Command Palette
Search for a command to run...
MMDU 매우 긴 다중 이미지 다중 턴 대화 이해 데이터 세트
* 이 데이터 세트는 온라인에서 이용 가능합니다.여기를 클릭하여 이동하세요.
MMDU(Multi-Turn Multi-Image Dialog Understanding)는 우한대학교, 상하이 인공지능연구소, 홍콩중국대학교, 무어스레즈가 2024년 공동으로 출시한 초장거리 다중이미지 다중턴 대화 이해 데이터셋입니다. 연구팀은 논문을 발표했습니다.MMDU: LVLM을 위한 다중 턴 다중 이미지 대화 이해 벤치마크 및 명령어 튜닝 데이터 세트논문에서는 새로운 다중 이미지 다중 라운드 평가 벤치마크 MMDU와 대규모 명령어 미세 조정 데이터 세트 MMDU-45k를 제안하여 다중 라운드 및 다중 이미지 대화에서 LVLM의 성능을 평가하고 개선하는 것을 목표로 합니다.
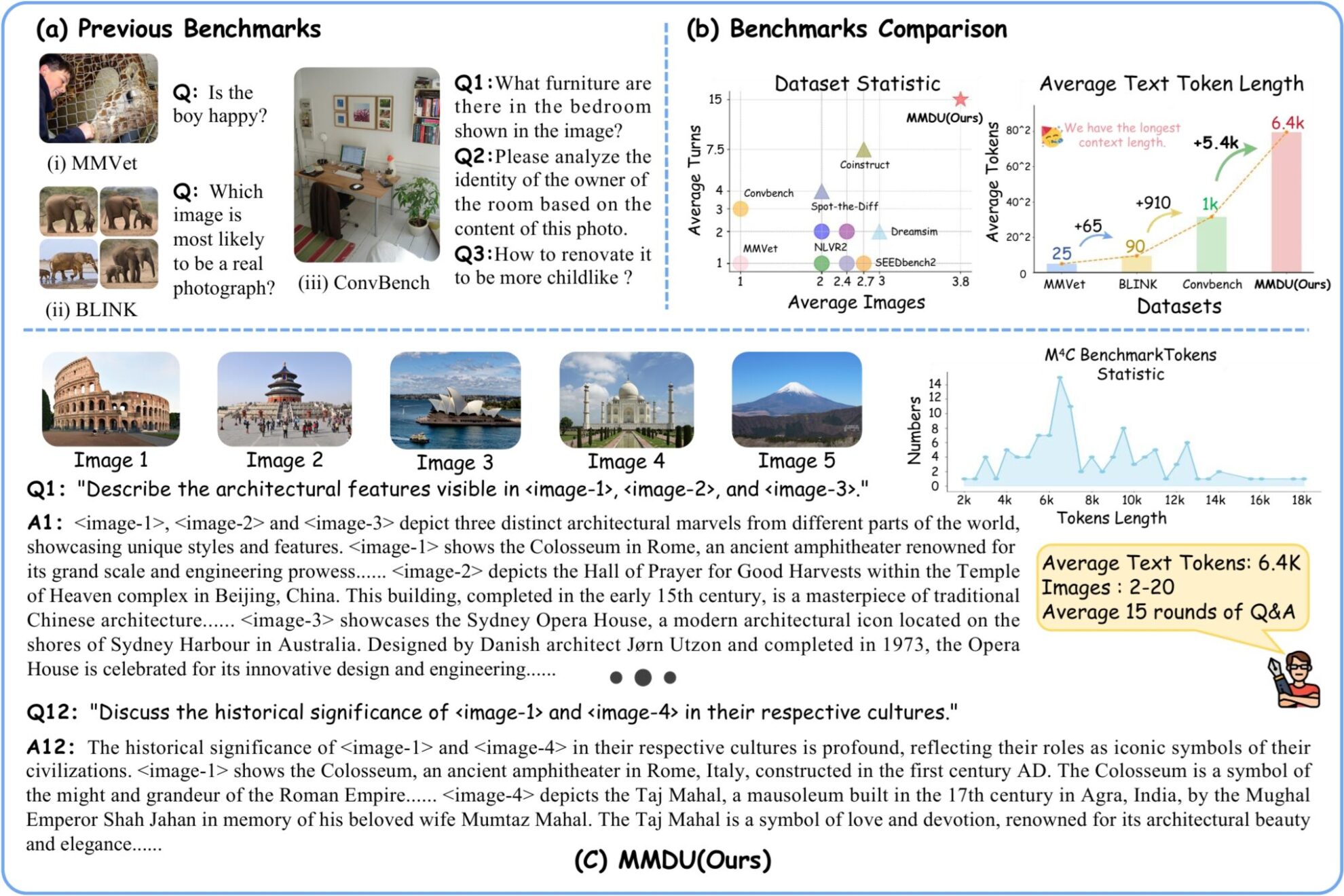
벤치마크는 1,600개 이상의 질문으로 구성된 110개의 고품질 다중 이미지 다중 턴 대화로 구성되어 있으며, 각 질문에는 자세한 긴 답변이 포함되어 있습니다. 이전 벤치마크는 대개 단일 이미지나 소수의 이미지만 포함했으며, 질문 라운드가 적고 답변이 짧았습니다. 하지만 MMDU는 이미지 수, 질의응답 라운드, 질의응답의 맥락적 길이를 크게 늘립니다. MMUD의 문제는 2~20개의 이미지와 관련이 있으며, 평균 이미지와 텍스트 태그 길이는 8.2k이고 최대 이미지와 텍스트 태그 길이는 18K로 기존의 다중 모드 대규모 모델에 상당한 어려움을 안겨줍니다.
