Command Palette
Search for a command to run...
원래의 예술가를 해방시켜라! Wav2Lip은 AI를 사용하여 음악을 듣고 캐릭터의 입술 움직임을 동기화합니다.

"보는 것이 믿는 것이다"이런 방식은 AI 기술 앞에서는 효과가 없게 되었습니다. 얼굴 바꾸기와 입술 동기화 기술이 끊임없이 등장하고 있으며, 그 효과는 점점 더 현실감이 더해지고 있습니다. 오늘은 소개하겠습니다 웨이브투립 이 모델에는 원본 비디오와 대상 오디오만 있으면 두 비디오를 하나로 결합할 수 있습니다.
최근 몇 년 동안 할리우드 애니메이션은 '주토피아', '겨울왕국' 등 뛰어난 퀄리티의 작품들을 잇따라 선보이며 흥행 수익 10억 달러 이상을 달성했습니다.입술 움직임만 예로 들면, 매우 엄격하며, 애니메이션 캐릭터의 입술 움직임은 실제 사람의 입술 움직임과 거의 동일합니다.
이러한 효과를 얻으려면 매우 복잡한 과정이 필요하며, 이를 위해 막대한 인력과 물적 자원이 필요합니다. 따라서 비용을 절감하기 위해 많은 애니메이션 제작자는 비교적 간단한 입술 움직임만을 사용합니다.
이제 AI는 콘셉트 아티스트의 작업을 쉽게 하기 위해 노력하고 있습니다. 인도 하이데라바드 대학교와 영국 바스 대학교의 팀이 올해 ACM MM2020에 논문을 발표했습니다."야외에서 음성과 입술을 자연스럽게 연결하려면 립싱크 전문가만 있으면 됩니다.",Wav2Lip이라는 AI 모델이 제안되었는데, 이 모델은 사람의 비디오와 대상 음성만 있으면 두 영상을 하나로 결합하여 두 영상을 원활하게 연동할 수 있습니다.
립싱크 기법 Wav2Lip, 효과가 너무 뛰어나요
실제로 립싱크에는 다양한 기술이 존재합니다. 딥러닝 기반 기술이 등장하기 전에도 캐릭터의 입술 모양을 실제 음성 신호와 일치시키는 기술은 있었습니다.
하지만 Wav2Lip은 모든 방법 중에서 절대적인 우위를 보여줍니다. 기존의 다른 방법들은 주로 정적 이미지를 기반으로 대상 음성에 맞는 립싱크 영상을 출력하는데, 립싱크는 동적으로 말하는 캐릭터의 경우 효과적이지 않은 경우가 많습니다.
Wav2Lip은 동적 비디오에서 입술 변환을 직접 수행하고 대상 음성과 일치하는 비디오 결과를 출력할 수 있습니다.
또한, 영상뿐만 아니라 립싱크부터 애니메이션 사진까지 제공하므로 이제부터 이모티콘 패키지가 더욱 풍부해질 것입니다!

수동 평가가 표시됨Wav2Lip으로 생성된 비디오는 기존 방법과 비교했을 때 90% 이상의 확률로 기존 방법보다 우수한 성능을 보입니다.
이 모델은 얼마나 효과적입니까? 슈퍼뉴로가 몇 가지 테스트를 실시했습니다. 다음 영상은 공식 데모의 실행 효과를 보여줍니다. 입력 자료는 공무원이 제공한 시험 자료와 Super Neural Network가 선정한 중국어, 영어 시험 자료입니다.
원본 비디오 입력의 문자가 말을 하지 않습니다.
AI 모델 연산을 통해 캐릭터의 입술 모양이 입력 음성과 동기화됩니다.
공식 데모의 애니메이션 영상에서 그 효과가 완벽하다는 것을 확인할 수 있습니다. 초신경 실제 인물 테스트에서는 입술의 미세한 변형과 떨림을 제외하면 전반적인 입술 동기화 효과는 비교적 정확했습니다.
튜토리얼이 나왔습니다. 3분만에 배워보세요
이걸 보고 나니, 당신도 해보고 싶은 마음이 생기셨나요? 이미 대담한 아이디어가 있다면, 지금 당장 시작해 보는 건 어떨까요?
현재 이 프로젝트는 GitHub에서 오픈 소스로 공개되었으며, 저자는 대화형 데모, Colab 노트북, 완전한 학습 코드, 추론 코드, 사전 학습된 모델, 튜토리얼을 제공합니다.
프로젝트 세부 사항은 다음과 같습니다.
프로젝트 이름:Wav2Lip
GitHub 주소:
https://github.com/Rudrabha/Wav2Lip
프로젝트 운영 환경:
- 언어: Python 3.6+
- 비디오 처리 프로그램: ffmpeg
사전 학습된 얼굴 감지 모델을 다운로드하세요.
https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth
위의 환경을 준비하는 것 외에도 다음 소프트웨어 패키지를 다운로드하여 설치해야 합니다.
