Command Palette
Search for a command to run...
OceanBench 해양학 벤치마크 평가 데이터 세트
OceanBench는 저장대학교의 Zhang Ningyu와 Chen Huajun 팀이 2024년에 설계한 해양학 작업을 위한 벤치마크 평가 데이터 세트입니다. 이 데이터 세트에는 질의응답, 설명 과제 등 총 15개의 해양 관련 과제가 포함되어 있으며, 해양학 분야에서 대규모 언어 모델(LLM)의 역량을 종합적으로 평가하는 것을 목표로 합니다. OceanBench의 샘플은 시드 데이터 세트에서 자동 생성되며, 데이터의 전문성과 정확성을 보장하기 위해 전문가가 수동으로 검증합니다.
OceanBench는 해양학에서 대규모 언어 모델 개발을 촉진하기 위해 만들어졌으며, 연구자들이 해양 과학 과제에서 모델의 성능을 더 잘 이해하고 개선할 수 있도록 돕는 표준화된 테스트 플랫폼을 제공합니다. 이 벤치마크를 통해 연구자들은 해양 물리학, 해양 화학, 해양 생물학, 지질학, 수문학 등의 분야에서의 질의 응답 및 설명 생성 작업을 포함하되 이에 국한되지 않는 해양 과학의 다양한 하위 작업에 대한 모델의 역량을 평가할 수 있습니다.
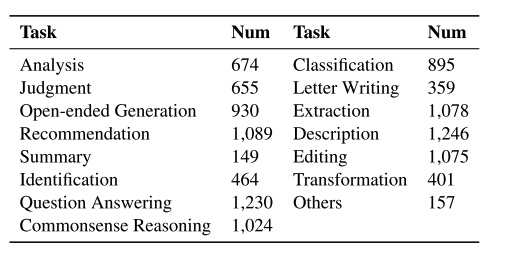
또한 OceanBench는 다음과 같은 제안도 했습니다. OceanInstruct Ocean 대형 모델 지침 데이터 세트해양 과학 분야를 위해 특별히 설계된 대규모 언어 모델 지침 데이터 세트입니다. 여기에는 20,000개의 명령어가 포함되어 있으며 해양 분야의 대규모 언어 모델에 대한 훈련 데이터를 제공하는 것을 목표로 합니다. 이 지침은 광범위한 해양 과학 지식을 포괄하여 해당 모델이 해양 과학 질문에 대한 답변, 콘텐츠 생성, 수중 구현 정보 기능 면에서 전문적인 역량을 갖추고 있음을 보장합니다. 이 데이터 세트는 해양 과학에 대한 질의응답, 콘텐츠 생성 및 기타 측면에서 좋은 성과를 보이는 OceanGPT 모델을 훈련하는 데 사용되었습니다.