연구팀은 MMDU-45k에서 총 45k개의 명령어 튜닝 데이터 대화를 구축했습니다. MMDU-45k 데이터 세트의 각 데이터는 매우 긴 컨텍스트를 가지고 있으며, 평균 이미지-텍스트 토큰 길이는 5k이고 최대 이미지-텍스트 토큰 길이는 17k입니다. 각 대화는 평균 9회의 질문-답변 라운드로 구성되고, 최대 27회의 라운드로 구성됩니다. 또한, 각 데이터에는 2~5장의 사진 내용이 담겨있습니다. 이 데이터 세트는 뛰어난 확장성을 갖춘 신중하게 설계된 형식으로 구성되어 있으며, 이를 결합하여 더 많고 긴 다중 그래프 다중 턴 대화를 생성할 수 있습니다. MMDU-45k의 그래프 길이와 라운드 수는 기존의 모든 명령어 튜닝 데이터 세트를 크게 능가합니다. 이러한 개선을 통해 모델의 다중 이미지 인식 및 이해 능력은 크게 향상되고, 긴 맥락 대화를 처리하는 능력도 향상됩니다.
MMDU 벤치마크에는 다음과 같은 장점이 있습니다.
(1) 다중 라운드 대화 및 다중 이미지 입력:MMDU 벤치마크는 최대 20개의 이미지와 27라운드의 질의응답 대화로 구성되어 있으며, 이전의 여러 벤치마크를 능가하고 실제 채팅 상호작용 시나리오를 사실적으로 재현했습니다.
(2) 긴 문맥:MMDU 벤치마크는 최대 18,000개의 텍스트+이미지 토큰을 통한 긴 컨텍스트 기록을 통해 LVLM이 컨텍스트 정보를 처리하고 이해하는 능력을 평가합니다.
(3) 공개평가 :MMDU는 기존 벤치마크가 의존하는 폐쇄형 질문과 짧은 출력(예: 객관식 질문이나 짧은 답변)에서 벗어나, 보다 현실적이고 세련된 평가 접근 방식을 채택합니다. 이는 자유형 다중 라운드 출력을 통해 LVLM의 성능을 평가하며, 평가 결과의 확장성과 해석성을 강조합니다.
MMDU를 구축하는 과정에서 연구자들은 오픈 소스 위키피디아에서 관련성이 높은 이미지와 텍스트 정보를 선택했고, GPT-4o 모델의 도움을 받아 인간 주석자가 질문과 답변 쌍을 구성했습니다.