BRIGHT 텍스트 검색 벤치마크 데이터 세트
* 이 데이터 세트는 온라인 사용을 지원합니다.여기를 클릭하여 이동하세요.
이 데이터 세트는 홍콩대학교, 프린스턴대학교, 워싱턴대학교, Google Cloud AI Research가 2024년에 출시한 새로운 텍스트 검색 벤치마크입니다.BRIGHT: 추론 집약적 검색을 위한 현실적이고 도전적인 벤치마크".
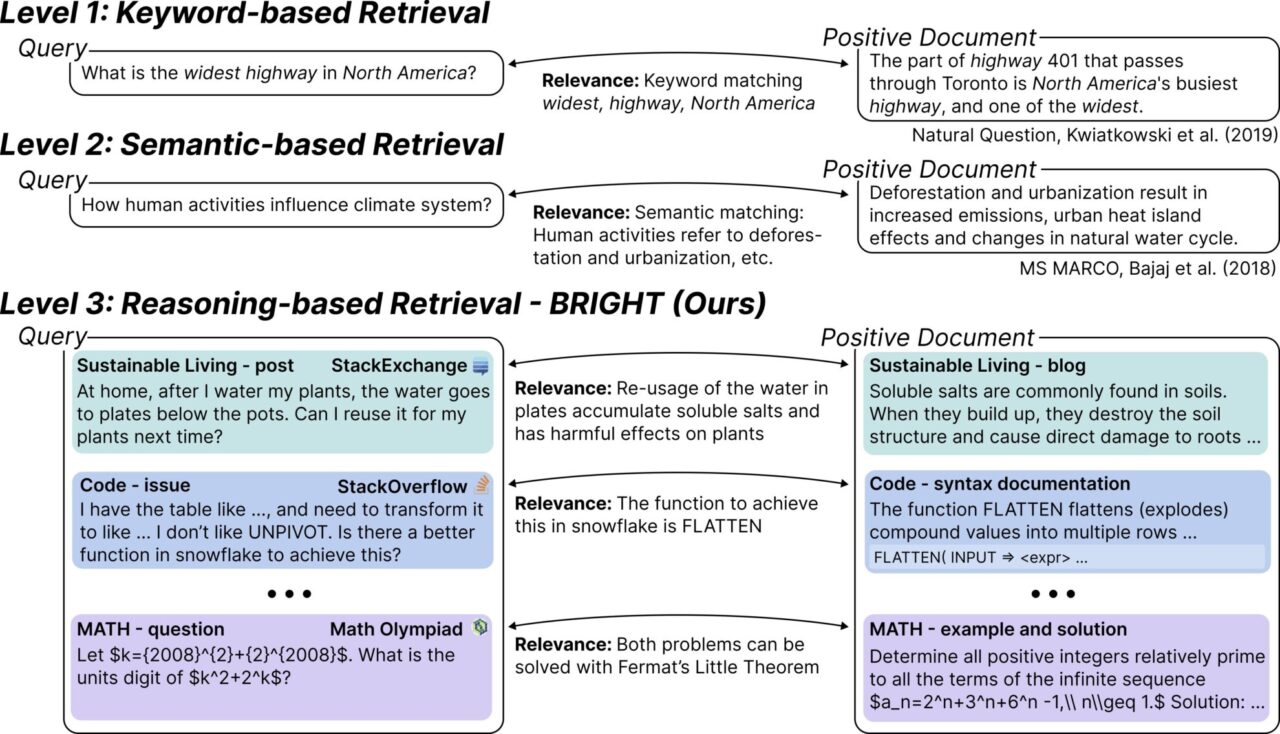
BRIGHT는 관련 문서를 검색하기 위해 심층적인 추론이 필요한 최초의 텍스트 검색 벤치마크입니다. 연구팀은 다양한 분야(StackExchange, LeetCode, 수학 경시대회)에서 1,385개의 실제 쿼리를 수집했는데, 이는 모두 실제 인공 데이터에서 나왔습니다. 연구팀은 이러한 질의를 StackExchange 답변에서 링크된 웹 페이지와 수학 올림피아드 문제에 표시된 정리와 연결했습니다.
이 테스트는 복잡한 쿼리를 처리할 때 검색 시스템의 성능을 평가하고 개선하기 위해 특별히 설계되었습니다. 이러한 질의에는 키워드 매칭뿐만 아니라 관련 문서를 식별하기 위한 심층적 추론 능력도 필요합니다. 간단히 말해서, BRIGHT는 검색 시스템이 표면적인 텍스트뿐만 아니라 쿼리의 논리와 맥락을 "이해"할 수 있는지 여부를 테스트합니다. 예를 들어, 경제학자는 인간 활동이 기후 시스템에 어떤 영향을 미치는지에 대한 문서를 찾고 싶어합니다. 이 문제는 단순히 키워드를 매칭하는 것만이 아니라, 인간 활동(산림 벌채 및 도시화 등)과 기후 변화 간의 관계를 이해하는 것을 요구합니다.
BRIGHT.torrent
시딩 1다운로드 중 0완료됨 142총 다운로드 횟수 267