Command Palette
Search for a command to run...
한 기사에서 AlphaFold 2의 PDB 단백질 구조 데이터 세트에 대해 알아보세요.
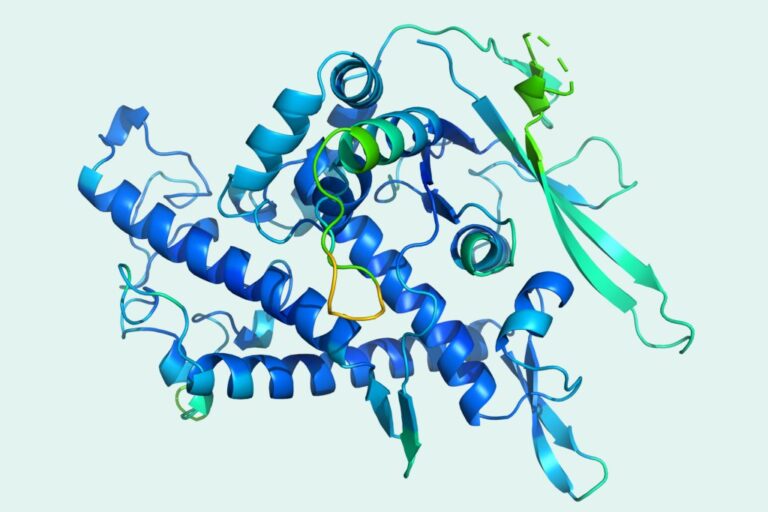
딥마인드의 최신 세대 알고리즘인 알파폴드 2는 최근 "단백질 올림픽"이라고 불리는 CASP에서 다른 경쟁자들을 완전히 물리치고 놀라운 돌파구를 마련해 과학 연구계 전체를 충격에 빠뜨렸습니다. 이러한 과학적 연구 결과에 압도된 후, 알고리즘을 뒷받침하는 데이터 세트를 살펴보겠습니다.
지난 이틀 동안 우리는 DeepMind의 차세대 인공지능 알고리즘인 AlphaFold 2에 대한 소식으로 폭격을 받았는데, 특히 생물학 분야에서 획기적인 진전을 이루었다고 할 수 있습니다.
DeepMind의 공식 발표에 따르면, 딥러닝 알고리즘인 AlphaFold 2는 지난 50년 동안 생물학 분야의 주요 문제를 성공적으로 해결해 왔습니다.
이 알고리즘은 극저온 전자 현미경(CryoEM), 핵자기 공명 또는 X선 결정학과 같은 실험적 기술을 사용하여 풀린 3차원 구조와 비교할 만큼 정확도가 높아 아미노산 서열을 기반으로 단백질의 3차원 구조를 정확하게 예측할 수 있습니다.

이 중요한 사건은 생물학자들을 들뜨게 했지만, 업계의 많은 사람들을 두려움에 떨게 했으며, 그들은 딥러닝을 배우기 위해 직업을 바꿀 것이라고 말했습니다.
하지만 모두가 이 과학적인 연구 결과에 주목하는 가운데, 그 뒤에 숨은 영웅을 잊지 마세요. PDB 단백질 구조 데이터 세트는 단백질과 핵산의 3차원 구조 데이터를 수집하는 데 전념하는 데이터 세트입니다.
이 데이터 세트는 획기적인 혁신을 위해 필수적입니다.
DeepMind에 따르면, 해당 팀은 공개 데이터를 이용해 시스템을 훈련시켰습니다.이러한 데이터는 단백질 구조 데이터 세트인 PDB와 알려지지 않은 구조의 단백질 서열을 포함하는 대규모 데이터베이스인 UniProt에서 나온 것으로, 두 데이터베이스를 합치면 약 170,000개의 단백질 구조가 포함됩니다.
안에,PDB는 단백질과 핵산의 3차원 구조에 대한 데이터 세트입니다. 1971년부터 시작되어 매우 오랜 역사를 가지고 있습니다.
미국 브룩헤이븐 국립연구소의 월터 해밀턴이 이 데이터베이스를 구축하기로 결정했습니다. 1998년 10월, PDB는 러트거스 대학의 헬렌 M. 버먼이 이끄는 구조 생물정보학 연구 협력소(RCSB)로 이전되었으며, 역시 RCSB 회원이었습니다.

2003년에PDB는 PDB 자원을 감독하기 위해 국제 기구인 wwPDB(Worldwide Protein Database)로 발전했습니다. PDBe(유럽), RCSB(미국), PDBj(일본)를 포함한 wwPDB의 다른 회원도 PDB에 대한 데이터 축적, 처리 및 출판을 위한 센터를 제공합니다.

