Command Palette
Search for a command to run...
B 스테이션의 신성한 노래 Damedane: 본질은 얼굴 바꾸기에 있습니다. 5분이면 배울 수 있습니다.

AI 얼굴변환 기술은 끊임없이 등장하고 있지만, 각 세대는 이전 세대보다 뛰어납니다. 최근 NeurIPs 2019에 발표된 AI 얼굴변환 모델의 1차 동작 모델이 주목을 받고 있으며, 그 표정 전달 효과는 같은 분야의 다른 방법보다 뛰어납니다. 최근 이 기술은 B 스테이션에 새로운 트렌드를 불러일으켰습니다.
최근 빌리빌리에서는 지나치게 '원시적인' 스타일(B 방송국 속어로 악마적으로 웃긴다는 뜻)의 영상이 잇따라 등장해 조회수가 수백만 회를 기록하며 큰 인기를 얻고 있다.
풀스킬을 갖춘 마스터를 활용하세요 「1차 운동 1차 운동 모델」AI 얼굴변환 프로젝트는 독특한 스타일을 지닌 다양한 영상을 만들어냈습니다.
예를 들어, 장성규, 두보, 당승, 그리고 팬더 머리 이모티콘은 "Damedane"과 "Unravel"을 매우 감정적으로 불렀습니다... 그림은 다음과 같습니다.


