Command Palette
Search for a command to run...
PyTorch 1.5 출시, AWS와 협력하여 TorchServe 출시

최근 PyTorch가 1.5 버전으로 업데이트를 출시했습니다. 점점 더 인기를 얻고 있는 머신 러닝 프레임워크인 PyTorch도 이번에 주요 기능 업그레이드를 적용했습니다. 또한 Facebook과 AWS는 두 개의 중요한 PyTorch 라이브러리를 출시하기 위해 협력했습니다.
PyTorch가 프로덕션 환경에서 점점 더 많이 사용됨에 따라, 커뮤니티에 효율적으로 학습을 확장하고 모델을 배포할 수 있는 더 나은 도구와 플랫폼을 제공하는 것이 PyTorch의 최우선 과제가 되었습니다.
최근 PyTorch 1.5가 출시되었습니다.주요 torchvision, torchtext, torchaudio 라이브러리가 업그레이드되었고, Python API에서 C++ API로 모델을 변환하는 기능이 도입되었습니다.

게다가,Facebook은 또한 Amazon과 협력하여 TorchServe 모델 제공 프레임워크와 TorchElastic Kubernetes 컨트롤러라는 두 가지 주요 도구를 출시했습니다.
TorchServe는 PyTorch 모델 추론의 대규모 배포를 위한 깔끔하고 호환 가능한 산업용 경로를 제공하는 것을 목표로 합니다.
TorchElastic Kubernetes 컨트롤러를 사용하면 개발자가 Kubernetes 클러스터를 사용하여 PyTorch에서 내결함성 분산 학습 작업을 빠르게 생성할 수 있습니다.
이는 Facebook과 Amazon이 대규모 성능 AI 모델 프레임워크에서 TensorFlow에 전쟁을 선포하려는 움직임으로 보입니다.
TorchServe: 추론 작업용
대규모 추론을 위해 머신 러닝 모델을 배포하는 것은 쉽지 않습니다. 개발자는 모델 아티팩트를 수집하고 패키징하고, 안전한 서비스 제공 스택을 생성하고, 예측을 위한 소프트웨어 라이브러리를 설치 및 구성하고, API와 엔드포인트를 생성 및 사용하고, 모니터링을 위한 로그와 메트릭을 생성하고, 잠재적으로 여러 서버에 걸쳐 여러 모델 버전을 관리해야 합니다.
이러한 각 작업에는 상당한 시간이 소요되며 모델 배포가 몇 주 또는 몇 달까지 지연될 수 있습니다. 또한, 저지연 온라인 애플리케이션에 대한 서비스를 최적화하는 것도 필수입니다.
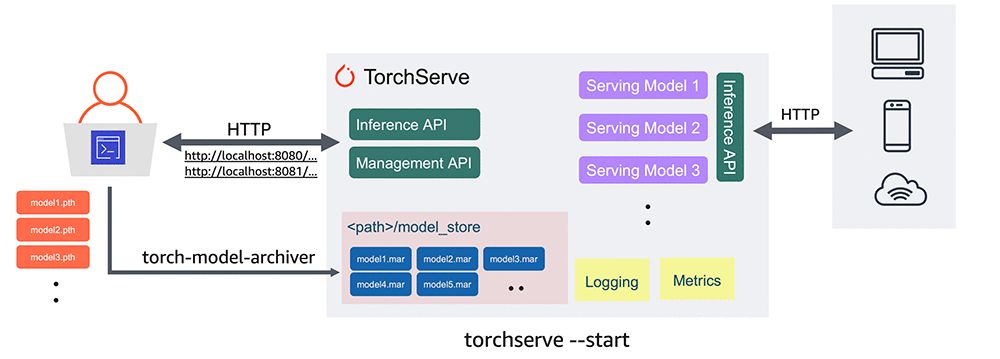
이전에는 PyTorch를 사용하는 개발자에게 PyTorch 모델을 배포하기 위한 공식적으로 지원되는 방법이 없었습니다. 프로덕션 모델 서비스 프레임워크인 TorchServe가 출시되면서 이러한 상황이 바뀌어 모델을 프로덕션에 적용하기가 더 쉬워질 것입니다.
다음 예에서는 Torchvision에서 학습된 모델을 추출하고 TorchServe를 사용하여 배포하는 방법을 보여드리겠습니다.