PDB에 저장된 데이터는 전 세계 과학자들이 제출한 것이지만, 제출된 각 데이터는 wwPDB 직원이 검토하여 주석을 달아 데이터의 타당성을 검증한다는 점을 언급하는 것이 좋습니다. PDB와 이를 제공하는 소프트웨어는 이제 대중에게 무료로 제공됩니다.
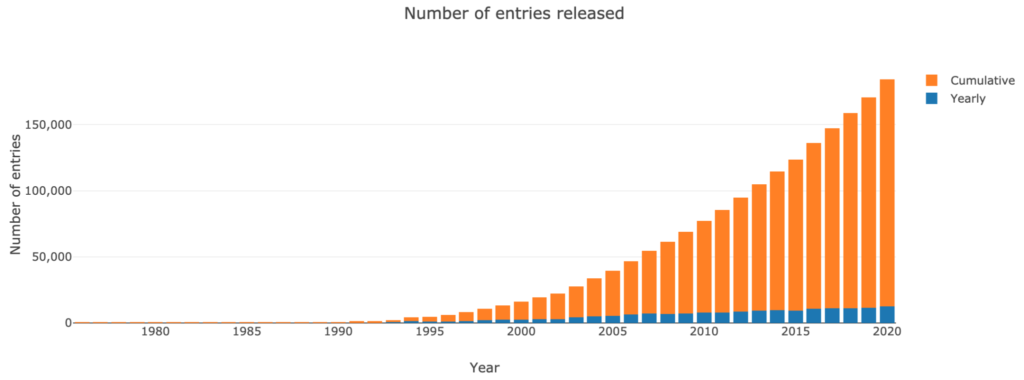
14만 개가 넘는 구조물, PDB에는 어떤 정보가 들어 있나요?
지난 수십 년 동안 PDB의 구조 수는 거의 기하급수적으로 증가했습니다.
- 1982년에 100개;
- 1993년에는 1,000명
- 1999년에는 10,000명
- 2014년에는 10만 명.
그러나 2007년 이후로 새로운 단백질 구조가 축적되는 속도는 안정화된 것으로 보입니다.
전 세계의 구조 생물학자들은 X선 결정학, NMR 분광법, 극저온 전자 현미경과 같은 방법을 사용하여 분자 내 각 원자의 상대적인 위치를 결정합니다. 그런 다음 이러한 구조적 정보를 제출하면 wwPDB에서 주석을 달아 데이터베이스에 공개적으로 게시합니다.
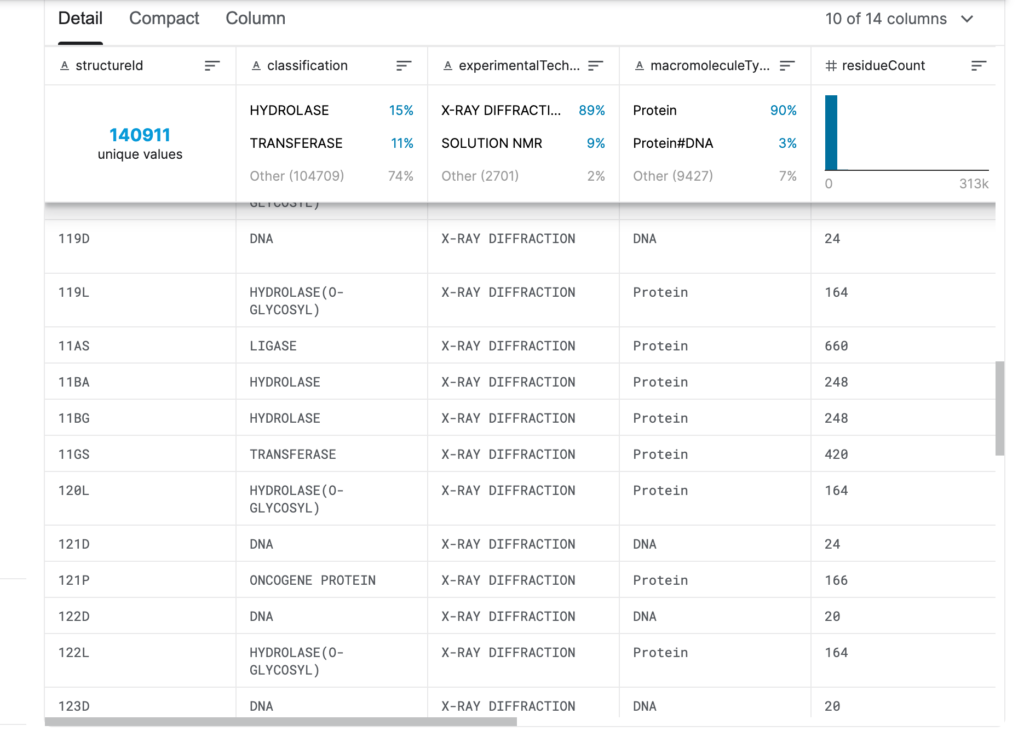
PDB 데이터 세트에서 리보솜, 종양 유전자, 약물 표적, 심지어 전체 바이러스의 구조를 검색할 수 있습니다.그러나 PDB에 보관된 구조물의 수가 너무 많아서 필요한 정보를 찾는 것이 어려운 일입니다.
