Command Palette
Search for a command to run...
페르소나 허브: 웹 데이터에서 자동으로 큐레이션된 10억 개의 다양한 페르소나 데이터 세트
데이터 세트 소개
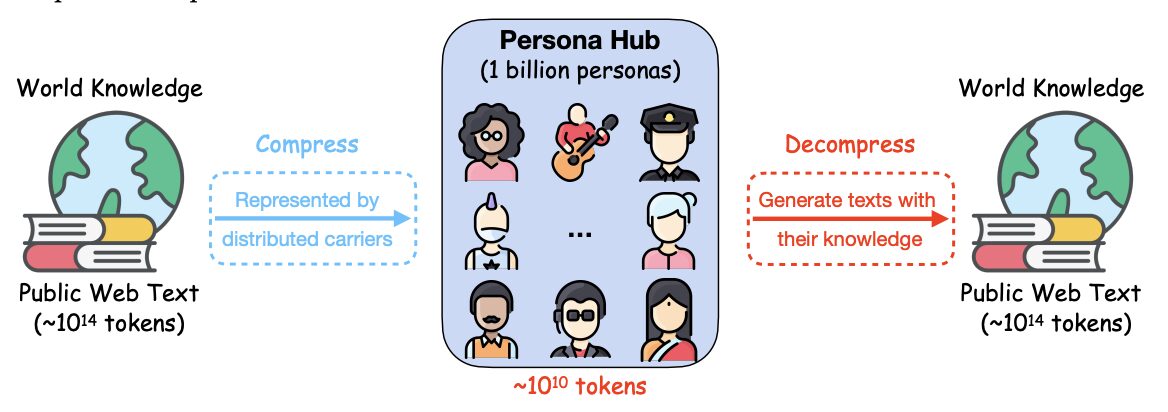
이 데이터 세트는 텐센트 시애틀 인공지능 연구소가 2024년에 출시한 네트워크 데이터에서 자동으로 구성된 10억 개의 다양한 문자로 구성된 컬렉션입니다. 이 10억 개의 문자(전 세계 인구의 약 13%)는 전 세계 지식의 분산된 운반체 역할을 하며 LLM에 캡슐화된 거의 모든 관점을 활용할 수 있으므로 다양한 시나리오에 대한 다양한 합성 데이터의 대규모 생성이 용이해집니다. 연구팀은 고품질의 수학적, 논리적 추론 문제, 지침(즉, 사용자 프롬프트), 지식이 풍부한 텍스트, 게임 NPC 및 도구(기능)의 대규모 합성에서 PERSONA HUB의 사용 사례를 보여줌으로써 페르소나 기반 데이터 합성이 다재다능하고 확장 가능하며 유연하고 사용하기 쉬우며, 합성 데이터 생성 및 실용적 적용에 패러다임 전환을 가져올 수 있는 잠재력을 가지고 있음을 입증했습니다. 이는 LLM의 연구 및 개발에 큰 영향을 미칠 수 있습니다.
관련 논문은1,000,000,000개의 페르소나를 사용한 합성 데이터 생성 확장"
데이터 세트 배경
Tencent Seattle AI Lab은 대규모 언어 모델(LLM)에서 여러 관점을 활용하여 다양한 합성 데이터를 생성하는 새로운 문자 기반 데이터 합성 방식을 소개합니다. 연구진은 10억 개의 다양한 페르소나(전 세계 인구의 약 13%)를 온라인 데이터에서 자동으로 정리하는 페르소나 허브라는 시스템을 개발했습니다. 이러한 캐릭터는 세계적 지식을 분산시킨 운반자로서 LLM에 포함된 거의 모든 관점에 접근할 수 있으므로 다양한 시나리오에 맞는 다양한 합성 데이터를 대규모로 생성하는 것이 용이해집니다. 이 기술 보고서에서는 Persona Hub를 사용함으로써 발생할 수 있는 데이터 보안, 기존 LLM의 선도적 지위에 대한 위협, 가상 세계에서 실제 사회를 시뮬레이션할 가능성 등 보다 광범위한 영향과 윤리적 문제에 대해서도 논의합니다.