Command Palette
Search for a command to run...
약 20만 권의 도서를 포함하는 OpenAI 수준의 학습 데이터 세트가 온라인에 있습니다.

OpenAI처럼 강력한 GPT 모델을 훈련하고 싶지만, 훈련 데이터 세트가 부족해 어려움을 겪고 계신가요? 최근 Reddit 커뮤니티의 한 네티즌이 약 20만 권의 도서가 포함된 일반 텍스트 데이터 세트를 업로드했습니다. 일류 GPT 모델을 훈련하는 것은 더 이상 꿈이 아닙니다.
최근 머신러닝 커뮤니티에서 인기 있는 리소스 게시물이 나왔습니다. "GPT와 같은 대규모 언어 모델을 훈련하기 위한 196,640권의 일반 텍스트 도서 데이터 세트"이는 격렬한 토론을 불러일으켰습니다.
이 데이터 세트에는 2020년 9월 기준 모든 대규모 텍스트 코퍼스에 대한 다운로드 링크가 포함되어 있습니다. 또한 Bibliotik(온라인 도서 리소스 라이브러리)에 있는 모든 책의 일반 텍스트와 많은 양의 학습 코드가 포함되어 있습니다.
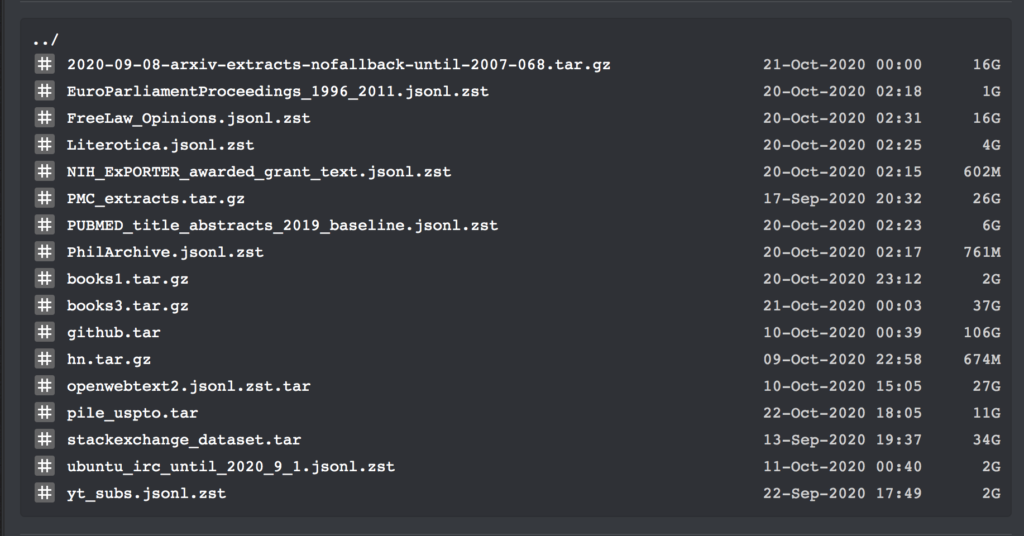
어제 네티즌 숀 프레서는 머신러닝 커뮤니티인 레딧에 일반 텍스트 데이터 세트를 공개했는데, 이는 만장일치로 칭찬을 받았습니다.
이러한 데이터 세트에는 총 196,640개의 일반 텍스트 데이터가 포함되어 있으며, GPT와 같은 대규모 언어 모델을 학습하는 데 사용할 수 있습니다.
이 데이터 세트에는 여러 개의 데이터 세트와 훈련 코드가 포함되어 있으므로 여기서는 자세한 내용을 다루지 않겠습니다. books1 및 books3 데이터 세트의 구체적인 정보만 나열하겠습니다.
