Command Palette
Search for a command to run...
상하이 교통대학교, MedMNIST 의료 영상 분석 데이터 세트 및 새로운 벤치마크 공개
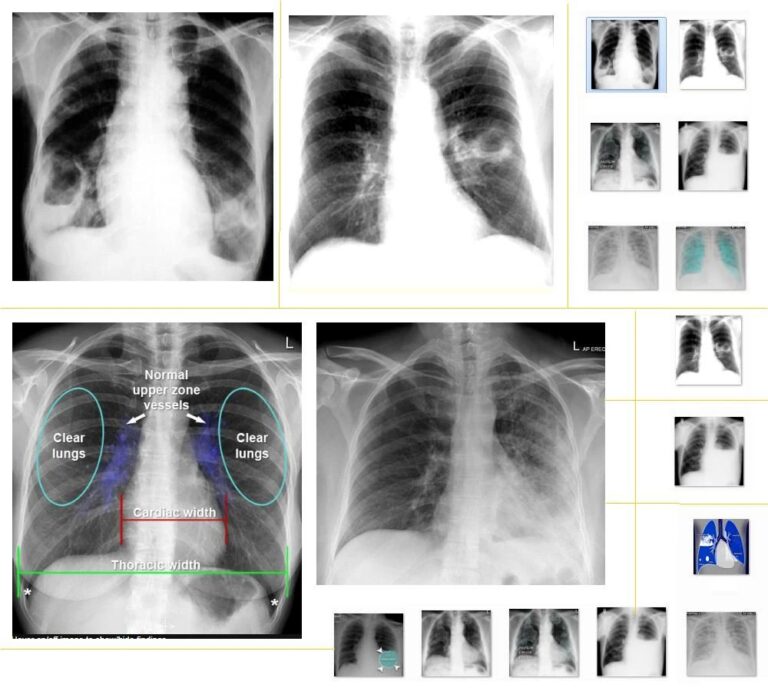
의료 영상 분석은 매우 복잡한 학제적 분야입니다. 최근 상하이 교통대학은 MedMNIST 데이터 세트를 공개했는데, 이는 의료 영상 분석 개발에 도움이 될 것으로 기대됩니다.
의료 영상 분석의 골치 아픈 문제
의료 영상 분석은 "어려운" 주제로 알려져 있습니다.
첫째, 이는 학제간 분야입니다.실무자는 광범위한 지식 배경을 가져야 합니다. 컴퓨터 비전을 공부하는 전문가이거나 임상 의학 실무자라 할지라도, 의료 영상 분석을 향해 겨우 반 걸음만 내디딘 것에 불과합니다.
낙관적으로 보면, 수년간의 공부와 조사 끝에 마침내 컴퓨터 비전과 임상 의학의 양방향 기술을 완벽하게 터득하셨고, 다음 단계는 걱정스러울 정도로 어려울 것입니다.이러한 데이터는 X선, CT, 초음파 등 다양한 출처에서 나옵니다.다양한 패턴을 가진 수많은 비표준 데이터 세트를 분석하고 처리하는 건 정말 어렵죠!
이것이 끝이 아닙니다. 딥러닝이 의료 영상 분석 연구와 응용 분야에서 주도적인 역할을 하고 있지만, 모델 조정에 드는 인력 비용이 너무 높습니다. AutoML은 유용합니다.하지만 현재 의료 이미지 분류를 위한 AutoML 벤치마크는 사실상 전무합니다.

의료 영상 분석은 어려움이 많지만, 상하이 교통대학에서 최근 공개한 MedMNIST 데이터 세트는 이러한 오래된 문제를 해결할 수 있는 강력한 도구를 제공합니다.
10개의 공개 데이터 세트, 45만 개의 이미지 재구성
MedMNIST는 10개의 공공 의료 데이터 세트로 구성되어 있습니다.모든 데이터는 사전 처리되어 훈련 세트, 검증 세트, 테스트 하위 세트를 포함한 표준 데이터 세트로 나뉩니다. 데이터 소스에는 X선, OCT, 초음파, CT 등 다양한 영상 모드가 포함되며, 동일한 병변의 다중 모드 데이터가 획득됩니다. MNIST 데이터 세트와 마찬가지로,MedMNIST는 가벼운 28*28 이미지에 대한 분류 작업을 수행할 수 있습니다.
