Command Palette
Search for a command to run...
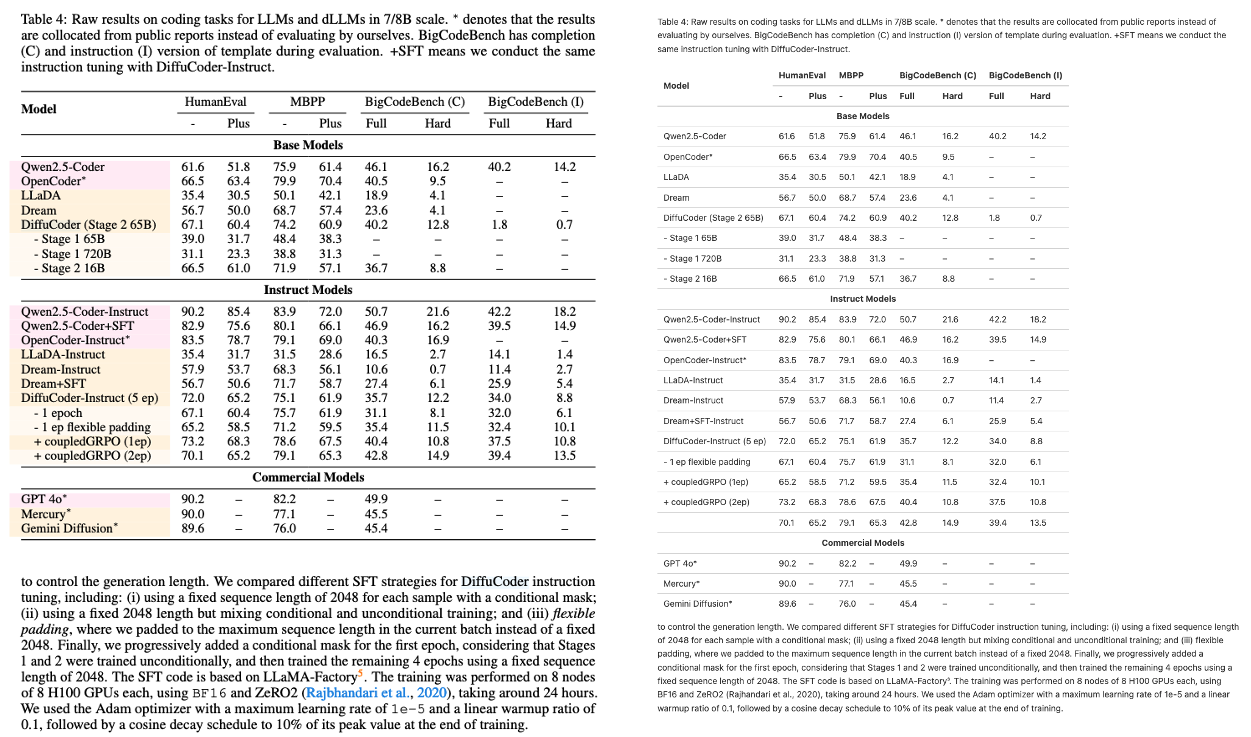
POINTS-Reader : Un Modèle De Langage De Vision De Document Léger Avec Une Architecture De Bout En Bout Sans Distillation
Date
Taille
1.2 GB
Balises
Licence
Other
GitHub
URL du document
1. Introduction au tutoriel

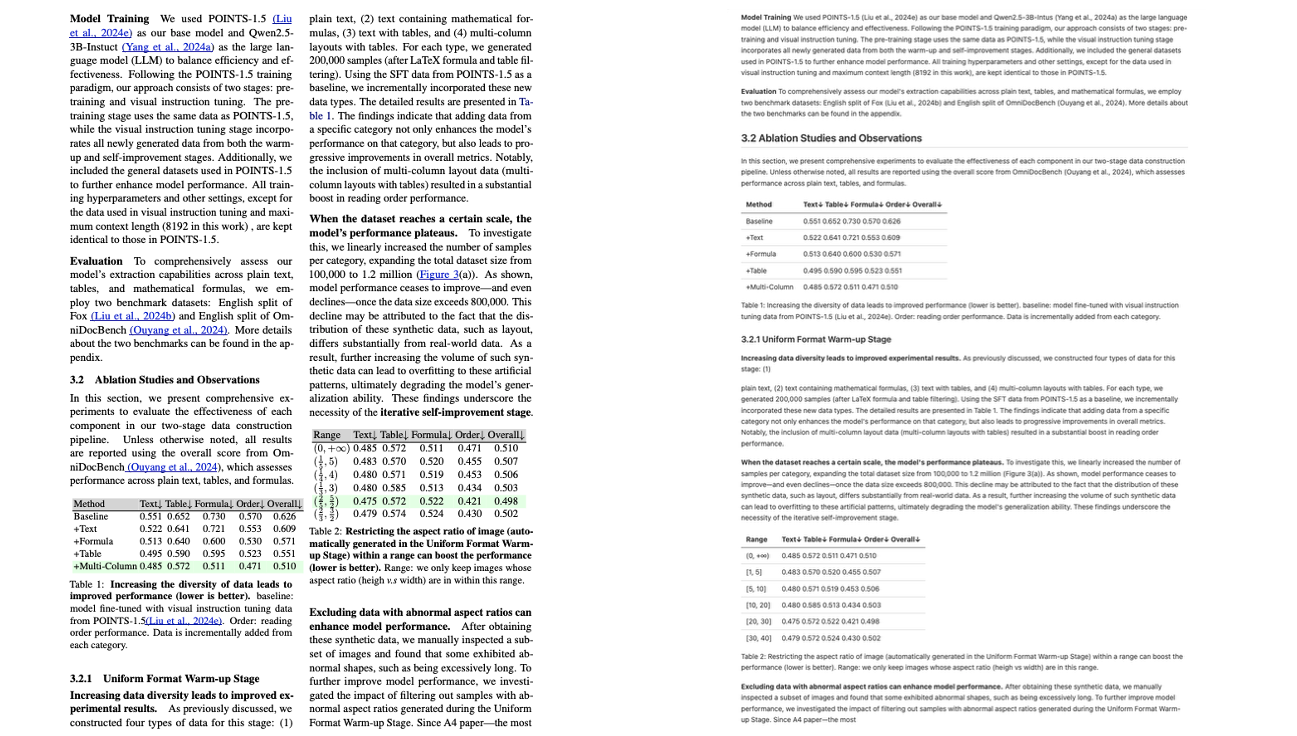
POINTS-Reader est un modèle visuel de langage (VLM) léger, développé conjointement par Tencent, l'Université Jiao Tong de Shanghai et l'Université Tsinghua en août 2025. Il est spécifiquement conçu pour la conversion d'images de documents en texte. POINTS-Reader ne nécessite pas un grand nombre de paramètres ni la « distillation » d'un modèle enseignant. Il utilise plutôt un cadre auto-évolutif en deux étapes pour une reconnaissance de bout en bout de haute précision de documents complexes en chinois et en anglais (incluant tableaux, formules et mises en page à plusieurs colonnes), tout en conservant une structure minimaliste. Des articles de recherche associés sont disponibles. POINTS-Reader : Adaptation sans distillation de modèles vision-langage pour la conversion de documents Elle a été acceptée par EMNLP 2025 et sera présentée lors de la conférence principale.
Les ressources informatiques utilisées dans ce tutoriel sont une seule carte RTX 4090.
