Command Palette
Search for a command to run...
Accumulation De Gradient
Date
Balises
L'accumulation de gradient est un mécanisme permettant de diviser un lot d'échantillons utilisé pour entraîner un réseau neuronal en plusieurs petits lots d'échantillons exécutés séquentiellement.
Avant de discuter plus en détail de l’accumulation de gradient, il est bon de passer en revue le processus de rétropropagation d’un réseau neuronal.
Rétropropagation des réseaux neuronaux
Les modèles d’apprentissage profond se composent de nombreuses couches interconnectées où les échantillons sont propagés par propagation vers l’avant à chaque étape. Après s'être propagé à travers toutes les couches, le réseau génère des prédictions pour les échantillons, puis calcule une valeur de perte pour chaque échantillon, qui spécifie « à quel point le réseau s'est trompé sur cet échantillon ». Le réseau neuronal calcule ensuite les gradients de ces valeurs de perte par rapport aux paramètres du modèle. Ces gradients sont utilisés pour calculer les mises à jour des différentes variables.
Lors de la création d'un modèle, vous choisissez un optimiseur, qui est responsable de l'algorithme utilisé pour minimiser la perte. L'optimiseur peut être l'un des optimiseurs courants implémentés dans le framework (SGD, Adam, etc.) ou un optimiseur personnalisé qui implémente l'algorithme souhaité. Outre les gradients, l'optimiseur peut également gérer et utiliser de nombreux autres paramètres pour calculer les mises à jour, tels que le taux d'apprentissage, l'indice de pas actuel (pour le taux d'apprentissage adaptatif), l'élan, etc.
Accumulation progressive de technologie
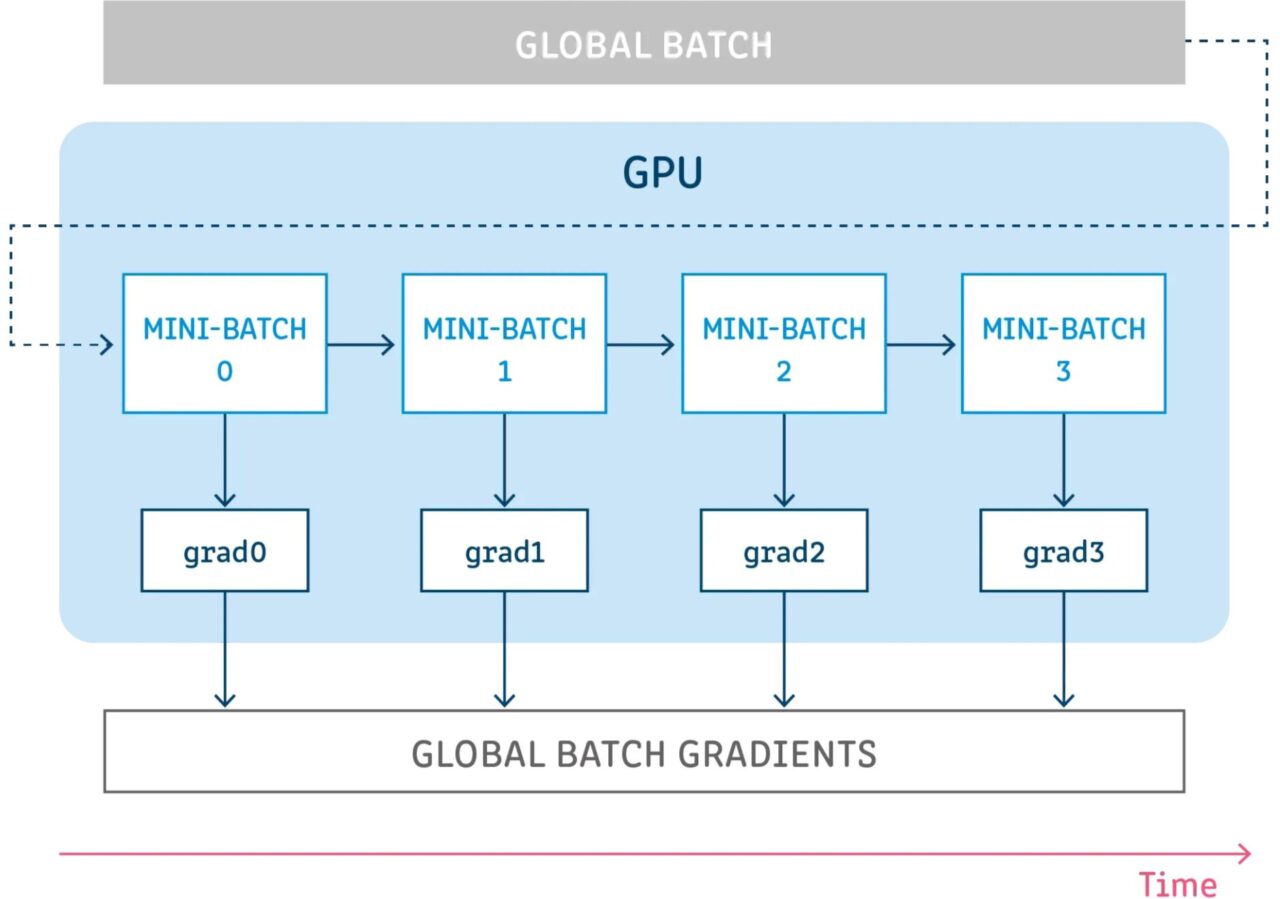
L'accumulation de gradients consiste à exécuter une configuration pendant un certain nombre d'étapes sans mettre à jour les variables du modèle tout en accumulant les gradients à ces étapes, puis en utilisant les gradients accumulés pour calculer les mises à jour des variables.
L’exécution de quelques étapes sans mettre à jour aucune variable de modèle est un moyen de diviser logiquement le lot d’échantillons en plusieurs lots plus petits. Le lot d’échantillons utilisé à chaque étape est en fait un mini-lot, tandis que les échantillons de toutes ces étapes combinées constituent en fait le lot global.
En ne mettant pas à jour les variables dans toutes ces étapes, tous les mini-lots utilisent les mêmes variables de modèle pour calculer les gradients. Il s'agit d'un comportement obligatoire pour garantir que les mêmes gradients et mises à jour sont calculés comme si la taille de lot globale était utilisée.
L’accumulation des gradients à toutes ces étapes donne la même somme de gradients.
Références
【1】https://towardsdatascience.com/what-is-gradient-accumulation-in-deep-learning-ec034122cfa
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.