Command Palette
Search for a command to run...
만화 번역, AI 임베딩, 도쿄대 논문 AAAI'21에 포함

최근 만화 텍스트의 자동 번역에 대한 연구가 뜨거운 논의를 불러일으켰습니다. 도쿄대 박사학위 소지자 2명으로 구성된 Mantra 팀은 AAAI 2021에 논문을 발표했습니다. Mantra 프로젝트는 일본 만화에 대한 자동화된 기계 번역 도구를 제공하는 것을 목표로 합니다.
최근 도쿄대 만트라팀, 야후(일본) 등 기관 공동 발표 《완전 자동화된 만화 번역을 향하여》(논문 주소 https://arxiv.org/abs/2012.14271)이 논문은 학계와 2차원 커뮤니티의 주목을 받았습니다.

Mantra 팀은 성공적으로 달성했습니다.만화 속 대사, 분위기 단어, 라벨 및 기타 텍스트가 자동으로 인식되고, 캐릭터가 구별되고 맥락이 연결됩니다. 마지막으로, 번역된 텍스트가 정확하게 대체되어 버블 영역에 삽입됩니다.
이 마법같은 번역 도구 덕분에 번역팀과 만화 팬들은 매우 행복해질 것입니다.
논문 게재, 데이터 세트 공개, 상용화
과학적 연구 측면에서 이 논문은 AAAI 2021에 수락되었습니다. 연구팀은 또한 다양한 스타일(판타지, 로맨스, 격투, 서스펜스, 라이프)의 만화 5개로 구성된 번역 평가 데이터 세트를 공개했습니다.
OpenMantra 만화 번역 평가 데이터 세트
서류 주소:https://arxiv.org/abs/2012.14271
데이터 형식: 주석이 달린 JSON 파일 및 원시 이미지
데이터 내용:1593 문장, 848 장면, 214 만화 페이지
데이터 크기: 36.8MB
업데이트: 2020년 12월 7일
다운로드 주소:https://orion.hyper.ai/datasets/14137
제품화 측면에서,Mantra는 패키지형 자동 번역 엔진을 출시할 계획입니다.출판사에 자동화된 만화 번역 및 배포 서비스를 제공할 뿐만 아니라, 개인 사용자를 위한 서비스도 출시합니다.
아래는 Mantra 공식 트위터 계정에서 선택한 일본 만화 "Surrounding Men"의 번역 중 일부입니다.여러 컷으로 구성된 이 가벼운 댄스 스타일의 만화는 일상 생활에서 흔히 사용되는 디지털 기기를 인간형으로 묘사하여 기쁨과 즐거운 사랑으로 가득 차 있습니다.:
슬라이드"Nearby Man"의 일본어 원본 버전을 보세요
중국어와 영어 버전의 자동 기계 번역
인식, 번역, 내장은 모두 중요한 단계입니다.
구체적인 구현 단계는 Mantra 연구팀의 논문 "완전 자동화된 만화 번역을 향하여"에서 자세히 설명되어 있습니다.
첫 번째 단계는 텍스트를 찾는 것입니다
자동화된 만화 번역을 달성하기 위한 첫 번째 단계는 텍스트 영역을 추출하는 것입니다.