책 일반 텍스트 데이터 세트
게시자: 숀 프레서
포함된 수량:books1: 1800권의 책; book3: 196640권
데이터 형식:txt 형식
데이터 크기:books1: 2.2GB; books3: 37GB
업데이트 시간:2020년 10월
다운로드 주소:https://orion.hyper.ai/datasets/13642
데이터세트 구성자 숀 프레서에 따르면, 이 데이터세트의 품질은 매우 높습니다. books1 데이터 세트에 대한 epub2txt 스크립트를 복구하는 데만 약 일주일이 걸렸습니다.
또한 그는 또한 다음과 같이 말했습니다.books3 데이터 세트는 OpenAI 논문에 나오는 신비로운 "books2" 데이터 세트와 유사한 것으로 보입니다.하지만 OpenAI가 이에 대한 자세한 정보를 제공하지 않았기 때문에 두 가지의 차이점을 이해하는 것은 불가능합니다.
하지만 그의 의견으로는 이 데이터 세트는 GPT-3의 학습 데이터 세트와 매우 유사합니다. 이를 통해 다음 단계는 GPT-3와 비슷한 수준의 NLP 언어 모델을 훈련하는 것입니다. 물론, 하나의 조건이 있습니다. 충분한 GPU도 준비해야 합니다.

서론에 따르면,books1 데이터 세트에는 1,800권의 책이 포함되어 있으며, 모두 대규모 텍스트 코퍼스인 BookCorpus에서 가져온 것입니다.여기에는 시, 소설 등이 포함됩니다.
예를 들어, 미국 작가 크리스티 린 히긴스의 "Shades of Gray: Noir, City Shrouded By Darkness", 벤저민 브로크의 "Animal Theater", T.I.의 "America One" 등이 있습니다. 걸어 건너기.
강력한 GPT-3는 교육 데이터 세트에 의해 지원됩니다.
자연어 처리 분야에 관심이 있는 친구들은 올해 5월, OpenAI가 막대한 비용을 들여 구축한 자연어 처리 모델 GPT-3가 놀라운 텍스트 생성 능력으로 업계에서 큰 주목을 받으며 지금까지 인기를 끌고 있다는 것을 알고 있을 것입니다.
GPT-3는 질문에 답하고, 번역하고, 기사를 더 잘 쓸 수 있을 뿐만 아니라, 어느 정도 수학적 계산 기능도 갖추고 있습니다. 이 기술이 이처럼 강력한 역량을 갖추고 있는 이유는 이를 뒷받침하는 방대한 교육 데이터 세트와 불가분의 관계에 있습니다.
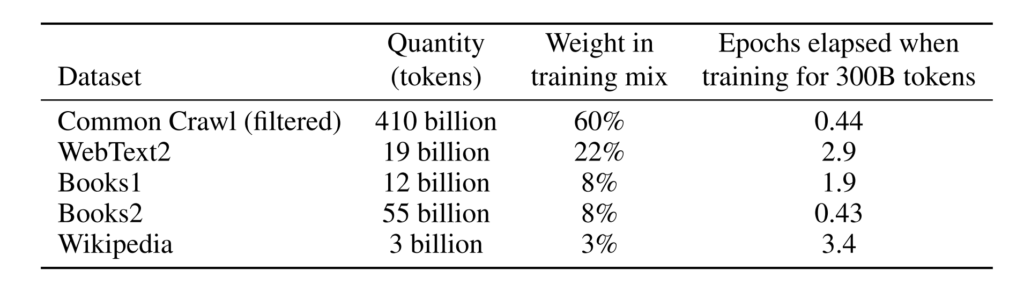
서론에 따르면,GPT-3에서 사용하는 학습 데이터 세트는 매우 큽니다. 이는 약 1조 개의 단어, 웹 텍스트, 데이터, 위키피디아 및 기타 데이터를 포함하는 CommonCrawl 데이터 세트를 기반으로 합니다. 처리하기 전에 사용하는 가장 큰 데이터 세트의 용량은 45TB입니다.훈련 비용도 무려 1,200만 달러에 달했습니다.
