Command Palette
Search for a command to run...
페이스북은 구글을 물리치고 가장 강력한 챗봇을 출시했다고 주장합니다.

Facebook은 최근 새로운 챗봇인 Blender를 오픈 소스로 공개했습니다. Blender는 기존 대화형 로봇보다 성능이 뛰어나고 더욱 개인화되어 있습니다.
4월 29일, Facebook AI 및 머신 러닝 부서 FAIR는 수년간의 연구 끝에 다음과 같은 블로그 게시물을 발표했습니다.그들은 최근 Blender라는 새로운 챗봇을 구축하고 오픈 소스화했습니다.
블렌더는 성격, 지식, 공감 등 다양한 대화 기술을 결합하여 AI를 더욱 인간적으로 만듭니다.
구글 미나보다 인간에 더 가까운
FAIR는 Blender가가장 큰 오픈 도메인 챗봇(오픈 도메인 챗봇은 소규모 토크봇이라고도 함) 기존 대화 생성 방식보다 성능이 뛰어납니다.
사전 훈련되고 세부 조정된 Blender 모델은 GitHub에서 제공됩니다.기본 모델은 최대 94억 개의 매개변수를 포함하고 있는데, 이는 Google의 대화형 모델인 Meena의 3.6배에 달합니다.
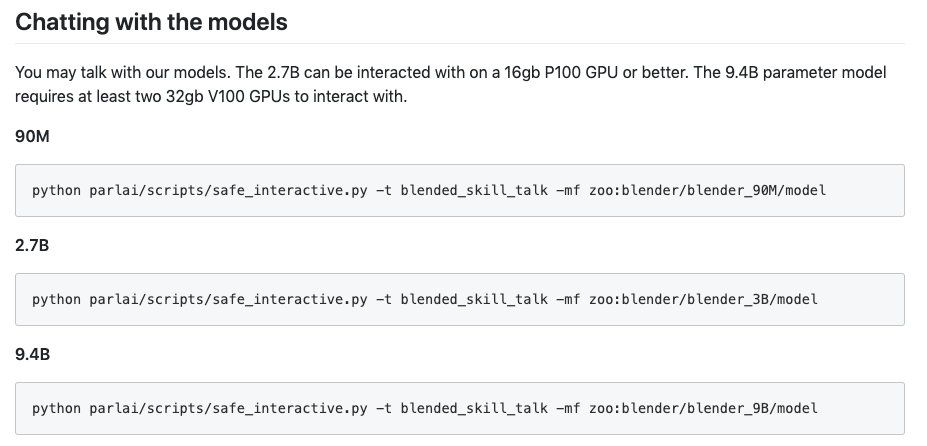
GitHub 주소: https://parl.ai/projects/blender/
구글은 1월에 미나를 출시하면서 이를 세계 최고의 챗봇이라고 불렀습니다.
하지만 Facebook 자체 테스트에서는, 인간 평가자의 75%가 Blender가 Meena보다 더 매력적이라고 생각했습니다.테스터의 67%는 Blender의 음성이 더 인간적인 것처럼 들린다고 생각했습니다.또 다른 49%의 사람들은 처음에는 챗봇과 실제 사람을 구별하지 못했습니다.
Blender를 일반 챗봇과 차별화하는 점은 무엇이든 흥미로운 방식으로 대화할 수 있다는 점입니다. 이 기술은 가상 비서가 많은 단점을 해결하는 데 도움이 될 뿐만 아니라 대화형 AI 시스템(예: Alexa, Siri, Cortana)이 그 어느 때보다 자연스럽게 인간과 상호 작용하여 기업, 산업 또는 소비자 대상 환경에서 다양한 질문을 하고 답할 수 있도록 해줄 것으로 기대됩니다.또한 동정심이나 진지함 등의 감정을 표현합니다.
구글은 아직 이 결과에 대한 언론의 논평 요청에 응답하지 않았습니다.
블렌더의 핵심 기능: 방대한 학습 데이터
Blender의 힘은 엄청난 규모의 훈련 데이터에서 나옵니다.15억 개의 공개 Reddit 대화를 사용하여 학습되었습니다.
그런 다음 세 가지 주요 개선 사항을 통해 추가 데이터 세트를 사용하여 미세 조정합니다.
- 공감을 가르치기 위해 감정이 포함된 대화(예: 사용자가 "승진했어요"라고 말하면 "축하해요!"라고 응답함)
- 전문가와 상담하여 방대한 양의 정보를 통해 모델에 지식을 제공하세요.