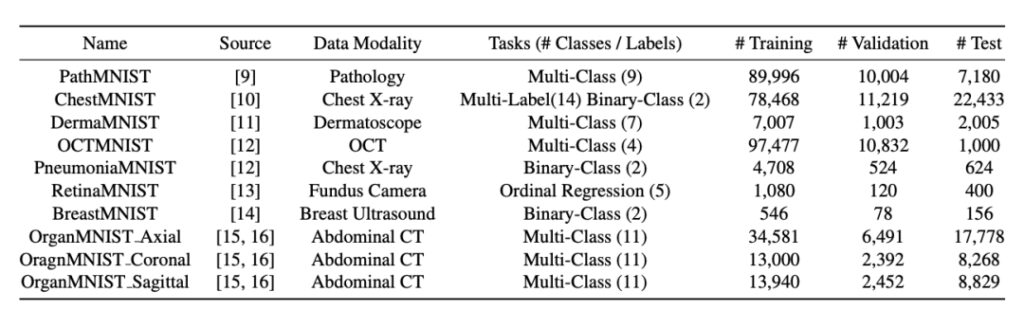
MedMNIST는 다음과 같은 특징을 가지고 있습니다.
교육적:다중 모드 데이터는 여러 공공 의료 이미지 데이터 세트에서 추출되었으며, 교육적 사용을 용이하게 하기 위해 크리에이티브 커먼즈(CC) 라이선스 또는 무료 라이선스를 사용합니다.
표준화:모든 데이터는 동일한 형식으로 사전 처리되어 진입 장벽이 낮아지고 누구나 이용할 수 있게 되었습니다.
다양성:다중 모드 데이터 세트는 다양한 데이터 모드를 포괄하고, 100에서 100,000까지의 데이터 크기를 지원하며, 이진 분류, 다변수 분류, 순서형 회귀, 다중 레이블과 같은 다양한 작업 유형을 제공합니다.
가벼움:28*28 이미지 크기는 멀티모달 머신 러닝과 AutoML 알고리즘의 빠른 프로토타입 제작, 빠른 반복 및 실험을 용이하게 합니다.
MedMNIST 데이터 세트
출판사:상하이 교통대학교
포함된 수량:454,591개의 이미지
데이터 형식:NPZ
데이터 크기:654MB
출시 시간:2020년 10월 28일
다운로드 주소:http://dwz.date/dew2
데카트론 방식은 AutoML의 새로운 벤치마크를 만들어내며 훌륭합니다.
의료 세분화 10종 경기에서 영감을 받아상하이 교통대학교의 연구원들은 의료 이미지 분류에서 가벼운 AutoML 벤치마크로 MedMNIST Classification Decathlon을 출시했습니다.
연구진은 MedMNIST 분류 10종 경기를 사용하여 10개의 모든 데이터 세트에 대한 알고리즘 성능을 평가하고 ResNets(18, 50), auto-sklearn, AutoKeras, Google AutoML Vision을 포함한 여러 다른 기준 방법과 비교했습니다.
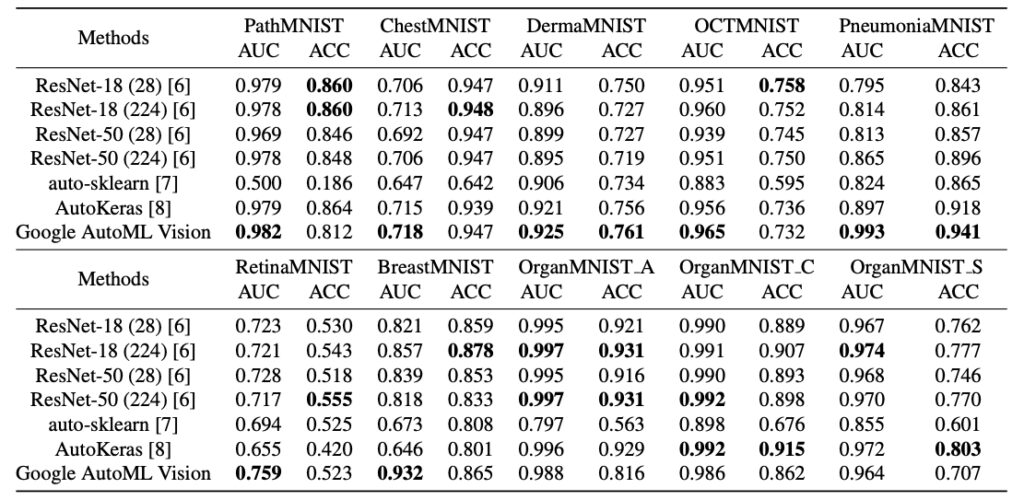
실험 결과에 따르면, 10개의 데이터 세트 모두에 대해 우수한 일반화 성능을 달성할 수 있는 실험 알고리즘은 없습니다.이 실험은 다양한 데이터 모드, 작업 유형, 데이터 규모에 걸쳐 일반화가 잘 되는 AutoML 알고리즘을 탐색하는 데 매우 중요합니다.
