Command Palette
Search for a command to run...
Firefly Chinese Llama2 증분형 사전 학습 데이터 세트
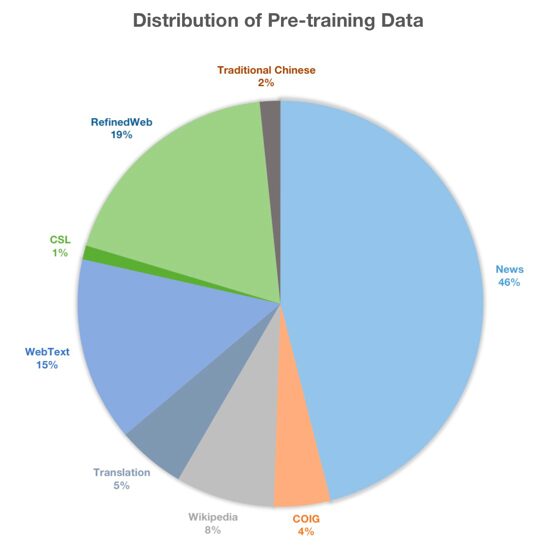
데이터 세트는 반딧불이-LLaMA2-중국 프로젝트 증분형 사전 학습 데이터는 총 22GB의 텍스트로 구성되어 있으며, 주로 연구팀이 수집한 CLUE, ThucNews, CNews, COIG, Wikipedia, 고대시, 산문, 고전 중국어 등의 오픈소스 데이터 세트를 포함합니다. 데이터 분포는 아래 그림과 같습니다.
firefly-pretrain-dataset.torrent
시딩 2다운로드 중 0완료됨 156총 다운로드 횟수 221