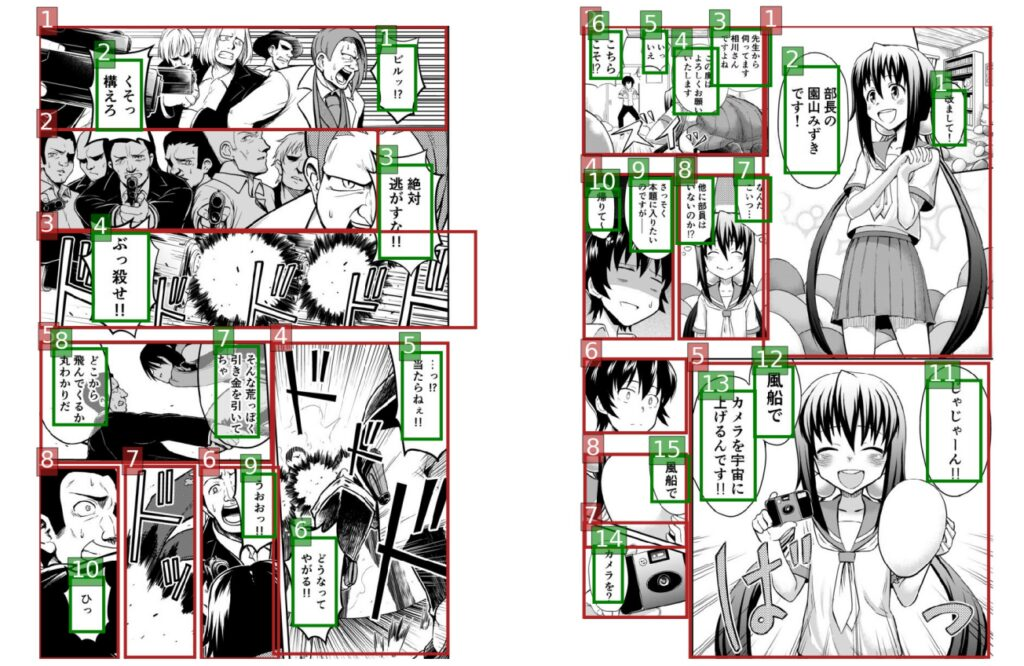
하지만 만화의 특수성으로 인해 다양한 캐릭터의 대사, 의성어, 텍스트 주석 등이 모두 만화 그림에 표시됩니다. 만화가들은 거품, 다양한 글꼴, 과장된 글꼴을 사용해 다양한 효과로 텍스트를 표시합니다.
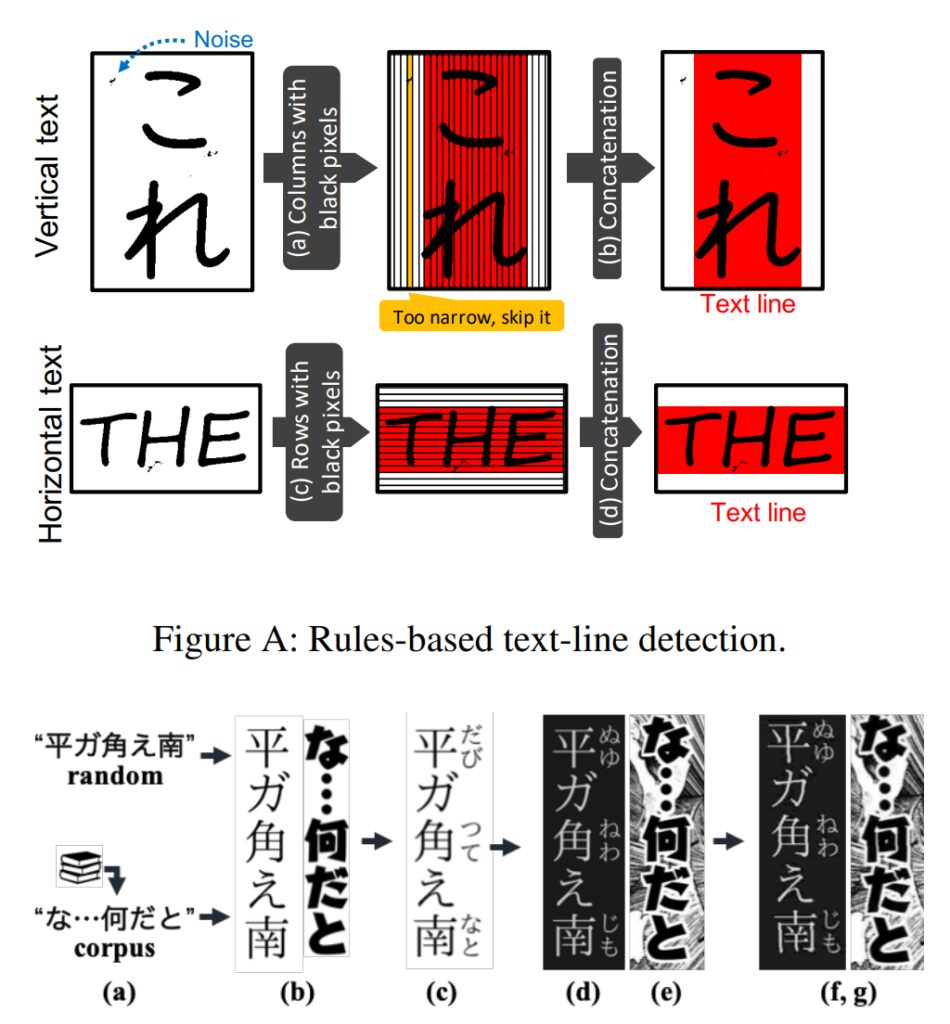
연구팀은 만화에 사용된 다양한 글꼴과 손으로 그린 스타일로 인해 가장 진보된 OCR 시스템(예: Google Cloud Vision API)조차도 만화 텍스트에서는 성능이 떨어진다는 것을 발견했습니다.
따라서 연구팀은 만화에 최적화된 텍스트 인식 모듈을 개발했는데, 이 모듈은 텍스트 줄을 감지하고 각 텍스트 줄에 있는 문자를 식별하여 특수문자를 인식할 수 있습니다.
2단계 콘텐츠 식별
만화에서 가장 흔한 텍스트는 캐릭터 간의 대화이며, 대화 텍스트 풍선은 여러 조각으로 잘립니다.