2. Affichage des effets
Colonne simple avec formule latex

Colonne unique avec tableau
Multi-colonnes avec formule Latex

Multi-colonnes avec tableau
3. Étapes de l'opération
1. Démarrez le conteneur
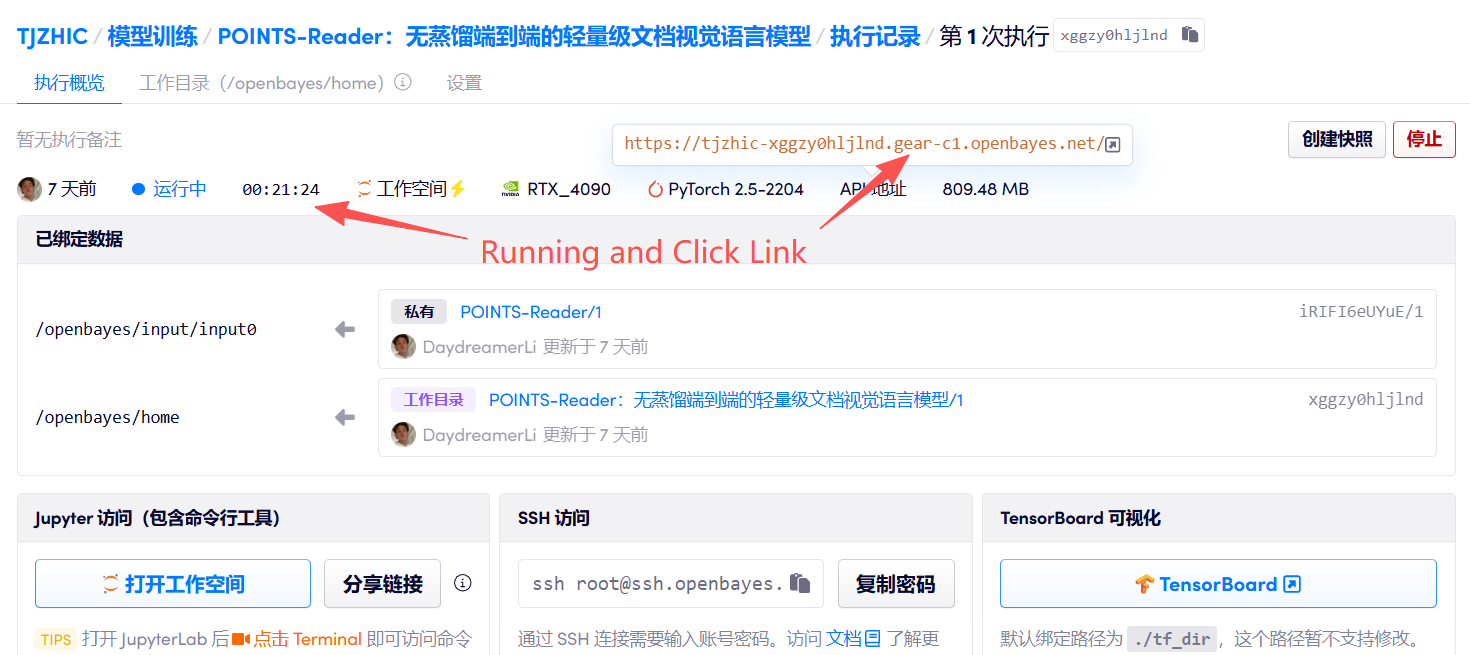
2. Étapes d'utilisation
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 2 à 3 minutes et actualiser la page.
1. Contenu extrait
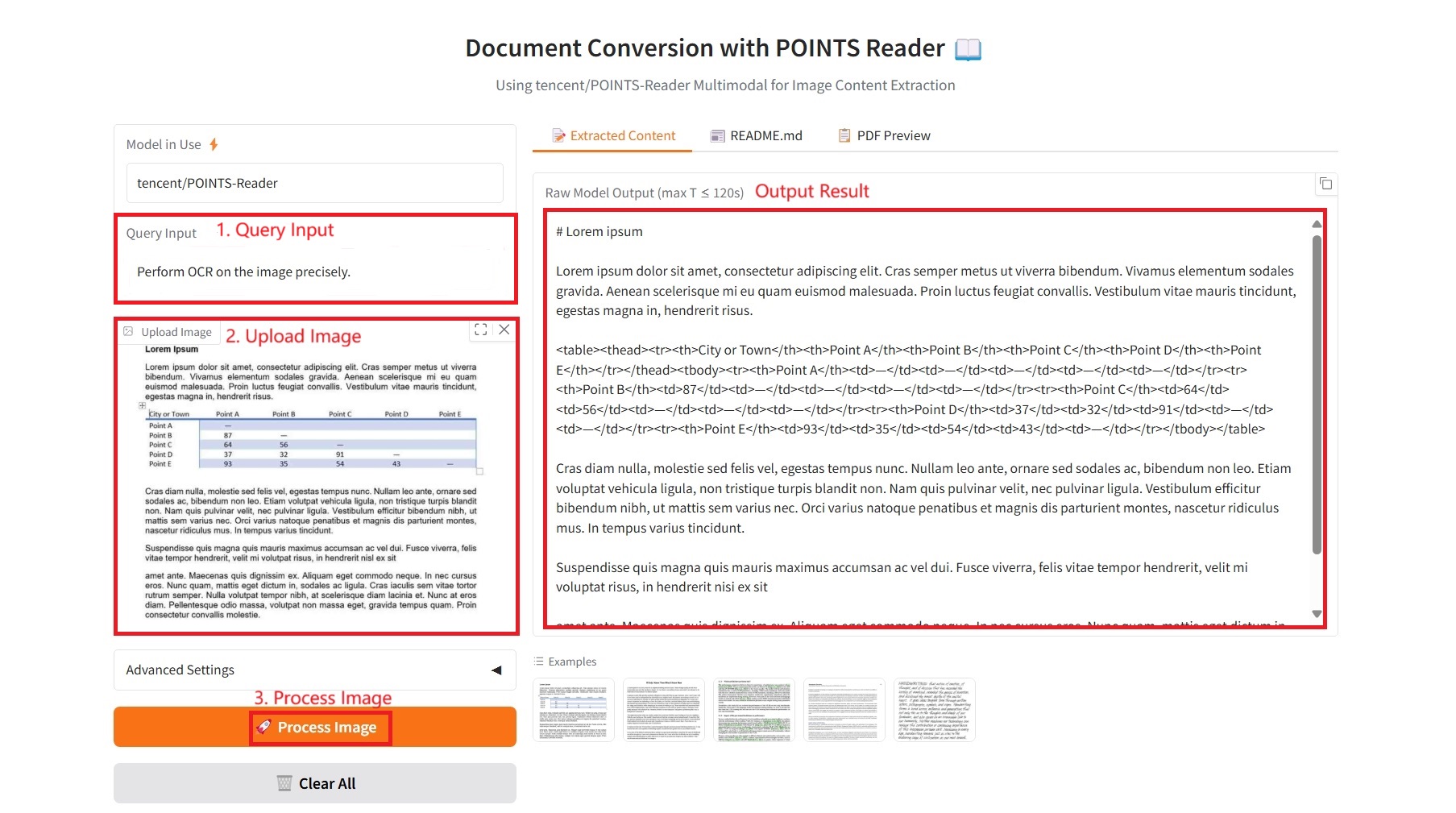
Paramètres spécifiques :
- Saisie de requête : saisissez les exigences de texte.
- Facteur d'agrandissement de l'image : Augmente la taille de l'image avant traitement. Peut améliorer la reconnaissance optique de caractères (OCR) des petits textes. Valeur par défaut : 1,0 (aucune modification).
- Nombre maximal de nouveaux jetons : la limite de longueur maximale du texte généré, qui contrôle la limite supérieure du nombre de mots dans le contenu de sortie.
- Top-p (échantillonnage du noyau) : un paramètre d'échantillonnage du noyau qui sélectionne l'ensemble de mots minimum avec une probabilité cumulative de p pour l'échantillonnage afin de contrôler la diversité de sortie.
- Top-k : Échantillon des k mots candidats présentant la probabilité la plus élevée. Plus la valeur est élevée, plus le résultat est aléatoire ; plus la valeur est faible, plus le résultat est fiable.
- Température : Contrôle le caractère aléatoire du texte généré. Des valeurs élevées produisent un résultat plus aléatoire et diversifié, tandis que des valeurs faibles produisent un résultat plus déterministe et conservateur.
- Pénalité de répétition : une valeur supérieure à 1,0 réduit la génération de contenu dupliqué. Plus la valeur est élevée, plus la pénalité est importante.
- Paramètres d'exportation PDF :
- Taille de police : la taille de police du texte dans le PDF, qui contrôle la lisibilité du document exporté.
- Espacement des lignes : l’espacement des lignes entre les paragraphes d’un PDF affecte l’esthétique et la lisibilité du document.
- Alignement du texte : l'alignement du texte dans un PDF, y compris l'alignement à gauche, l'alignement au centre, l'alignement à droite ou la justification.
- Taille de l'image dans le PDF : la taille de l'image intégrée dans le PDF, y compris les options petite, moyenne et grande.
