Command Palette
Search for a command to run...
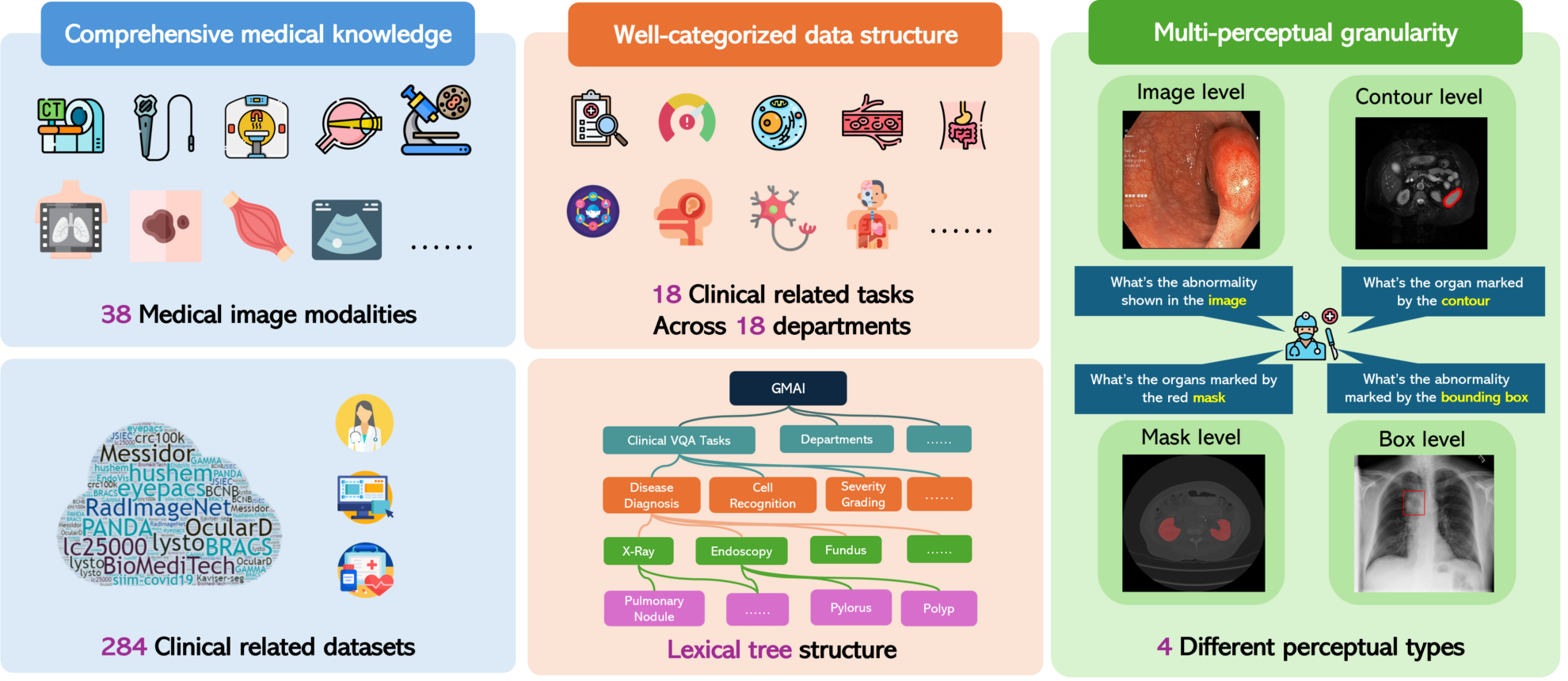
GMAI-MMBench는 일반 의료 인공지능의 개발을 촉진하기 위해 고안된 다중 모드 평가 벤치마크입니다. 이 프로젝트는 상하이 인공지능 연구소, 워싱턴 대학교, 모나쉬 대학교, 화동사범대학교, 케임브리지 대학교, 상하이 교통대학교, 홍콩 중국 대학교(선전), 선전 빅데이터 연구소, 중국과학원 선전 선진기술 연구소 등 9개 기관이 공동으로 2024년에 시작했습니다.GMAI-MMBench: 일반 의료 AI를 위한 포괄적인 다중 모드 평가 벤치마크". 이 벤치마크는 연구자와 개발자가 의료 분야에서 대형 시각 언어 모델(LVLM)의 적용 효과에 대한 심층적인 통찰력을 얻고, 포괄적이고 상세한 평가를 제공하여 기술적 단점을 파악하는 데 도움을 줍니다. 이 벤치마크는 다양한 출처의 284개 데이터셋, 38개 의료 영상 모달리티, 18개 임상 관련 과제를 포함하여 광범위한 데이터셋을 포괄하며, 18개 진료과를 포괄하고 4가지 인지 단위에서 평가되어 다차원적인 LVLM의 성능을 고려합니다.
GMAI-MMBench의 주목할 만한 특징은 다중 지각적 세분성을 평가하는 것입니다. 이는 이미지의 전반적인 수준에서의 평가에 초점을 맞추는 것이 아니라 지역 수준까지 심층적으로 조사하여 보다 세부적이고 포괄적인 평가 관점을 제공합니다. 또한 데이터 세트는 주로 병원에서 수집되고 전문 의사가 주석을 달았기 때문에 GMAI-MMBench의 평가 작업은 실제 임상 시나리오에 더 가깝고 임상적 관련성이 높습니다. 이러한 상관관계로 인해 벤치마크 결과는 실제 의료 응용 분야에 유익합니다.
GMAI-MMBench를 사용하면 사용자가 평가 작업을 사용자 정의할 수도 있습니다. 어휘 트리 구조를 구현함으로써 사용자는 자신의 필요에 따라 평가 작업을 정의할 수 있으며, 이는 의료 AI 연구 및 응용 분야에 유연성을 제공합니다. 연구팀은 몇 가지 고급 GPT-4o 모델을 포함한 50개의 LVLM을 평가한 결과, 가장 고급 모델조차도 의료 전문가의 문제를 처리하는 데 있어 52%의 정확도만 달성하는 것으로 나타났습니다. 이는 현재 LVLM을 의료 분야에 적용하는 데 여전히 개선의 여지가 많다는 것을 보여줍니다. GMAI-MMBench의 개발은 의료 분야에서 LVLM의 적용을 평가하고 개선하는 데 귀중한 자료를 제공하는 동시에 현재 기술이 직면한 과제를 밝히고 미래 연구의 방향을 제시합니다.