더 큰 교육 데이터 세트와 더 많은 모델 매개변수로 인해 GPT-3는 자연어 처리 모델에서 훨씬 앞서 나갔습니다.
하지만 일반 개발자의 경우, 일류 언어 모델을 훈련시키고 싶다면, 높은 훈련 비용은 말할 것도 없고, 데이터 세트를 훈련시키는 단계에서 멈춰 서게 될 것입니다.
따라서 숀 프레서가 가져온 데이터 세트는 의심할 여지 없이 이 문제를 해결했으며, 일부 네티즌은 이 작업을 통해 막대한 비용을 절감했다고 말했습니다.
Super Neuro는 이제 books1 데이터 세트를 다음으로 이동했습니다. https://orion.hyper.ai,"책"이나 "텍스트"라는 키워드를 검색하거나, 원본 텍스트를 클릭하여 데이터 세트를 얻으세요.
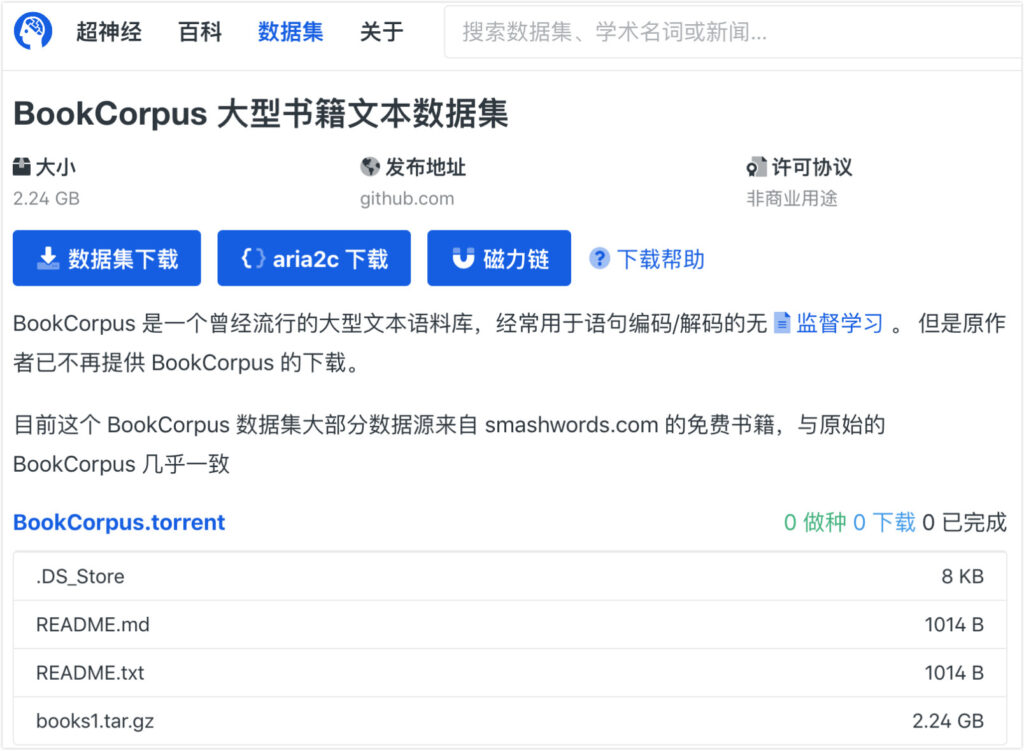
다른 데이터 세트는 다음 링크에서 얻을 수 있습니다.
books3 데이터세트 다운로드 주소:
https://the-eye.eu/public/AI/pile_preliminary_components/books3.tar.gz
훈련 코드 다운로드 주소:
https://the-eye.eu/public/AI/pile_preliminary_components/github.tar
원래 reddit 게시물:https://www.reddit.com/r/MachineLearning/comments/ji7y06/p_dataset_of_196640_books_in_plain_text_for/
-- 위에--