MedMNIST 분류 데카트론 벤치마크는 의료 이미지 분석을 위한 AutoML에 대한 미래 연구를 촉진할 것입니다.
관련 논문:
오픈소스 주소:
https://github.com/MedMNIST/MedMNIST
이제 데이터 세트를 다운로드하고 훈련을 시작하세요.
데이터 세트를 다운로드하고, 머신 러닝 모델을 온라인으로 훈련시킨 후 OpenBayes로 연습을 시작하세요.
OpenBayes는 머신 러닝을 위한 클라우드 컴퓨팅 성능을 제공하는 클라우드 서비스 플랫폼입니다. 대규모 슈퍼컴퓨팅 클러스터를 보유하고 있으며, 다양한 구성의 GPU 및 CPU 컴퓨팅 리소스를 지원하며, 바로 사용 가능한 범용 머신러닝 모델링 시스템을 갖추고 있습니다. 머신 러닝 경험 없이도 지능형 시스템을 빠르게 구축할 수 있습니다.
현재 OpenBayes의 컴퓨팅 파워 컨테이너 제품은 이미 다음을 지원합니다. CPU 및 GPU 환경에서 TensorFlow, PyTorch, MXNet, Darknet, cpp-develop 등, 다양한 버전과 유형의 표준 머신 러닝 프레임워크와 다양한 공통 종속성.
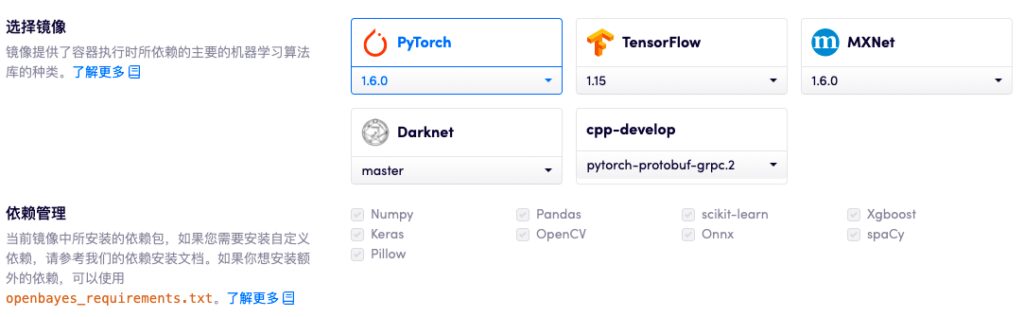
OpenBayes는 또한 다음을 제공합니다. CPU, NVIDIA T4, NVIDIA Tesla V100 및 기타 컴퓨팅 리소스방대한 데이터에 대한 중앙 집중식 학습이든 저전력 모델 상주 운영이든 사용자 요구 사항을 쉽게 충족할 수 있습니다.

MedMNIST 데이터세트는 이제 OpenBayes에서 사용할 수 있습니다.
openbayes.com을 방문하세요 초대 코드 [HyperAI]를 사용하여 새로운 사용자로 등록하세요.즐길 수 있습니다주당 CPU 240분 + NVIDIA vGPU 180분 무료 컴퓨팅 파워~
입장다음 링크또는원본 기사를 읽으려면 클릭하세요MedMNIST 탐험 여행을 시작하세요!
링크: http://dwz.date/dew2
-- 위에--