이를 위해서는 자동화된 기계 번역이 역할을 정확하게 구분하고 주어 간의 연결에 주의를 기울여야 하며 맥락에서 반복을 피해야 하므로 기계 번역에 대한 요구 사항이 더 높아집니다.
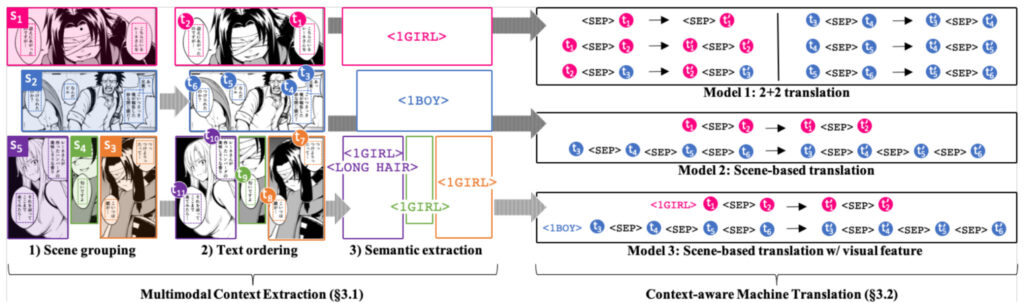
이 단계에서는 맥락 인식, 감정 인식 및 기타 방법을 통해 이를 달성하는 것이 필요합니다. 컨텍스트 인식 측면에서 Mantra 팀은 텍스트 그룹화, 텍스트 읽기 순서, 시각적 의미 추출이라는 세 가지 방법을 사용하여 다중 모드 컨텍스트 인식을 달성했습니다.
3단계 자동 임베딩
만트라 자동화 엔진은 문자를 구별하고 맥락에 맞게 정확하게 번역할 수 있을 뿐만 아니라, 만화 번역에서 가장 시간이 많이 걸리고 노동 집약적인 부분인 문자 삽입 작업도 해결할 수 있습니다.

삽입 과정에서는 먼저 삽입된 영역을 지운 후 문자를 삽입해야 합니다. 일본어, 중국어, 영어 문자의 모양, 철자, 조합, 그리고 연결된 독해 방식이 모두 다르기 때문에 이 과정은 특히 어렵습니다.
