Command Palette
Search for a command to run...
이 엔지니어 그룹은 여가 시간에 중국어 NLP를 큰 진전으로 이끌었습니다.

누군가는 NLP(자연어 처리)를 공부했다면 중국어 NLP가 얼마나 어려운지 알 것이라고 말했습니다.
영어와 중국어는 둘 다 NLP에 속하지만, 언어 습관의 차이로 인해 분석 및 처리 방식에 큰 차이가 있으며, 어려움과 과제도 다릅니다.

게다가 현재 인기 있는 모델 중 일부는 주로 영어로 개발되었습니다. 중국어의 독특한 사용 습관과 더불어 단어 분할과 같은 많은 작업이 매우 어려워서 중국어 NLP 분야의 발전이 매우 느립니다.
하지만 이런 문제는 곧 바뀔 수도 있습니다. 작년부터 우수한 오픈소스 프로젝트가 많이 등장해서 NLP 중국 분야의 발전에 큰 도움이 되었기 때문입니다.
모델: 중국어 사전 훈련된 ALBERT
2018년에 구글은 Transformers의 양방향 인코더 표현인 언어 모델 BERT를 출시했습니다. 매우 강력한 성능 덕분에 출시되자마자 많은 NLP 표준 차트를 휩쓸었고 곧바로 걸작이라는 찬사를 받았습니다.
하지만 BERT의 한 가지 단점은 크기가 너무 크다는 것입니다. BERT-large는 매개변수가 3억 개나 되어서 학습이 매우 어렵습니다. 2019년에 구글 AI는 경량 ALBERT(A Little BERT)를 출시했습니다. 이는 BERT 모델보다 매개변수가 18배 작지만 성능은 더 뛰어납니다.
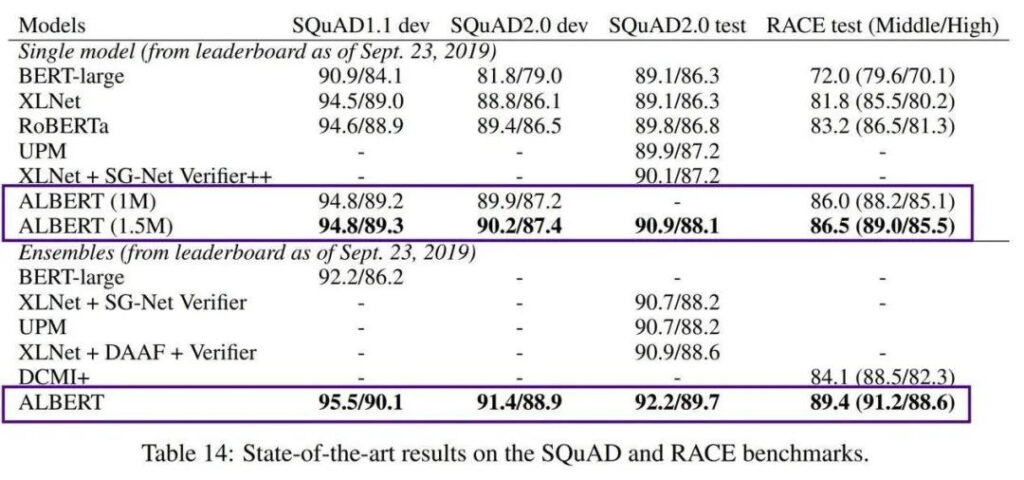
AlBERT는 사전 학습된 모델의 높은 학습 비용과 엄청난 수의 매개변수 문제를 해결했지만, 여전히 영어 맥락에만 초점을 맞추고 있어 중국어 개발에 집중하는 엔지니어들은 약간 무력감을 느낍니다.
이 모델을 중국 환경에서 활용하고 더 많은 개발자에게 혜택을 주기 위해 데이터 엔지니어 쉬량(Xu Liang) 팀은 2019년 10월에 최초의 중국식 사전 학습 ALBERT 모델을 공개했습니다.
프로젝트 갤러리
https://github.com/brightmart/albert_zh
이 중국어 사전 학습된 ALBERT 모델(albert_zh로 표기)은 방대한 중국어 코퍼스를 기반으로 학습되었습니다. 교육 콘텐츠는 30G의 중국어 자료와 1,000억 개가 넘는 한자를 포함한 다양한 백과사전, 뉴스, 대화형 커뮤니티에서 제공됩니다.
