Command Palette
Search for a command to run...
1.1T arXiv 데이터 세트: 170만 개의 논문, 당신의 다음 삶을 볼 수 있습니다
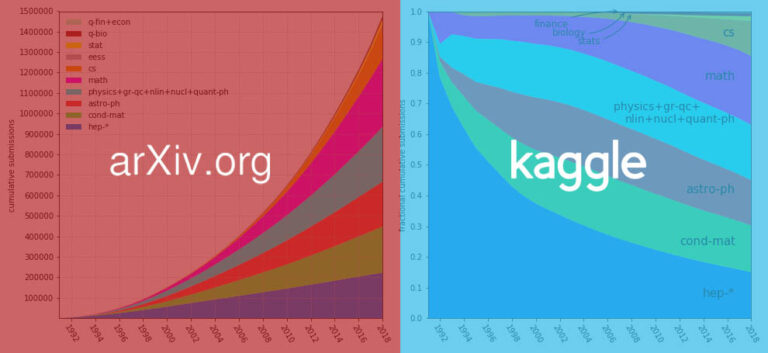
최근 arXiv는 170만 건이 넘는 논문을 데이터 세트로 패키징하여 Kaggle 플랫폼에 올렸으며, 이를 통해 향후에도 논문에 더욱 편리하게 접근하고 다운로드할 수 있게 되었습니다. 현재 데이터 세트의 크기는 약 1.1TB이며, 매주 업데이트되어 계속 증가할 예정입니다.
170만 건 이상의 학술 논문, 1.1TB 규모의 데이터 세트로, arXix가 최근 Kaggle에 공개했습니다. 이에 대해 네티즌들이 물었을 때, 그들은 "정말 멋지다!"라고 외쳤다.
데이터 세트 편집팀은 관련 연구자들이 더욱 풍부한 머신 러닝 기술을 탐구하고 더 많은 발견과 혁신을 이루도록 영감을 주기를 바란다고 밝혔습니다.
오픈 데이터 세트를 통해 논문 검색이 더 쉬워집니다.
arXiv는 약 30년 동안 대중과 연구 커뮤니티에 다양한 분야를 포괄하는 학술 논문에 대한 오픈 액세스를 제공해 왔습니다.물리학의 광범위한 분야부터 컴퓨터 과학의 여러 분야를 거쳐 수학, 통계학, 전기공학, 양적 생물학, 경제학 등 모든 학문에 이르기까지 다양합니다.
arXiv에는 많은 연구 논문이 있으며 많은 사람들이 이를 통해 이익을 얻고 있지만,하지만 탐색, 검색, 정렬이 불편하다는 단점이 있다는 보고가 많습니다.어떤 사람들은 arXiv에서 논문을 검색하는 방법에 대한 몇 가지 팁을 찾아 여러분에게 공유하기도 했습니다.
따라서 arXiv에 대한 접근성을 높이기 위해 Cornell University에서는 이제 Kaggle에서 무료로 공개된 arXiv 데이터 세트를 제공합니다.
이 데이터 세트에는 170만 건의 학술 논문과 기사 제목, 저자, 범주, 초록, 전문 PDF와 같은 논문 관련 요소(특징)가 포함되어 있습니다.
arXiv의 전무이사인 엘레오노라 프레사니는 "arXiv 코퍼스 전체를 Kaggle에 올리면 arXiv 논문의 잠재력이 크게 높아집니다. Kaggle에 데이터셋을 제공함으로써, 우리는 더 이상 사람들이 단순히 논문을 읽는 것만으로 지식을 습득하는 데 그치지 않고,더 중요한 점은 arXiv의 데이터와 정보가 기계가 읽을 수 있는 형식으로 대중에게 공개되어야 한다는 것입니다. "

프레사니는 이렇게 덧붙였습니다. "arXiv는 단순한 논문 저장소가 아니라 지식 공유 플랫폼입니다. 이를 위해서는 기존 지식을 표현하고 해석하는 방식에 혁신이 필요합니다. Kaggle 사용자들은 이러한 혁신의 한계를 뛰어넘는 데 도움을 줄 수 있으며, arXiv는 우리가 커뮤니티와 협력할 수 있는 새로운 통로가 될 것입니다."