애니메이션 사진에 만족하지 못하셨다면 바로 영상으로 넘어가보세요:
지금까지 211만3000회 재생된 세뇌곡 '다메다네'의 울음고양이 버전 출처: B국 업마스터 굵은머리 후투투
솔직히 말해서, 좀 중독성이 있어요... 작은 고장난 방송국으로 가서 볼 만한 다른 작품을 찾아보세요.
이러한 영상은 수많은 네티즌의 관심을 끌어 직접 시도해보게 했고, 튜토리얼을 요청하는 메시지를 남기기도 했습니다. 다음으로, 이러한 얼굴 바꾸기 효과(모든 악의 근원)를 달성하는 기술을 살펴보겠습니다.1차 운동 모델.
Learning Garden B Station, 립싱크를 가르쳐주는 다양한 튜토리얼
지금까지 이와 유사한 얼굴변환 및 입술 동기화 기술이 끊임없이 등장해 왔으며, 매번 제안될 때마다 얼굴변환 열풍이 촉발되었습니다.
1차 동작 모델은 얼굴 특징과 입술 모양을 최적화하는 데 효과적이며, 사용하기 쉽고 구현이 효율적이기 때문에 매우 인기가 있습니다.
예를 들어, 기사의 시작 부분에 있는 "damedane"의 얼굴을 변경하려면,이를 달성하는 데는 몇 초 밖에 걸리지 않으며 5분 안에 배울 수 있습니다.
빌리빌리의 업로더 대부분은 튜토리얼을 진행하기 위해 Google Drive와 Colab을 선택합니다. 방화벽 우회의 어려움을 고려하여 업마스터 중 한 분의 튜토리얼을 선택하여 국내 머신러닝 컴퓨팅 파워 컨테이너 서비스(https://openbayes.com), 그리고 이제 매주 무료 vGPU 사용 시간을 활용해 이 튜토리얼을 쉽게 완료할 수 있습니다.
2020년 9월 30일 업데이트: 현재 bilibili는 "AI 얼굴 변환"과 관련된 모든 영상을 삭제했습니다. 따라서 OpenBayes 팀은 단계별 튜토리얼의 해당 텍스트 버전을 추가했습니다.
5분 이내에 나만의 "다메다인"을 완성할 수 있습니다.
이 튜토리얼 영상에서는 단계별로 설명하므로 초보자라도 쉽게 얼굴 바꾸기 기술을 배울 수 있습니다. 업마스터는 노트북을 플랫폼에 업로드했으며, 클릭 한 번으로 복제하여 바로 사용할 수 있습니다.
하지만 많은 기술적인 Up 호스트들은 오락 외에도 기술적인 교류를 위해 영상을 만들기 때문에 모든 사람이 악의적으로 남용하지 않기를 바란다고 말했습니다.
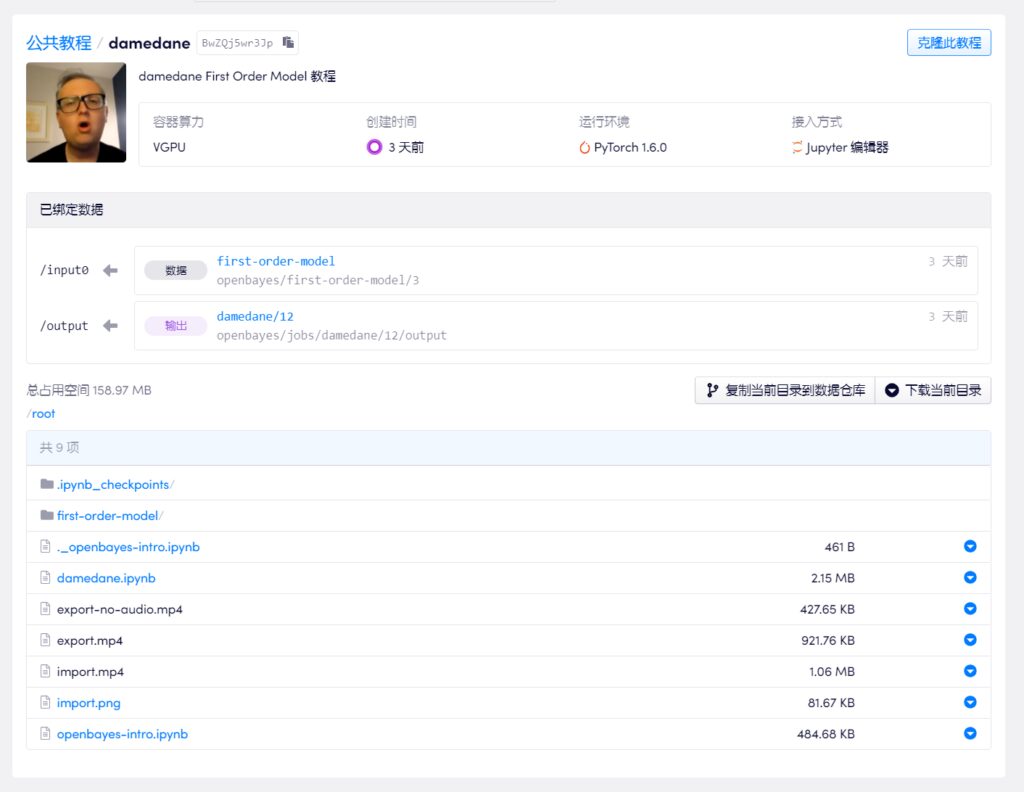
비디오 튜토리얼 주소:
https://openbayes.com/console/openbayes/containers/BwZQj5wr3Jp
원래 프로젝트 Github 주소:
https://github.com/AliaksandrSiarohin/first-order-model
얼굴을 바꾸는 또 다른 도구인데, 무슨 용도일까요?
1차 동작 모델은 최고의 컨퍼런스인 NeurlPS 2019에서 발표된 논문에서 나왔습니다.이미지 애니메이션을 위한 1차 모션 모델,저자는 이탈리아 트렌토 대학 출신입니다.

제목에서 알 수 있듯이,본 논문의 목적은 정지된 이미지를 움직이는 것으로 만드는 것이다.소스 이미지와 주행 비디오가 주어졌을 때, 소스 이미지의 이미지가 주행 비디오의 동작에 따라 움직이도록 합니다. 즉, 모든 것을 움직이게 하는 것입니다.
그 효과는 아래 그림과 같습니다. 왼쪽 상단은 주행 영상이고 나머지는 원본 정지 이미지입니다.