데이터 비교를 통해 albert_zh의 사전 학습 시퀀스 길이는 512로 설정되고, 배치 크기는 4096이며, 학습을 통해 3억 5천만 개의 학습 데이터가 생성됩니다. 또 다른 강력한 사전 학습 모델인 roberta_zh는 256의 시퀀스 길이를 가진 2억 5천만 개의 학습 데이터를 생성합니다.
albert_zh 사전 학습은 더 많은 학습 데이터를 생성하고 더 긴 시퀀스를 사용합니다. albert_zh는 roberta_zh보다 성능이 더 뛰어나고 긴 텍스트를 더 잘 처리할 수 있을 것으로 기대됩니다.
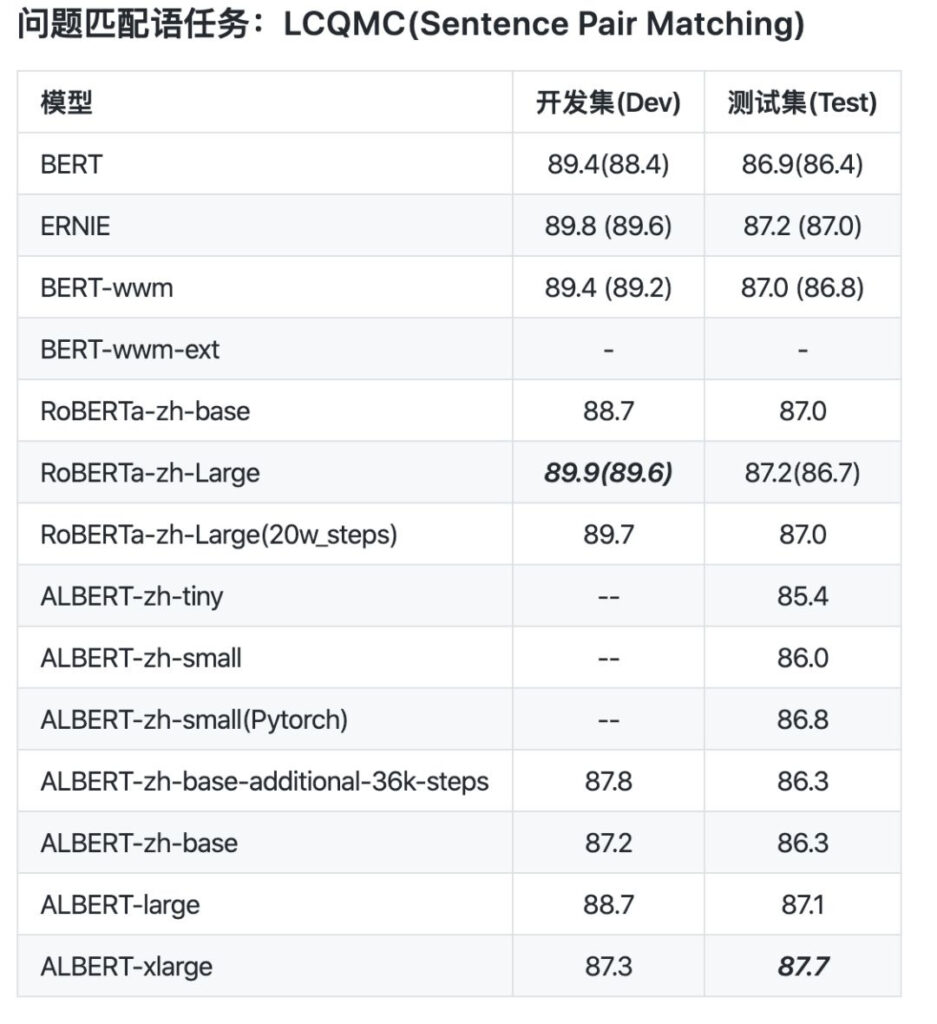
또한 albert_zh는 tiny에서 xlarge까지 다양한 매개변수 크기를 갖는 일련의 ALBERT 모델을 학습시켰으며, 이를 통해 중국어 NLP 분야에서 ALBERT의 인기가 크게 높아졌습니다.
2020년 1월에 Google AI가 ALBERT V2를 출시한 후, Google 중국어 버전의 ALBERT를 천천히 출시했다는 점은 언급할 가치가 있습니다.
벤치마크: Chinese GLUE를 위한 ChineseGLUE
일단 모델이 만들어지면, 그 모델이 좋은지 나쁜지 어떻게 판단할 수 있을까? 이를 위해서는 충분히 좋은 테스트 벤치마크가 필요합니다. 또한 작년에는 중국어 NLP를 위한 벤치마크인 ChineseGLUE가 오픈 소스로 공개되었습니다.
ChineseGLUE는 9가지 영어 이해 과제로 구성된 업계에서 유명한 테스트 벤치마크 GLUE를 기반으로 합니다. 이 연구의 목적은 일반적이고 견고한 자연어 이해 시스템 연구를 촉진하는 것입니다.