시청하기: arXiv 데이터 세트에는 무엇이 포함되어 있나요?
arXiv 데이터 세트의 기본 정보는 다음과 같습니다.
arXiv 데이터 세트
출판사: 폴 긴스파그, 문샷 팩토리, 잭 히다리
포함된 수량:170만 건 이상의 학술 논문
데이터 형식:제이슨
데이터 크기:1.1테라바이트
출시 시간:2020년 8월
다운로드 주소:https://www.kaggle.com/Cornell-University/arxiv
현재 arXiv 데이터 세트는 다음과 같이 각 논문의 관련 항목을 포함하는 JSON 형식의 메타데이터 파일을 제공합니다.
- id: 논문 접근 주소. 논문에 접근하는 데 사용할 수 있습니다.
- 제출자: 논문 제출자;
- 저자: 논문의 저자;
- 제목: 논문 제목;
- 의견: 논문의 페이지 수, 그림 수 등의 기타 정보
- journal-ref: 논문이 출판된 저널에 대한 정보
- doi: 디지털 객체 식별자;
- 초록: 논문의 초록;
- 카테고리: arXiv에서 논문이 속하는 카테고리 또는 태그입니다.
- 버전: 종이 버전.
여러분은 방대한 양의 논문을 쉽게 탐색하고, 필터링하고, 확인할 수 있습니다.
또한, 사용자는 다음 두 링크를 통해 arXiv에서 각 논문에 직접 접근할 수 있습니다.
- https://arxiv.org/abs/{id}: 초록과 기타 링크를 포함한 논문 페이지
- https://arxiv.org/pdf/{id}: 논문 PDF 다운로드 페이지.
대량 접근도 가능합니다. 전체 PDF는 Google Cloud Storage의 gs://arxiv-dataset 버킷이나 Google API(json 문서 및 xml 문서)를 통해 무료로 제공됩니다.
종이 PDF 파일은 tarpdfs 폴더에서 여러 개의 .tar.gz 파일로 그룹화되어 있으며, 전체 데이터 세트의 크기는 약 1.1TB입니다. 자세한 내용은 다음과 같습니다(아래는 2010년 1월(1001)의 1, 2, 3번째 분야입니다):
tarpdfs/arXiv_pdf_1001_001.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_001.tar.gz)tarpdfs/arXiv_pdf_1001_002.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_002.tar.gz)tarpdfs/arXiv_pdf_1001_003.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_003.tar.gz)
사용자는 gsutil과 같은 도구를 사용하여 로컬 머신에 데이터를 다운로드할 수도 있습니다.

하지만 이 데이터 세트의 구체적인 사용 시나리오는 무엇일까요? 많은 네티즌들은 이미 주제 모델링과 데이터를 활용한 GPT-3 훈련 등의 아이디어를 가지고 있습니다.
arXiv: 학술 논문의 거대한 저장소
과학 연구 및 학술 분야에 종사하는 학생들은 arXiv에 대해 잘 알고 있어야 합니다.
물리학, 수학, 컴퓨터 과학, 생물학 분야의 논문 사전 인쇄본을 수집하는 웹사이트입니다. 이는 과학 연구자들이 "아이디어를 저장"할 수 있는 플랫폼을 제공할 뿐만 아니라, 모든 사람이 논문을 검색하고 읽을 수 있는 거대한 자료 도서관 역할도 합니다.
2008년 10월 현재 arXiv.org는 50만 개가 넘는 사전 인쇄물을 수집했습니다. 2014년 말에는 컬렉션이 100만 개에 도달했습니다.2016년 10월 현재 arXiv에 제출되는 논문은 한 달에 10,000건을 넘었습니다.
arXiv는 1991년 물리학자 폴 긴스백이 처음 설립했습니다. 원래는 물리학 논문의 사전 인쇄본을 수집하는 것이 목적이었으나, 나중에 천문학과 수학 등 다른 분야로 확장되었습니다.
arXiv는 원래 로스앨러모스 국립연구소(LANL)에서 호스팅되었기 때문에 초창기에는 "LANL 사전 인쇄 데이터베이스"라고 불렸습니다. 현재 arXiv는 코넬 대학에 본사를 두고 있으며 전 세계에 미러 사이트를 두고 있습니다. 이 사이트는 1999년에 arXiv.org로 이름이 바뀌었습니다.
쉽게 말해서 arXiv는 "자리를 예약"하는 데 사용되는 웹사이트입니다. 연구자들은 논문에 포함되기 전에 다른 사람이 자신의 아이디어를 표절하는 것을 방지하기 위해 arXiv에 초안을 게시하여 독창성을 입증합니다.
참고문헌:
https://www.kaggle.com/Cornell-University/arxiv?select=arxiv-metadata-oai-snapshot.json
https://zh.wikipedia.org/wiki/ArXiv
-- 위에--