Command Palette
Search for a command to run...
VEGA 과학 논문 그래픽 및 텍스트 데이터 이해 데이터 세트
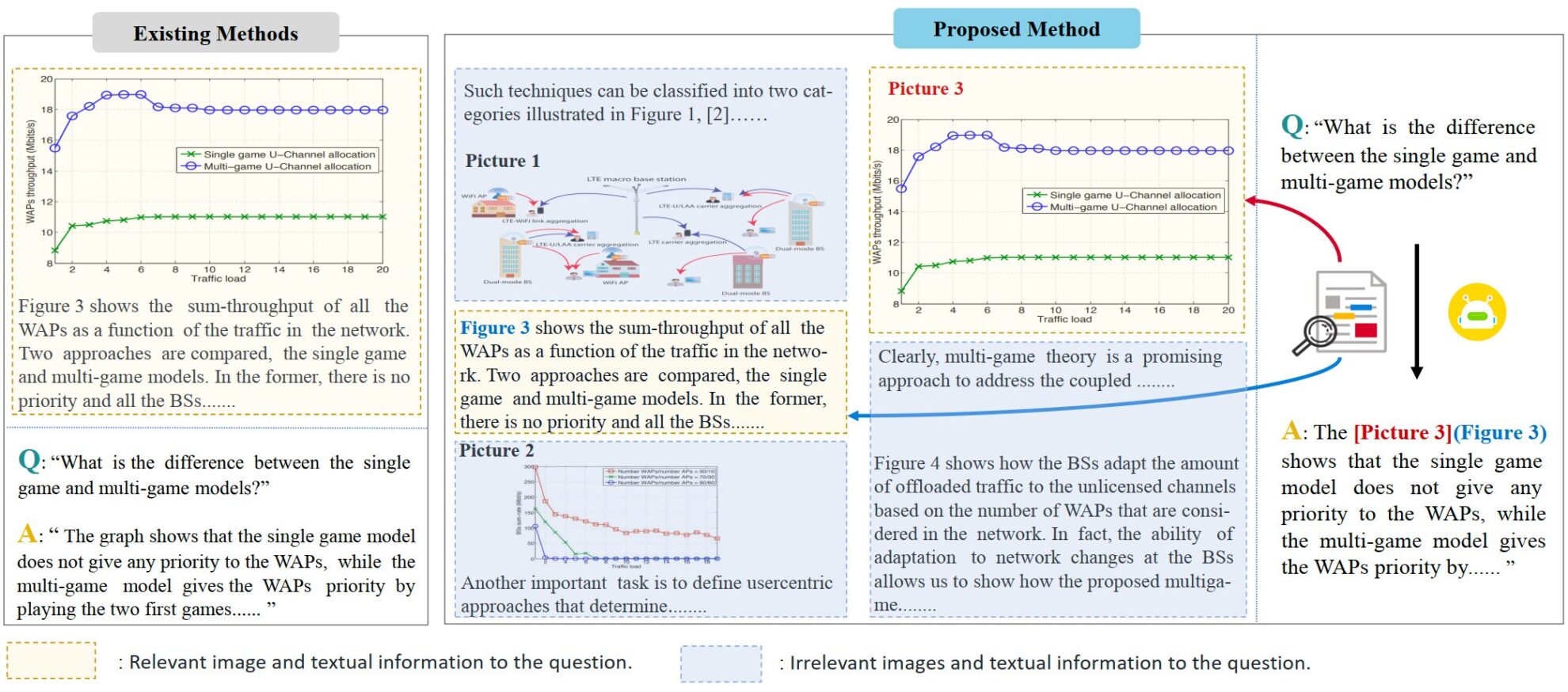
VEGA는 과학 논문 이해에 초점을 맞춘 다중 모드 데이터 세트입니다. 이 연구는 2024년 샤먼 대학의 지롱롱 팀에서 제안한 것으로, 복잡한 텍스트와 이미지 정보가 포함된 입력을 처리할 때 모델의 성능을 평가하고 개선하도록 설계되었습니다. 관련 논문은 "VEGA: 시각-언어 대형 모델에서 인터리브 이미지-텍스트 이해 학습". 이 데이터셋은 5만 편 이상의 과학 논문에서 발췌한 이미지 및 텍스트 데이터를 포함하고 있으며, 인터리브 이미지-텍스트 이해(IITC) 과제를 위해 특별히 구축되었습니다. VEGA 데이터셋의 구축 과정은 질문 선별, 맥락 구성, 답변 수정의 세 단계로 구성됩니다. 이 데이터셋은 더 길고 복잡한 인터레이스 텍스트 및 이미지 콘텐츠를 입력으로 제공하는 것을 목표로 하며, 모델이 답변 시 참조 이미지를 지정하도록 요구합니다.
VEGA는 종이 이미지 이해 작업을 위한 데이터 세트인 SciGraphQA 데이터 세트에서 파생되었으며 295,000개의 질문-답변 쌍을 포함합니다. 연구팀은 이를 바탕으로 질문 검토, 맥락 구성, 답변 수정의 세 단계를 거쳐 VEGA 데이터 세트를 얻었습니다. 여기에는 593,000개의 종이 유형의 학습 데이터와 2개의 다른 작업에 대한 2,326개의 테스트 데이터가 포함되어 있습니다. 이 알고리즘은 더 길고 복잡한 텍스트와 이미지가 섞인 콘텐츠를 입력으로 제공하고, 모델이 답변할 때 참조 이미지를 지정하도록 요구합니다.
- 질문 검토: 원본 데이터 세트의 일부 질문에는 명확한 그림 참조가 부족하여 입력 정보가 여러 그림으로 확장될 때 혼란을 야기합니다.
- 맥락 구성: 원본 데이터 세트의 질문과 답변은 단 하나의 사진에 대한 것일 뿐이며 맥락적 정보를 거의 제공하지 않습니다. 연구팀은 텍스트와 그림의 양을 늘리기 위해 arxiv에서 관련 논문의 소스 파일을 다운로드하고 4k 토큰과 8k 토큰의 두 가지 길이의 데이터를 구축했습니다. 각 질문-답변 쌍에는 최대 8개의 그림이 들어 있습니다.
- 답변 수정: 저자는 IITC 과제 요구 사항을 충족하기 위해 원본 데이터 세트의 답변을 수정하고 답변 시 참조된 이미지를 표시했습니다.
VEGA.torrent
시딩 1다운로드 중 0완료됨 194총 다운로드 횟수 236