
질문: 루프 문을 사용하지 않고 행렬-벡터 곱셈을 계산하는 방법은 무엇입니까?
루프를 사용하지 않고 2×2 행렬을 크기가 2인 세 벡터로 곱하려면 어떻게 해야 합니까?
주목:
1. 루프문을 사용할 경우 코드는 다음과 같습니다.
A=torch.tensor([[1.,2.],[3.,4.]])b=torch.tensor([[3.,4.], [5.,6], [7.,8.]])res = []for i in range(b.shape[0]):res.append(torch.matmul(A, b[i]))
2. torch.matmul(A.repeat((2,1,1))을 시도한 후, b)가 작동하지 않습니다.
해결책:
이는 a.matmul(bt())를 사용하여 달성할 수 있습니다.
원래 게시물 주소:https://discuss.pytorch.org/t/vectorize-matrix-vector-multiplication/88051
이 공식 계정은 최신 PyTorch 정보와 개발 기술을 지속적으로 업데이트할 예정입니다. 팔로우해 주세요!