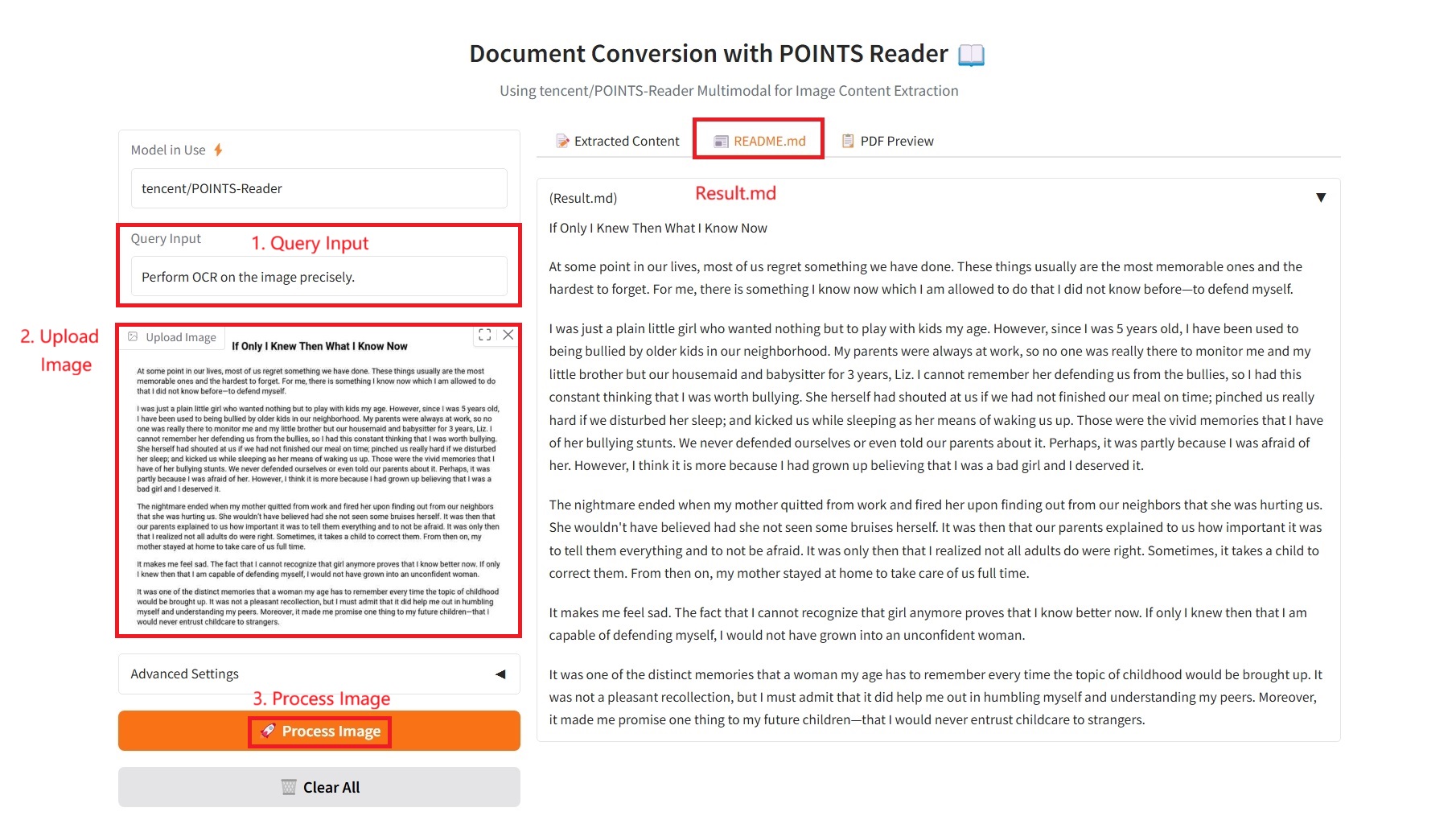
2. README.md
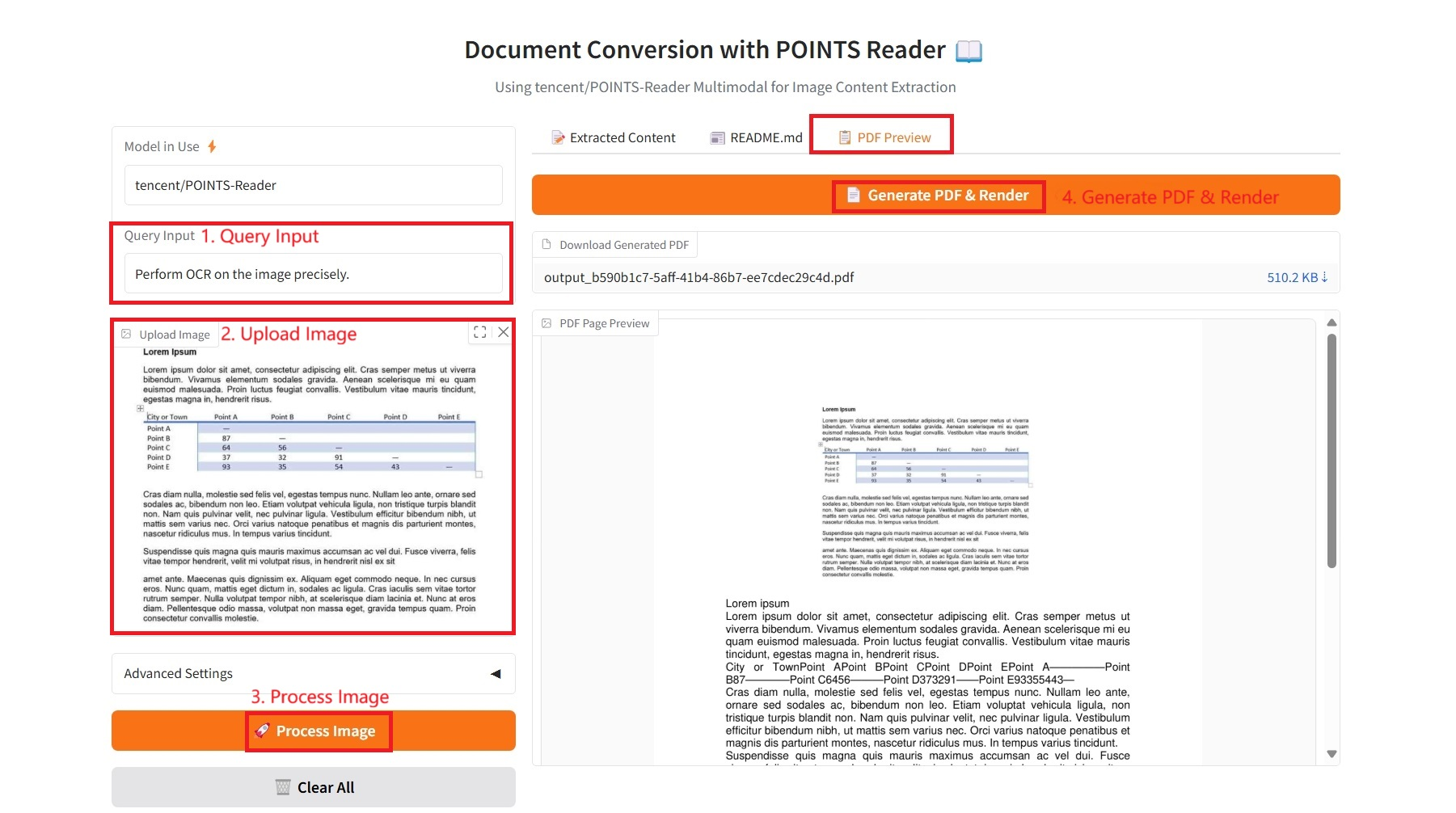
3. Aperçu PDF
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@article{points-reader, title={POINTS-Reader: Distillation-Free Adaptation of Vision-Language Models for Document Conversion}, author={Liu, Yuan and Zhongyin Zhao and Tian, Le and Haicheng Wang and Xubing Ye and Yangxiu You and Zilin Yu and Chuhan Wu and Zhou, Xiao and Yu, Yang and Zhou, Jie}, journal={EMNLP2025}, year={2025} } @article{liu2024points1,
title={POINTS1. 5: Building a Vision-Language Model towards Real World Applications},
author={Liu, Yuan and Tian, Le and Zhou, Xiao and Gao, Xinyu and Yu, Kavio and Yu, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2412.08443},
year={2024}
} @article{liu2024points,
title={POINTS: Improving Your Vision-language Model with Affordable Strategies},
author={Liu, Yuan and Zhao, Zhongyin and Zhuang, Ziyuan and Tian, Le and Zhou, Xiao and Zhou, Jie},
journal={arXiv preprint arXiv:2409.04828},
year={2024}
}@article{liu2024rethinking,
title={Rethinking Overlooked Aspects in Vision-Language Models},
author={Liu, Yuan and Tian, Le and Zhou, Xiao and Zhou, Jie},
journal={arXiv preprint arXiv:2405.11850},
year={2024}
}
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.