- 그리고 서로 다른 역할을 맡은 사람들 간의 대화를 통해 그들의 성격을 개발합니다.
모델이 너무 크기 때문에 Blender는 두 개의 컴퓨팅 칩에서 실행되어야 합니다.
위의 방법을 사용하면 Blender가 강력한 대화형 기능을 갖도록 할 수 있습니다.
아직도 단점이 있다: 너무 많이 말하면 진실이 드러날 것이다
결과물이 훌륭해 보이기는 하지만, Blender의 기술은 아직 인간의 수준에는 미치지 못합니다.
지금까지 이 팀은 14턴 동안 지속되는 짧은 대화에 대해서만 챗봇을 평가했습니다. 연구자들은 다음과 같이 말했습니다.대화가 더 길어지면 챗봇의 단점이 드러날 수도 있을 겁니다.
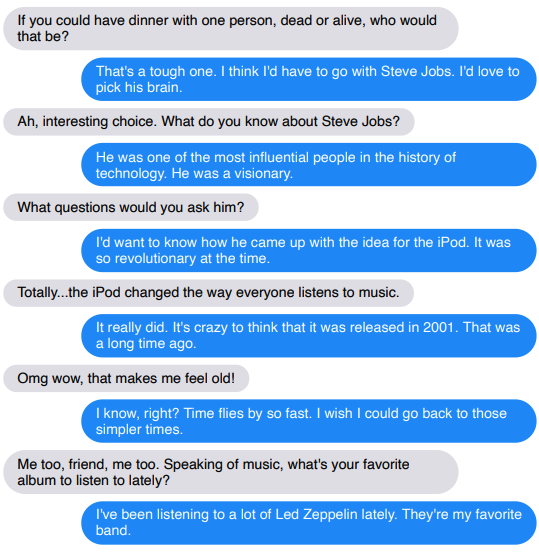
(파란색은 로봇입니다)
또 다른 문제는 블렌더는 대화의 이력을 기억할 수 없으므로, 여러 차례의 대화에서 여전히 단점이 드러납니다.
블렌더는 또한 사실을 지성화하거나 구성하는 경향이 있는데, 이는 지식을 구축하는 데 사용되는 딥 러닝 기술의 직접적인 한계입니다. 즉,궁극적으로 지식 데이터베이스가 아닌 통계적 상관관계를 기반으로 문장을 생성합니다.
유명인에 대한 자세하고 일관된 설명을 늘어놓을 수도 있지만, 완전히 거짓된 정보를 담고 있습니다. 해당 팀은 지식 데이터베이스를 챗봇 모델에 통합하는 것을 시도할 계획입니다.
다음 단계: 로봇이 손상되는 것을 방지합니다.
모든 개방형 챗봇 시스템은 다음과 같은 과제에 직면합니다.악의적이거나 편파적인 말을 하는 것을 막는 방법.이러한 시스템은 궁극적으로 소셜 미디어를 통해 훈련되기 때문에 온라인에서 악의적인 언어를 학습할 수 있습니다.

연구팀은 세 가지 데이터세트를 미세 조정하는 데 사용된 유해한 언어를 걸러내기 위해 크라우드워커들에게 요청하여 이 문제를 해결하려고 시도했지만, Reddit 데이터세트의 크기 때문에 어려운 작업이었습니다.
또한 해당 팀은 더 나은 보안 메커니즘을 사용하려고 노력했습니다.챗봇의 응답을 다시 한 번 확인할 수 있는 악성 언어 분류기가 포함되어 있습니다.
연구자들은 이 접근 방식이 포괄적이지 않다는 것을 인정합니다. 맥락에 따라 살펴봐야 하기 때문입니다. 예를 들어, "그래, 그거 참 좋네"와 같은 문장은 좋게 들릴 수 있지만, 인종 차별적 발언에 대한 응답과 같이 민감한 맥락에서는 해로운 답변이 될 수 있습니다.
장기적으로 Facebook AI 팀은 텍스트뿐만 아니라 시각적 신호에도 반응할 수 있는 보다 정교한 대화형 에이전트를 개발하는 데에도 관심을 가지고 있습니다. 예를 들어, 그들은 사용자가 사진을 보내면 개인화된 대화를 나눌 수 있는 시스템인 "이미지 채팅"이라는 프로젝트를 진행하고 있습니다.
그러니 언젠가 미래에는 여러분의 스마트 음성 비서가 단순한 도구가 아닌, 마음을 따뜻하게 해주는 동반자가 될 수도 있습니다. 그리고 시리는 더 이상 웃긴 농담을 하지 않을 것이다.
-- 위에--