이 단계에서는 페이지 매칭 → 텍스트 상자 감지 → 텍스트 버블의 픽셀 계산 → 연결된 버블 분할 → 언어 간 정렬 → 텍스트 인식 → 컨텍스트 추출의 순으로 진행해야 합니다.
실험: 데이터 세트 및 모델 테스트
논문의 실험 부분에서 Mantra 팀은 현재 여러 언어를 포함하는 만화 데이터 세트가 없다고 언급했기 때문에 OpenMantra(오픈 소스) 및 PubManga 데이터 세트를 생성했습니다. OpenMantra는 기계 번역을 평가하는 데 사용되며 1,593개의 문장, 848개의 장면, 214페이지의 만화가 포함되어 있습니다. Mantra 팀은 전문 번역가에게 데이터 세트를 영어와 중국어로 번역해 달라고 요청했습니다.

PubManga 데이터 세트는 다음의 주석이 포함된 구성된 코퍼스를 평가하는 데 사용됩니다. 1) 텍스트와 프레임의 경계 상자 2) 일본어와 영어 텍스트(문자열) 3) 프레임과 텍스트의 읽기 순서.
모델을 훈련하기 위해 팀은 다음을 준비했습니다. 일본어와 영어로 된 만화 페이지 842,097쌍, 일본어-영어 문장 총 3,979,205쌍이 들어 있습니다.구체적인 방법은 논문에서 확인할 수 있습니다. 최종 모델 효과 평가는 수동으로 수행됩니다. Mantra 팀은 초대했습니다전문 일본어-영어 번역가 5명전문적인 번역 평가 프로그램을 통해 문장에 점수를 매겨보세요.
프로젝트 배경: 흥미로운 영혼들이 함께 배우는 것
현재 이 논문은 AAAI 2021에 포함되었으며, 제품화 작업도 꾸준히 진행되고 있습니다. Mantra 팀의 트위터를 보면 많은 만화가 Mantra를 자동 기계 번역에 성공적으로 활용하고 있는 것을 알 수 있습니다.
이러한 보물 프로젝트는 도쿄 대학의 박사과정 학생 두 명에 의해 완성되었습니다. CEO인 이시와타리 쇼노스케와 CTO인 히나미 료타는 모두 도쿄대학교에서 박사학위를 취득했으며, 2020년에 Mantra 팀을 창립했습니다.

CEO 이시와 쇼노스케,그는 2010년에 도쿄대학교 정보과학과에 학부로 입학하여 박사 학위를 받았습니다. 2019년에.그는 주로 기계 번역, 사전 생성을 포함한 자연어 처리 분야의 연구 개발에 주력하고 있으며, 본 논문의 두 번째 저자이기도 합니다.
이시와 샹지스케는 풍부한 연구 경험을 가지고 있다는 점도 언급할 가치가 있습니다. 그는 CMU에서 교환 학자로 활동했을 뿐만 아니라, 2016년부터 2017년까지 반년간 베이징에 있는 Microsoft Research Asia에서 인턴으로 일했습니다. 당시 그는 MSRA 수석 연구원인 류슈지에(Liu Shujie) 팀에서 NLC(자연어 컴퓨팅) 연구에 참여했습니다.
CTO인 히나미 료타이시는 쇼노스케와 같은 해에 학교에 입학하여 이미지 인식 분야에 집중했습니다.2016-17년에 저는 이시와 쇼노스케와 함께 Microsoft Research Asia에서 인턴으로 일했습니다.
서로 보완적인 기술을 가진 이 두 친구는 만트라의 작업 대부분을 완성했습니다. 머리카락 양부터 결과까지 부럽지 않나요?
Mantra에 대해 더 자세히 알고 싶으시다면 논문을 방문하세요.https://arxiv.org/abs/2012.14271)、프로젝트 공식 홈페이지(https://mantra.co.jp/)또는 데이터 세트를 다운로드하세요(https://orion.hyper.ai/datasets/14137)추가 연구를 위해서.