#Download a trained PyTorch modelwget https://download.pytorch.org/models/densenet161-8d451a50.pth#Package model for TorchServe and create model archive .mar filetorch-model-archiver \--model-name densenet161 \--version 1.0 \--model-file examples/image_classifier/densenet_161/model.py \--serialized-file densenet161–8d451a50.pth \--extra-files examples/image_classifier/index_to_name.json \--handler image_classifiermkdir model_storemv densenet161.mar model_store/#Start TorchServe model server and register DenseNet161 modeltorchserve — start — model-store model_store — models densenet161=densenet161.mar
TorchServe 베타 버전이 출시되었습니다.특징은 다음과 같습니다.
- 네이티브 API: 예측을 위한 추론 API와 모델 서버를 관리하기 위한 관리 API를 지원합니다.
- 안전한 배포: 보안 배포를 위한 HTTPS 지원이 포함되어 있습니다.
- 강력한 모델 관리 기능: 명령줄 인터페이스, 구성 파일 또는 런타임 API를 통해 모델, 버전 및 개별 작업자를 완전히 구성할 수 있습니다.
- 모델 아카이브: 모델, 매개변수 및 지원 파일을 단일 영구 아티팩트로 패키징하는 프로세스인 "모델 보관"을 수행하기 위한 도구를 제공합니다. 간단한 명령줄 인터페이스를 사용하면 PyTorch 모델을 제공하는 데 필요한 모든 것을 포함하는 단일 ".mar" 파일을 패키징하여 내보낼 수 있습니다. .mar 파일은 공유하고 재사용할 수 있습니다.
- 내장된 모델 핸들러: 이미지 분류, 객체 감지, 텍스트 분류, 이미지 분할 등 가장 일반적인 사용 사례를 포괄하는 모델 핸들러를 지원합니다. TorchServe는 사용자 정의 핸들러도 지원합니다.
- 로깅 및 메트릭: 추론 서비스와 엔드포인트, 성능, 리소스 활용도, 오류를 모니터링하기 위한 강력한 로깅 및 실시간 메트릭을 지원합니다. 사용자 정의 로그를 생성하고 사용자 정의 메트릭을 정의하는 것도 가능합니다.
- 모델 관리: 여러 모델 또는 동일 모델의 여러 버전을 동시에 관리할 수 있습니다. 모델 버전 관리를 사용하면 이전 버전으로 롤백하거나 A/B 테스트를 위해 트래픽을 다른 버전으로 라우팅할 수 있습니다.
- 미리 작성된 이미지: 준비가 되면 CPU 기반 및 NVIDIA GPU 기반 환경에 T orchServe의 Dockerfile과 Docker 이미지를 배포할 수 있습니다. 최신 Dockerfiles와 이미지는 여기에서 찾을 수 있습니다.
설치 지침, 튜토리얼, 문서는 pytorch.org/serve에서도 제공됩니다.
TorchElastic: 통합 K8S 컨트롤러
RoBERTa, TuringNLG와 같이 현재의 머신 러닝 학습 모델이 점점 더 커짐에 따라, 이를 분산 클러스터로 확장해야 할 필요성이 점점 더 중요해지고 있습니다. 이러한 요구 사항을 충족하기 위해 선점형 인스턴스(예: Amazon EC2 Spot 인스턴스)가 자주 사용됩니다.
하지만 이러한 선제적 인스턴스 자체는 예측할 수 없으므로 두 번째 도구인 TorchElastic이 필요합니다.
Kubernetes와 TorchElastic을 통합하면 PyTorch 개발자는 컴퓨팅 노드 클러스터에서 머신 러닝 모델을 훈련할 수 있습니다.이러한 노드는 모델 학습 과정을 방해하지 않고 동적으로 변경될 수 있습니다.
노드에 장애가 발생하더라도 TorchElastic의 내장된 장애 허용 기능을 통해 노드 수준에서 학습을 일시 중지하고 노드가 다시 정상화되면 학습을 재개할 수 있습니다.