- 리브로사==0.7.0
- 넘파이==1.17.1
- opencv-contrib-python>=4.2.0.34
- opencv-python==4.1.0.25
- 텐서플로우==1.12.0
- 토치==1.1.0
- 토치비전==0.3.0
- tqdm==4.45.0
- 번호==0.48
하지만 이런 번거로운 절차를 준비할 필요는 없습니다.인물의 사진/비디오(CGI인물도 가능)와 오디오(합성 오디오도 가능)만 준비하면 됩니다.국내 머신러닝 컴퓨팅 파워 컨테이너 서비스 플랫폼에서 단 한번의 클릭으로 실행이 가능합니다.
문:https://openbayes.com/console/openbayes/containers/EiBlCZyh7k7
현재 플랫폼에서는 매주 무료 vGPU 사용 시간을 제공하고 있어 누구나 쉽게 튜토리얼을 완료할 수 있습니다.
이 모델에는 Wav2Lip, Wav2Lip+GAN, Expert Discriminator의 세 가지 가중치가 있습니다. 그 중 마지막 두 가지 방법은 Wav2Lip 모델을 단독으로 사용하는 것보다 효과가 훨씬 더 좋습니다. 이 튜토리얼에서 사용된 가중치는 Wav2Lip+GAN입니다.
모델 작성자는 다음을 강조합니다.오픈 소스 코드의 모든 결과는 연구/학업/개인적인 목적으로만 사용되어야 합니다.이 모델은 LRS2(Lip Reading Sentences 2) 데이터 세트를 기반으로 학습되었으므로 모든 형태의 상업적 사용은 엄격히 금지되어 있습니다.
연구진은 기술 남용을 방지하기 위해 Wav2Lip의 코드와 모델을 사용하여 생성된 모든 콘텐츠는 합성으로 표시해야 한다고 강력히 권고했습니다.
그 핵심 기술: 립싱크 판별기
Wav2Lip은 어떻게 오디오를 듣고 립싱크를 그렇게 정확하게 할 수 있을까요?
획기적인 발전을 이루는 열쇠는 다음과 같다고 합니다.연구원들은 립싱크 판별기를 사용했습니다.이를 통해 생성기는 정확하고 사실적인 입술 움직임을 지속적으로 생성해야 합니다.
또한, 이 연구에서는 판별기에서 단일 프레임 대신 여러 개의 연속된 프레임을 사용하고 시간적 상관관계를 설명하기 위해 시각적 품질 손실(대조 손실만이 아님)을 사용하여 시각적 품질을 개선합니다.
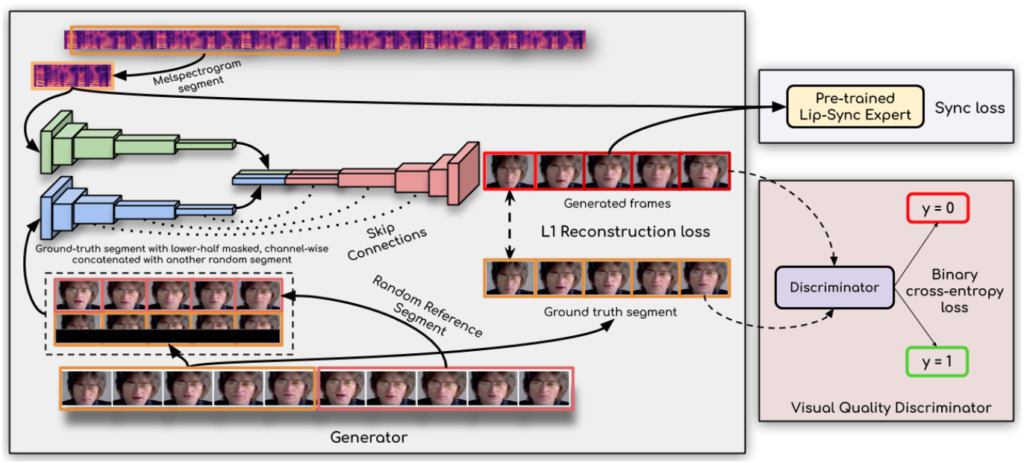
연구자들은 다음과 같이 말했습니다.Wav2Lip 모델은 거의 보편적이어서 모든 얼굴, 모든 음성, 모든 언어에 적용할 수 있으며 모든 비디오에 대해 높은 정확도를 달성할 수 있습니다.원본 비디오와 완벽하게 병합할 수 있으며, 애니메이션 얼굴을 변환하는 데 사용할 수도 있고, 합성된 음성을 가져오는 것도 가능합니다.
이 유물이 또 다른 유령 영상의 물결을 일으킬 가능성이 있습니다...
서류 주소:
데모 주소:
https://bhaasha.iiit.ac.in/lipsync/
-- 위에--