이전에는 GLUE에 해당하는 중국어 버전이 없었고, 일부 사전 학습된 모델은 다양한 작업에 대한 공개 테스트에서 평가될 수 없었으며, 이로 인해 중국 분야에서 NLP 개발 및 적용에 불일치가 발생했고 심지어 기술적 적용이 지연되기도 했습니다.
이러한 상황에 직면하여 AlBERT의 첫 번째 저자인 Zhenzhong Lan 박사, ablbert_zh의 개발자인 Xu Liang을 비롯한 20명 이상의 엔지니어가 공동으로 중국어 NLP의 벤치마크인 ChineseGLUE를 출시했습니다.
프로젝트 갤러리
https://github.com/chineseGLUE/chineseGLUE
ChineseGLUE의 등장으로 중국어를 새로운 모델을 평가하는 지표로 포함할 수 있게 되었고, 중국어 사전 학습 모델을 테스트하기 위한 완전한 평가 시스템이 형성되었습니다.
이 강력한 테스트 벤치마크에는 다음과 같은 측면이 포함됩니다.
1) 여러 문장 또는 문장 쌍으로 구성된 중국어 과제 벤치마크로, 다양한 수준의 여러 언어 과제를 포괄합니다.
2) 모델 선택의 기준을 제공하기 위해 정기적으로 업데이트되는 성과 평가 순위 목록을 제공합니다.
3) TensorFlow, PyTorch, Keras와 같은 프레임워크에서 사용할 수 있는 ChineseGLUE 작업을 위한 시작 코드, 사전 학습된 모델, 벤치마크를 포함한 벤치마크 모델 컬렉션입니다.
4) 사전 학습이나 언어 모델링 연구를 위한 거대한 원본 코퍼스를 보유하고 있는데, 이는 약 10G(2019년)이며, 2020년 말까지 충분한 원본 코퍼스(예: 100G)로 확장할 계획입니다.
ChineseGLUE의 출시와 지속적인 개선을 통해 더욱 강력한 중국어 NLP 모델이 탄생할 것으로 기대되는데, 이는 GLUE가 BERT의 등장을 목격했던 것과 마찬가지입니다.
2019년 12월 말에 이 프로젝트는 보다 포괄적이고 기술적으로 더 지원되는 CLUEbenchmark/CLUE 프로젝트로 이전되었습니다.
프로젝트 갤러리
https://github.com/CLUEbenchmark/CLUE
데이터: 역사상 가장 완벽한 데이터 세트이자 가장 큰 규모의 코퍼스
사전 학습된 모델과 테스트 벤치마크를 통해 데이터 세트와 코퍼스와 같은 데이터 리소스도 중요한 연결 고리가 됩니다.
이로 인해 더욱 포괄적인 조직인 CLUE가 탄생했는데, 이는 중국어 GLUE의 약자입니다. 중국어 이해에 대한 평가 벤치마크를 제공하는 오픈소스 조직입니다. 이들의 주요 관심 분야는 다음과 같습니다. 작업 및 데이터 세트, 벤치마크, 사전 학습된 중국어 모델, 코퍼스 및 순위 발표.
얼마 전 CLUE는 10개 카테고리의 142개 데이터 세트를 포함하는 가장 크고 포괄적인 중국어 NLP 데이터 세트인 CLUEDatasetSearch를 출시했습니다.

프로젝트 갤러리
https://github.com/CLUEbenchmark/CLUEDatasetSearch
그 내용에는 NER, QA, 감성 분석, 텍스트 분류, 텍스트 할당, 텍스트 요약, 기계 번역, 지식 그래프, 코퍼스, 독해 이해 등 현재 진행 중인 주요 연구 방향이 모두 포함되어 있습니다.
웹사이트 페이지에 키워드나 관련 분야 등의 정보만 입력하면, 해당 리소스를 검색할 수 있습니다. 각 데이터 세트는 이름, 업데이트 시간, 제공자, 설명, 키워드, 범주, 논문 주소와 같은 정보를 제공합니다.
최근 CLUE 조직은 100GB 규모의 중국어 코퍼스와 고품질의 중국어 사전 학습 모델 컬렉션을 공개하고 arViv에 논문을 제출했습니다.