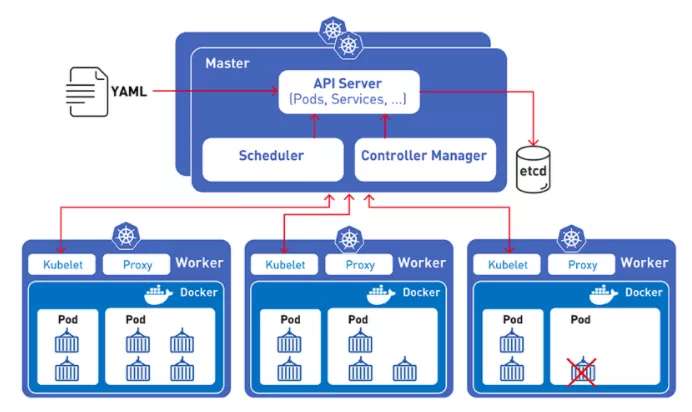
또한 TorchElastic과 함께 Kubernetes 컨트롤러를 사용하면 하드웨어 또는 노드 재활용 문제가 발생하는 경우 교체된 노드가 있는 클러스터에서 분산 학습의 중요한 작업을 실행할 수 있습니다.
훈련 작업은 요청된 리소스의 일부를 사용하여 시작할 수 있으며, 중지하거나 다시 시작할 필요 없이 리소스가 사용 가능해짐에 따라 동적으로 확장할 수 있습니다.
이러한 기능을 활용하려면 사용자는 간단한 작업 정의에서 교육 매개변수를 지정하기만 하면 되며 Kubernetes-TorchElastic 패키지가 작업의 수명 주기를 관리합니다.
다음은 Imagenet 학습 작업을 위한 TorchElastic 구성의 간단한 예입니다.
apiVersion: elastic.pytorch.org/v1alpha1kind: ElasticJobmetadata:name: imagenetnamespace: elastic-jobspec:rdzvEndpoint: $ETCD_SERVER_ENDPOINTminReplicas: 1maxReplicas: 2replicaSpecs:Worker:replicas: 2restartPolicy: ExitCodetemplate:apiVersion: v1kind: Podspec:containers:- name: elasticjob-workerimage: torchelastic/examples:0.2.0rc1imagePullPolicy: Alwaysargs:- "--nproc_per_node=1"- "/workspace/examples/imagenet/main.py"- "--arch=resnet18"- "--epochs=20"- "--batch-size=32"
마이크로소프트와 구글, 당황하고 있나요?
두 회사가 새로운 PyTorch 라이브러리를 출시하기 위해 협력한 것은 더 깊은 의미를 가질 수 있는데, "놀지 마" 루틴은 프레임워크 모델 개발 역사상 처음 등장하는 것이 아니기 때문이다.
2017년 12월, AWS, Facebook, Microsoft는 프로덕션 환경을 위한 ONNX를 공동으로 개발할 것이라고 발표했습니다.이는 산업용으로의 구글 텐서플로우 독점에 대응하기 위한 것입니다.
이후 Apache MXNet, Caffe2, PyTorch와 같은 주류 딥러닝 프레임워크는 모두 ONNX에 대한 다양한 수준의 지원을 구현했으며, 이를 통해 서로 다른 프레임워크 간의 알고리즘과 모델 마이그레이션이 용이해졌습니다.

하지만 ONNX가 제시한 학계와 산업계의 연결이라는 비전은 실제로는 원래 기대에 부응하지 못했습니다. 각 프레임워크는 여전히 자체 서비스 시스템을 사용하고 있으며, 기본적으로 MXNet과 PyTorch만이 ONNX에 침투했습니다.
그리고 지금,PyTorch는 자체 서비스 시스템을 출시했고 ONNX는 존재의 의미를 거의 잃었습니다(MXNet은 당황했다고 말했습니다).
반면, PyTorch는 지속적으로 업그레이드 및 업데이트되고 있으며, 프레임워크의 호환성과 사용 편의성이 향상되고 있습니다.가장 강력한 경쟁자인 텐서플로우에 근접하고 있으며, 심지어 이를 능가하고 있습니다.
구글은 자체 클라우드 서비스와 프레임워크를 보유하고 있지만, AWS의 클라우드 리소스와 페이스북의 프레임워크 시스템이 결합되면 구글이 이 강력한 조합에 대처하기 어려울 것으로 보인다.
Microsoft는 ONNX의 전 3인조 중 두 명에 의해 그룹 채팅에서 쫓겨났습니다. Microsoft의 다음 단계는 무엇입니까?
-- 위에--