Command Palette
Search for a command to run...
WideSearch 정보 수집 벤치마크 데이터 세트
*이 데이터 세트는 온라인 사용을 지원합니다.여기를 클릭하여 이동하세요.
WideSearch는 ByteDance의 Seed 팀이 2025년에 발표한 "광범위한 정보 탐색"을 위해 설계된 최초의 에이전트 평가 벤치마크 데이터셋입니다. 관련 논문 결과는 다음과 같습니다.WideSearch:벤치마킹 에이전트 광범위 정보 탐색"는 대규모 사실 수집, 합성 및 검증 가능한 구조화된 출력에서 대규모 언어 모델의 신뢰성과 무결성을 체계적으로 평가하고 촉진하는 것을 목표로 합니다.
이 벤치마크는 연구팀이 실제 사용자 질의에서 엄선하고 직접 정리한 200개의 고품질 문제(영어 100개, 중국어 100개)로 구성되어 있습니다. 이 문제들은 15개 이상의 다양한 분야에서 수집되었습니다.
데이터 필드:
- instance_id: 작업의 고유 ID(골드 CSV 파일 이름에 해당).
- 쿼리: 일반적으로 필요한 열 이름과 마크다운 테이블 출력 요구 사항을 지정하는 자연어 명령입니다.
- 평가: 자동 평가에 사용되는 직렬화된(문자열) 객체로, 다음이 포함됩니다.
- unique_columns: 기본 키 열(행 정렬용)
- 필수: 나타나야 하는 열 이름입니다.
- eval_pipeline: 열 수준 평가 구성(예: preprocess, metric, criterion).
- 언어: 작업 언어, 값은 en 또는 zh가 될 수 있습니다.
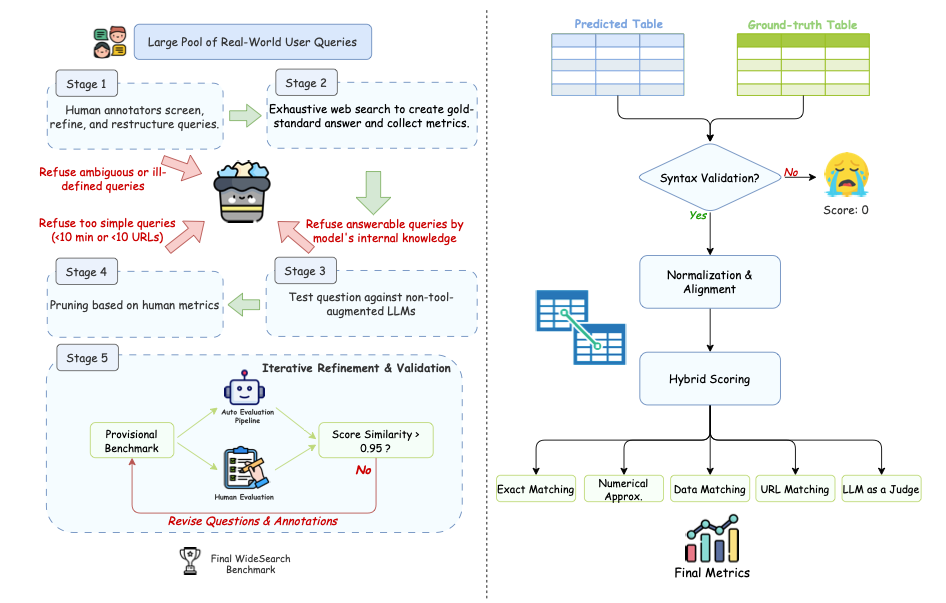
데이터 구축 및 자동 평가 흐름도