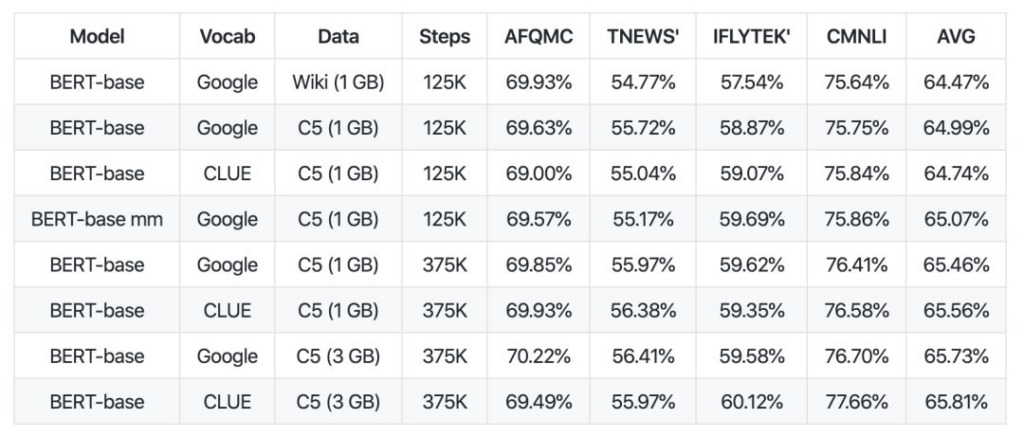
코퍼스 측면에서 CLUE는 100G 규모의 중국어 사전 학습 코퍼스인 CLUECorpus2020을 오픈 소스로 공개했습니다.
이러한 내용은 Common Crawl 데이터 세트의 중국어 부분에 대한 코퍼스 정리를 거친 후 얻어졌습니다.
사전 학습, 언어 모델 또는 언어 생성 작업에 직접 사용하거나, 중국어 NLP 작업에 특화된 소규모 어휘집을 게시할 수도 있습니다.
프로젝트 갤러리
https://github.com/CLUEbenchmark/CLUECorpus2020
모델 컬렉션 측면에서 CLUEPretrainedModels가 출시되었습니다. 이는 가장 진보된 대형 모델, 가장 빠른 소형 모델, 유사성별 모델 등 고품질의 중국식 사전 학습 모델 컬렉션입니다.
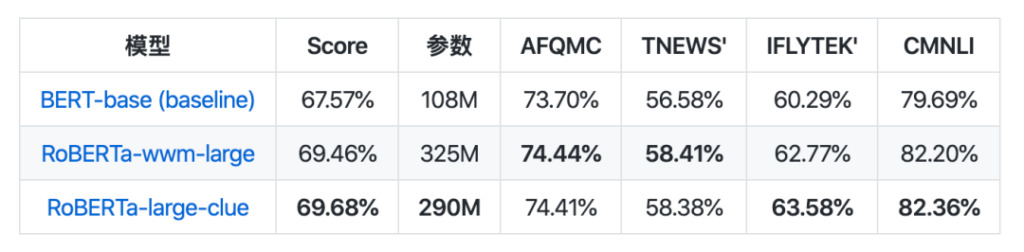
대규모 모델은 현재 가장 우수한 중국어 NLP 모델과 동일한 결과를 달성했으며, 일부 작업에서는 더 우수한 성과를 보였습니다. 작은 모델은 Bert-base보다 약 8배 빠릅니다. 의미적 유사성 모델은 의미적 유사성이나 문장 쌍 문제를 처리하는 데 사용되며, 사전 학습된 모델을 직접 사용하는 것보다 더 나을 가능성이 높습니다.
프로젝트 갤러리
https://github.com/CLUEbenchmark/CLUEPretrainedModels
이러한 리소스의 출시는 어느 정도 개발 과정을 촉진하는 연료와 같으며, 충분한 리소스가 제공되면 중국 NLP 산업의 급속한 발전으로 가는 길이 열릴 수도 있습니다.
그들은 중국어 NLP를 쉽게 만듭니다
언어학적 관점에서 볼 때, 중국어와 영어는 세계에서 가장 많은 사용자와 가장 큰 영향력을 가진 두 언어입니다. 그러나 서로 다른 언어적 특성으로 인해 NLP 분야의 연구에서도 서로 다른 문제에 직면하게 됩니다.
물론 중국어 NLP의 개발은 기계가 더 잘 이해할 수 있는 영어 연구에 비해 어렵고 뒤처져 있지만, 이 글에서 언급한 엔지니어들이 중국어 NLP 개발을 촉진하고, 연구 결과를 지속적으로 공유하고 있기 때문에 이러한 기술이 더 잘 반복될 수 있습니다.
그들의 노력과 수많은 고품질 프로젝트에 대한 기여에 감사드립니다! 동시에, 더 많은 사람들이 참여하고 중국 NLP의 발전을 공동으로 촉진하기를 바랍니다.
-- 위에--