Command Palette
Search for a command to run...
MMedC 대규모 다국어 의학 코퍼스
* 이 데이터 세트는 온라인 사용을 지원합니다.여기를 클릭하여 이동하세요.
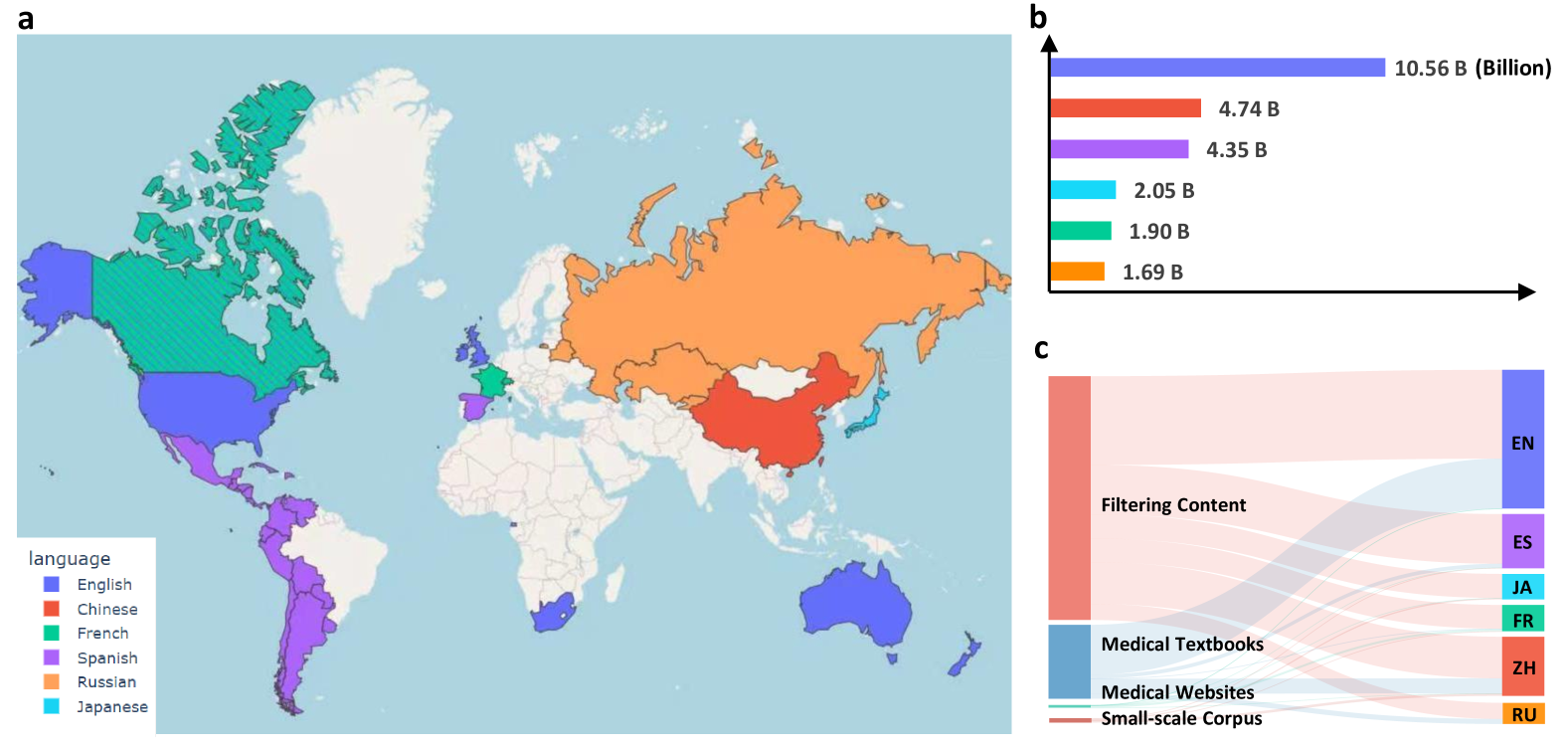
대규모 다국어 의료 코퍼스(MMedC)는 상하이 교통대학교 인공지능학원 스마트 헬스케어팀이 2024년에 구축한 다국어 의료 코퍼스입니다. 여기에는 영어, 중국어, 일본어, 프랑스어, 러시아어, 스페인어 등 6개 주요 언어를 포함하는 약 255억 개의 토큰이 포함되어 있습니다. 이 데이터 세트는 세계 대부분을 포괄하는 다국어 의료 대규모 언어 모델 개발을 촉진하기 위해 구축되었으며, 더 많은 언어에 대한 지원이 계속 업데이트되고 확장되고 있습니다. 관련 논문 결과는 다음과 같습니다.의학을 위한 다국어 언어 모델 구축을 향해", Nature Communications에 게재되었습니다.
MMedC의 데이터 소스는 주로 네 가지 측면을 포함합니다. 첫째, 의학 관련 콘텐츠는 휴리스틱 알고리즘을 통해 대규모 일반 텍스트 데이터베이스(예: CommonCrawl)에서 걸러집니다. 두 번째로, 광학 문자 인식 기술(OCR)을 사용하여 의학 교과서에서 텍스트를 추출합니다. 셋째, 많은 국가의 공식적으로 허가된 의료 웹사이트에서 데이터가 크롤링됩니다. 마지막으로, 기존의 소규모 의료 데이터 세트가 통합되었습니다.
또한 연구팀은 의료 분야에서 다국어 모델 개발을 평가하기 위해 MMedBench라는 새로운 다국어 객관식 질문 답변 평가 표준을 설계했습니다. MMedBench의 모든 문제는 단순히 번역을 통해 얻은 것이 아니라 다양한 국가의 건강 검진 문제 은행에서 직접 추출한 것이므로, 국가 간 의료 실무 지침의 차이로 인해 발생하는 진단 이해 편향을 피할 수 있습니다. 평가 과정에서 모델은 정답을 선택해야 할 뿐만 아니라 합리적인 설명도 제공해야 합니다. 이를 통해 복잡한 의료 정보를 이해하고 해석하고 보다 포괄적인 평가를 달성하는 모델의 능력을 더욱 테스트할 수 있습니다.
연구팀은 또한 여러 벤치마크에서 매우 뛰어난 성능을 보인 다국어 의료 기반 모델인 MMed-Llama 3를 오픈 소스화했으며, 기존 오픈 소스 모델보다 성능이 훨씬 뛰어나고 특히 의료 분야에서 맞춤형 미세 조정에 적합합니다. 모든 데이터와 코드는 오픈 소스로 공개되어 글로벌 연구 커뮤니티 간의 협업과 기술 공유가 더욱 촉진되었습니다.
MMedC의 구축과 오픈 소스화는 다국어 의학 언어 모델의 훈련과 평가를 위한 풍부하고 고품질의 데이터 지원을 제공하고, 언어 장벽과 의료 자원의 세계화 문제를 해결하는 데 도움이 되며, 의료 분야에 적용할 수 있는 엄청난 잠재력을 보여줍니다.