모델 프레임워크 구성
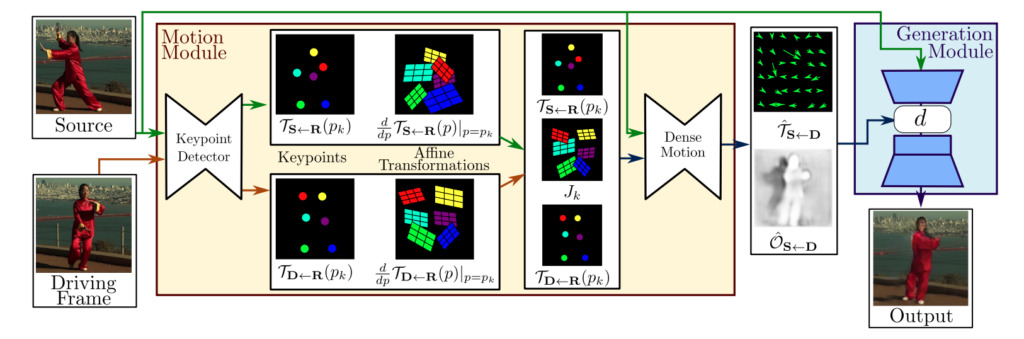
일반적으로 1차 운동 모델의 프레임워크는 두 개의 모듈로 구성됩니다.동작 추정 모듈 및 이미지 생성 모듈.
동작 추정 모듈:자기 지도 학습을 통해 대상 객체의 모양과 동작 정보를 분리하고 특징을 표현합니다.
이미지 생성 모듈:이 모델은 타겟이 움직이는 동안 발생하는 폐색을 모델링한 다음, 주어진 유명인 이미지에서 외모 정보를 추출하고 이를 이전에 얻은 특징 표현과 결합하여 비디오 합성을 수행합니다.
이 모델은 기존 모델보다 어떤 점이 더 좋은가요?
어떤 사람들은 이것이 기존의 AI 얼굴 바꾸기 방법과 어떻게 다른지 궁금해할 것입니다. 저자는 설명을 제공합니다.
이전의 얼굴 바꾸기 영상 작업에는 다음과 같은 작업이 필요했습니다.
- 일반적으로 교환할 양측의 얼굴 이미지 데이터에 대한 사전 훈련을 실시해야 합니다.
- 원본 이미지의 주요 포인트에 주석을 달고, 그에 따른 모델 학습을 진행해야 합니다.
하지만 실제로는 개인 얼굴 데이터가 적고 학습에 필요한 시간도 많지 않습니다.따라서 기존 모델은 특정 이미지에는 잘 작동하지만, 일반 대중에게 사용하면 품질을 보장하기 어렵고 실패할 가능성이 높습니다.

따라서 본 논문에서 제안하는 방법은 데이터 의존성 문제를 해결하고 생성 효율을 크게 향상시킨다. 표현과 행동 전달을 이루고 싶어합니다.오직동일한 카테고리의 이미지 데이터세트에 대해서만 학습하면 됩니다.
예를 들어, 누구의 얼굴을 바꾸든 표정 전달을 구현하고 싶다면 얼굴 데이터 세트에 대해서만 학습하면 됩니다. 태극권 동작 전이를 달성하고 싶다면 태극권 비디오 데이터 세트를 사용하여 훈련할 수 있습니다.
훈련이 완료되면, 해당 사전 훈련된 모델을 사용하여 주행 영상과 함께 소스 이미지가 움직이도록 할 수 있습니다.

저자는 자신의 방법을 이 분야에서 가장 진보된 방법인 X2Face와 Monkey-Net과 비교했습니다. 결과는 동일한 데이터 세트에서 이 방법의 모든 지표가 개선되었음을 보여주었습니다.두 얼굴 데이터 세트(VoxCeleb와 Nemo)에서도, 우리 방법은 원래 얼굴 생성을 위해 제안된 X2Face보다 상당히 우수한 성능을 보였습니다.

-- 위에--