Command Palette
Search for a command to run...
* 이 데이터 세트는 온라인 사용을 지원합니다.여기를 클릭하여 이동하세요.
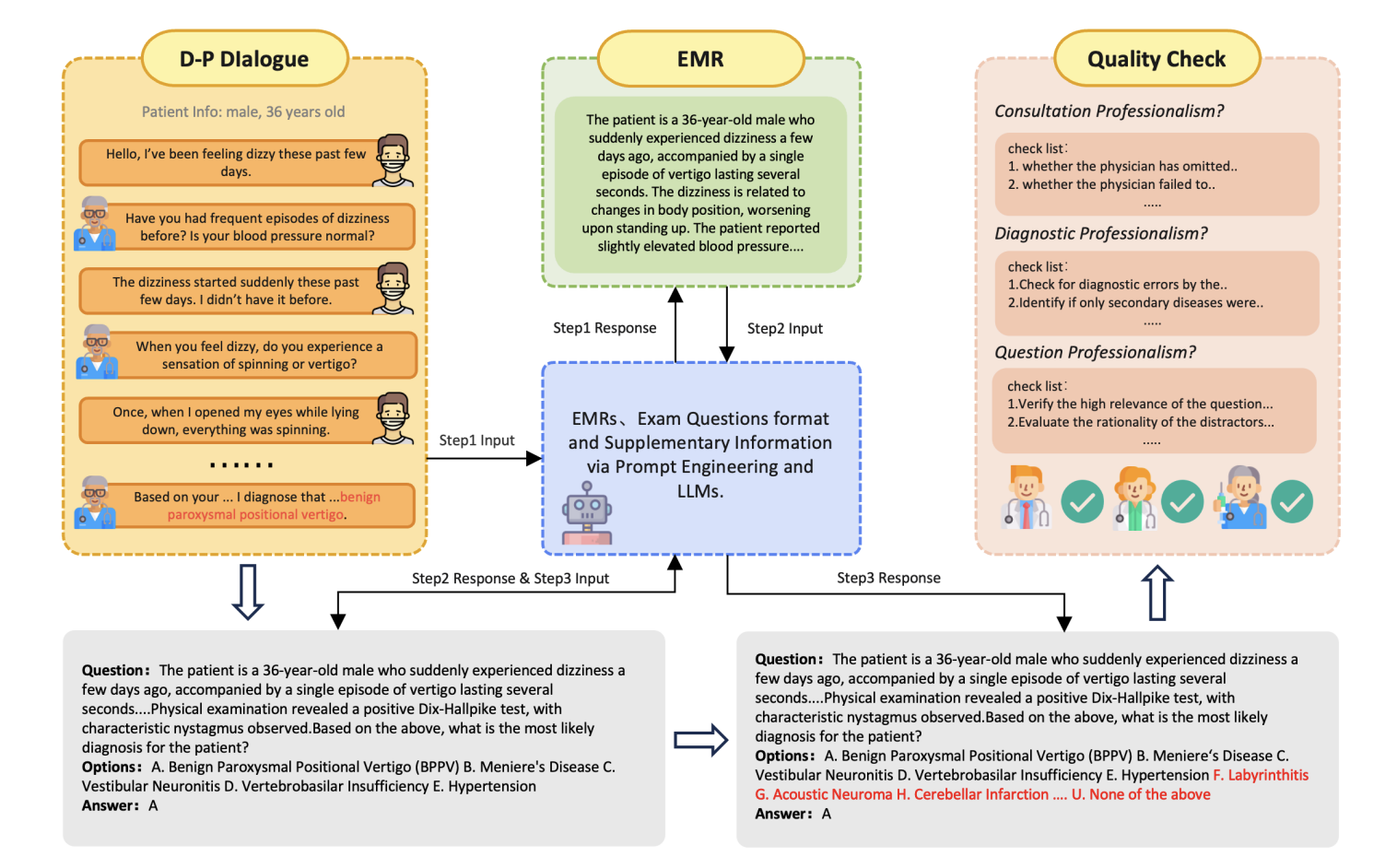
JMED 데이터 세트는 실제 의료 데이터 분포를 기반으로 한 새로운 데이터 세트입니다. 2025년 시트러스 팀에서 구축되었습니다. 관련 논문 결과는 "Citrus: 고급 의료 의사 결정 지원을 위한 의료 언어 모델에서 전문가 인지 경로 활용".
이 데이터 세트는 JD Health Internet Hospital에서 이루어진 익명의 의사-환자 대화에서 파생되었으며, 표준화된 진단 워크플로를 따르는 상담 내용을 유지하기 위해 필터링되었습니다. 최초 릴리스에는 모든 연령대(0~90세)와 다양한 전문 분야를 포괄하는 1,000개의 고품질 임상 기록이 포함되어 있습니다. 각 질문에는 21개의 답변 선택지가 있으며, 그 중 하나는 "위의 어느 것도 아님"입니다. 이러한 설계는 정답을 구별하는 데 있어 복잡성과 어려움을 크게 증가시켜, 보다 엄격한 평가 프레임워크를 제공합니다. JMED는 기존 데이터 세트와 달리 실제 임상 데이터를 면밀히 시뮬레이션하는 동시에 효율적인 모델 학습을 촉진합니다. 실제 진료 데이터를 기반으로 했지만 실제 의료 데이터에서 직접적으로 나온 것은 아니므로 연구팀은 모델 학습에 필요한 핵심 요소를 통합할 수 있습니다.
JMED는 기존의 의료 QA 데이터 세트와 비교했을 때 세 가지 주요 장점이 있습니다. 첫째, 실제 상황에서 환자 증상 설명의 모호성과 임상 진단의 역동적인 특성을 보다 정확하게 반영합니다. 두 번째로, 확장된 응답 옵션은 수많은 방해 요소 중에서 올바른 답을 찾아내기 위해 향상된 추론 기술을 요구합니다. 또한, JD의 주요 병원의 방대한 진료 데이터를 활용하여 실제 환자 분포 특성에 맞는 데이터를 지속적으로 생성할 수 있습니다.