PDB 데이터 세트의 정보는 주로 다음과 같습니다.단백질/핵산의 출처, 단백질/핵산 분자의 구성, 원자 좌표, 구조를 결정하는 데 사용된 실험 방법, 그리고 온도 요인 및 구조 결정 인자와 같은 기타 데이터와 정보입니다.
어떻게 다운로드하나요?
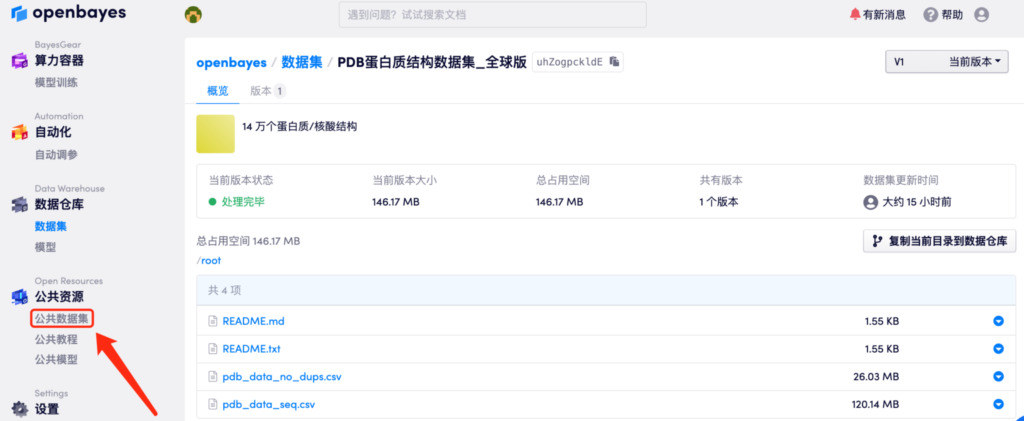
해당 데이터 세트는 현재 Hyperneuron과 openbayes.com의 공식 웹사이트에서 이용 가능합니다. 방문하다:https://orion.hyper.ai/datasets/13906 또는 "원문 읽기"를 클릭하면 클릭 한 번으로 데이터 세트를 얻을 수 있습니다.
■ PDB 단백질 구조 데이터셋 상세 정보
출시 시간:1971년부터 수집됨
출판사:wwPDB
포함된 수량:140,000개 이상의 단백질/핵산 구조
데이터 형식:csv 파일
데이터 크기:27MB(압축 해제 후 146MB)
다운로드 주소:https://orion.hyper.ai/datasets/13906
DeepMind와 동일한 데이터 세트, 당신도 그럴 자격이 있어요~
어떻게 사용하나요?
당사 파트너사인 OpenBayes는 머신 러닝을 위한 클라우드 컴퓨팅 성능을 제공하는 클라우드 서비스입니다. 그들은 대규모 슈퍼컴퓨팅 클러스터를 보유하고 있으며, GPU 클러스터 아키텍처는 특별히 매트릭스 컴퓨팅을 위해 설계되었습니다. AI 애플리케이션을 위한 컴퓨팅 파워 컨테이너를 제공하며, 시작하기가 매우 쉽고 바로 사용할 수 있습니다.
현재 OpenBayes의 컴퓨팅 파워 컨테이너 제품은 이미 다음을 지원합니다. TensorFlow, PyTorch, MXNet 및 기타 CPU 및 GPU 환경, 다양한 버전과 유형의 표준 머신 러닝 프레임워크와 다양한 공통 종속성.
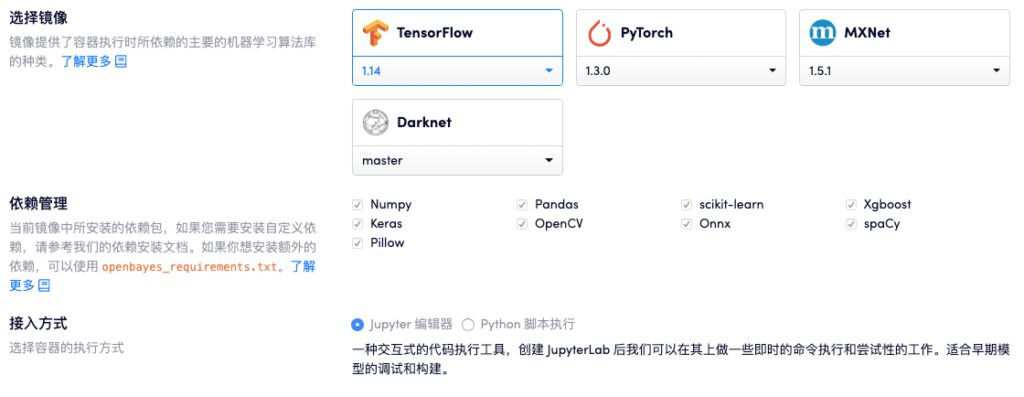
현재 OpenBayes 컴퓨팅 컨테이너는 표준 라이브러리를 지원합니다.그리고 제공하다 CPU, NVIDIA T4, NVIDIA Tesla V100 및 기타 컴퓨팅 리소스방대한 데이터에 대한 중앙 집중식 학습이든 저전력 모델 상주 운영이든 사용자 요구 사항을 쉽게 충족할 수 있습니다.

