Command Palette
Search for a command to run...
LLM4Mat-Bench 결정 구조 데이터 세트
LLM4Mat-Bench는 프린스턴 대학교, 토론토 대학교 및 기타 기관이 공동으로 만든 재료 속성 예측을 위한 다중 모드 언어 모델 평가 데이터 세트입니다. 관련 논문 결과는 "LLM4Mat-Bench: 재료 속성 예측을 위한 대규모 언어 모델 벤치마킹”는 재료 특성 예측 및 재료 발견 작업에서 대규모 언어 모델(LLM)의 성능을 평가하는 것을 목표로 합니다. 이 데이터셋은 10개의 공개 재료 데이터베이스에서 수집된 약 197만 개의 결정 구조 샘플을 포함하고 있으며, 45가지의 다양한 재료 물리적 및 화학적 특성을 포괄합니다. 이는 재료 특성 예측을 위한 대규모 언어 모델(LLM)의 성능을 평가하는 데 있어 현재까지 가장 큰 벤치마크입니다.
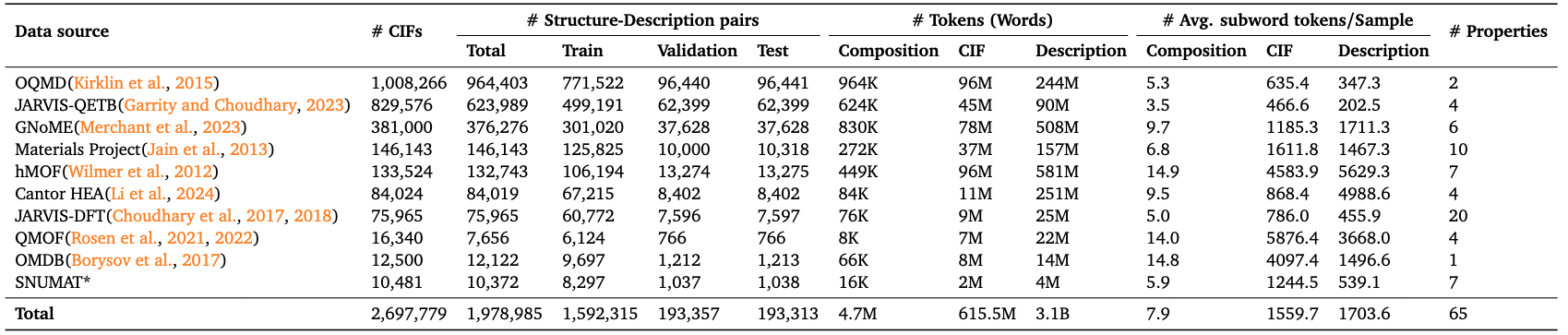
데이터 세트의 각 레코드는 결정 화학 조성, 표준 결정 구조 파일(CIF), Robocrystallographer 도구에서 생성된 결정 구조의 자연어 설명을 포함한 여러 입력 방식의 특징을 갖습니다. 이러한 방식은 LLM의 다양한 작업 시나리오에서 입력과 학습을 지원하는 데 사용되는 자료의 포괄적인 표현을 구성합니다.
총 데이터 양:
- 크리스탈 합성 모드(Composition): 약 470만 토큰
- 결정 구조 모드(CIF): 약 6억 1,550만 토큰
- 텍스트 설명: 약 31억 개의 토큰
이 데이터 세트를 구축하는 과정에는 여러 주요 재료 데이터베이스에서 원본 CIF 파일과 재료 속성을 수집하고, 결정 구조에 따라 구조 언어 설명을 자동으로 생성하여 다중 모달 통합 구조 데이터 샘플을 형성하는 작업이 포함됩니다. 각 샘플 기록에는 해당 재료 ID, 화학식, 속성 값(예: 밴드갭, 형성 에너지, 밀도, 탄성 계수 등) 및 기타 정보가 포함되어 있습니다.
LLM4Mat-Bench의 핵심 목표는 재료 과학과 자연어 처리의 교차 통합을 촉진하고, 작업별 모델 평가, 속성 예측, 지침 미세 조정 분야에서 연구 및 응용 프로그램 개발을 촉진하는 것입니다. 다중 소스, 다중 모드, 대규모 특성으로 인해 물질 언어 모델 연구에 있어 중요한 기준 벤치마크가 됩니다.