CPU부터 T4, V100까지 다양한 컴퓨팅 컨테이너 구성 OpenBayes 지원스크립트 업로드 및 JupyterLab 편집기온라인 프로그래밍을 한 후 모델 훈련을 합니다.
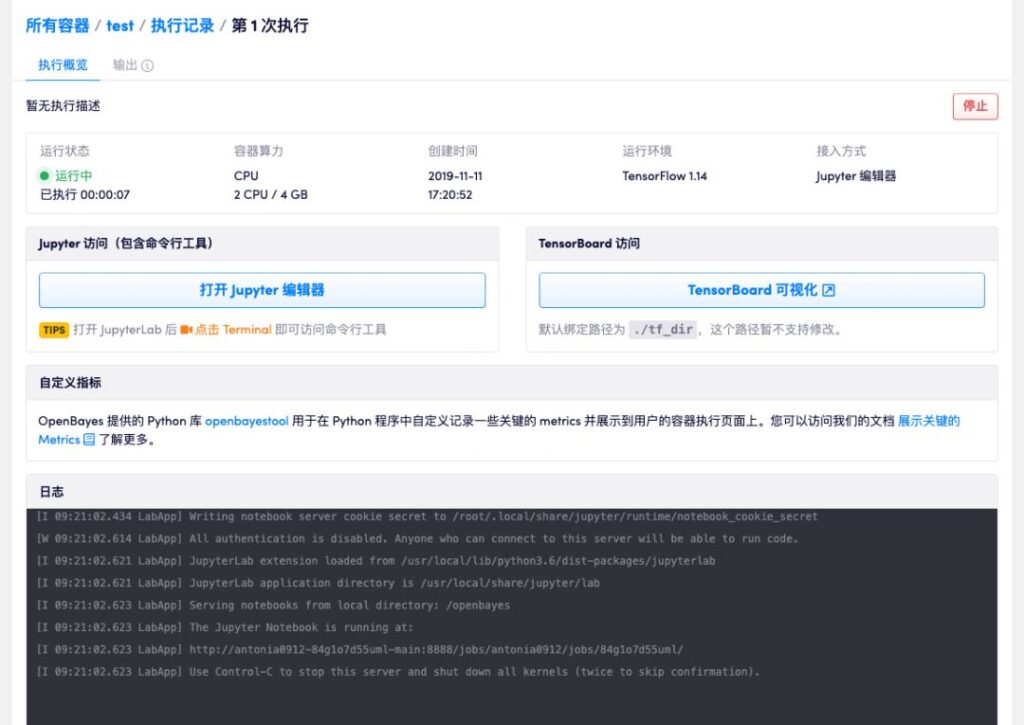
명확하고 간결한 실행 프로세스전체 튜토리얼: https://openbayes.com/docs/quickstart/
GPU 컴퓨팅 파워를 즐기려면 새 사용자로 등록하세요
openbayes.com을 방문하세요, 공식 홈페이지를 클릭해 바로 등록하세요. 내부 테스트 기간 동안 매주 선물이 제공되니, 컴퓨팅 파워를 놓고 반 친구나 동료들과 경쟁할 필요가 없습니다~
이벤트 설명 openbayes.com을 방문하세요 초대 코드 [HyperAI]를 사용하여 새로운 사용자로 등록하세요.즐길 수 있습니다
사용 가능한 CPU 할당량:주당 300분
무료 vGPU 할당량:주당 180분
PDB 전체 데이터 세트 수집:
https://www.rcsb.org/#Category-download
PDB 데이터 세트의 파일은 텍스트 편집기로 직접 볼 수 있지만 시각화 도구를 사용하는 것이 더 좋습니다. 공식적으로 권장되는 시청 프로그램은 스위스 PDB 뷰어입니다.
https://spdbv.vital-it.ch/disclaim.html#
기타 참고문헌:
https://www.novopro.cn/articles/201912021193.html
-- 위에--