Command Palette
Search for a command to run...
Déploiement vLLM + Open WebUI De NVIDIA-Nemotron-Nano-9B-v2
1. Introduction au tutoriel
NVIDIA Nemotron Nano 9B v2 est un modèle de langage léger et performant, publié par l'équipe NVIDIA le 19 août 2025. Version optimisée de la série Nemotron, ce modèle hybride combine de manière innovante le traitement efficace des longues séquences de Mamba avec les puissantes capacités de modélisation sémantique de Transformer. Il prend en charge jusqu'à 128 000 contextes ultra-longs avec seulement 9 milliards (9 Md) de paramètres. Son efficacité d'inférence et ses performances sur les dispositifs de calcul en périphérie (tels que les GPU de type RTX 4090) sont comparables à celles des modèles de pointe avec un nombre de paramètres similaire, ce qui représente une avancée majeure en matière de déploiement léger et de compréhension de textes longs pour les grands modèles de langage. Des articles de recherche associés sont disponibles. NVIDIA Nemotron Nano 2 : un modèle de raisonnement hybride Mamba-Transformer précis et efficace .
Ce tutoriel utilise une seule carte RTX A6000 comme ressource.
2. Exemples de projets
3. Étapes de l'opération
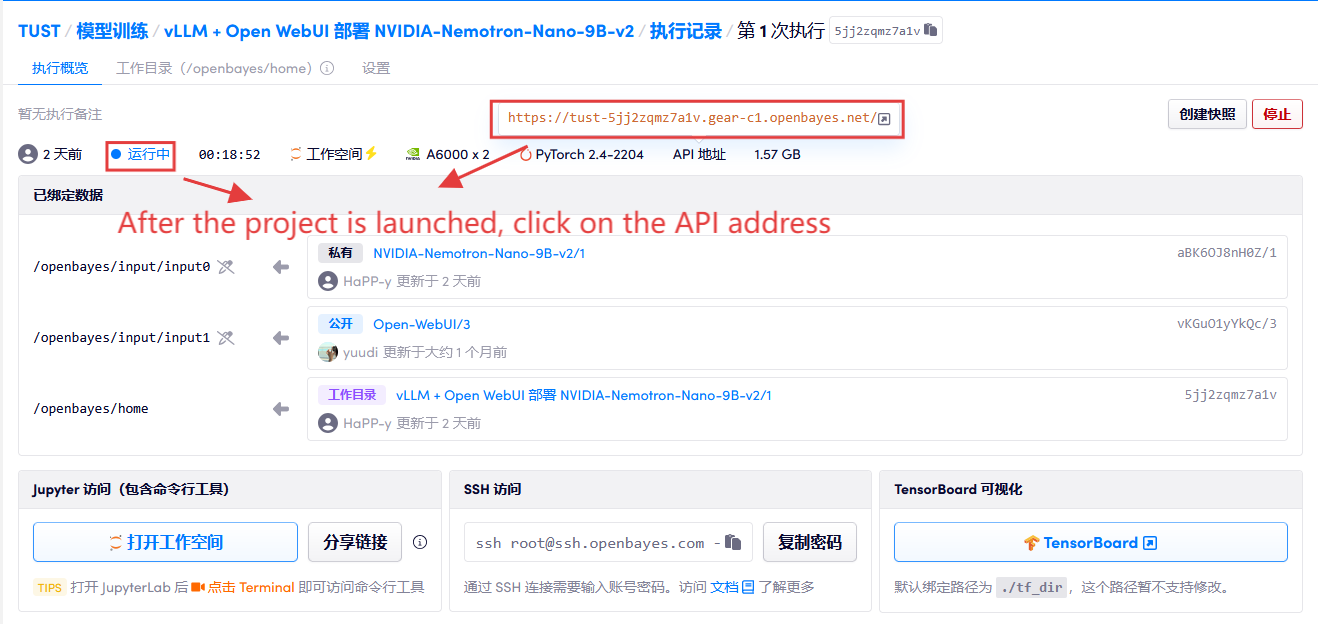
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
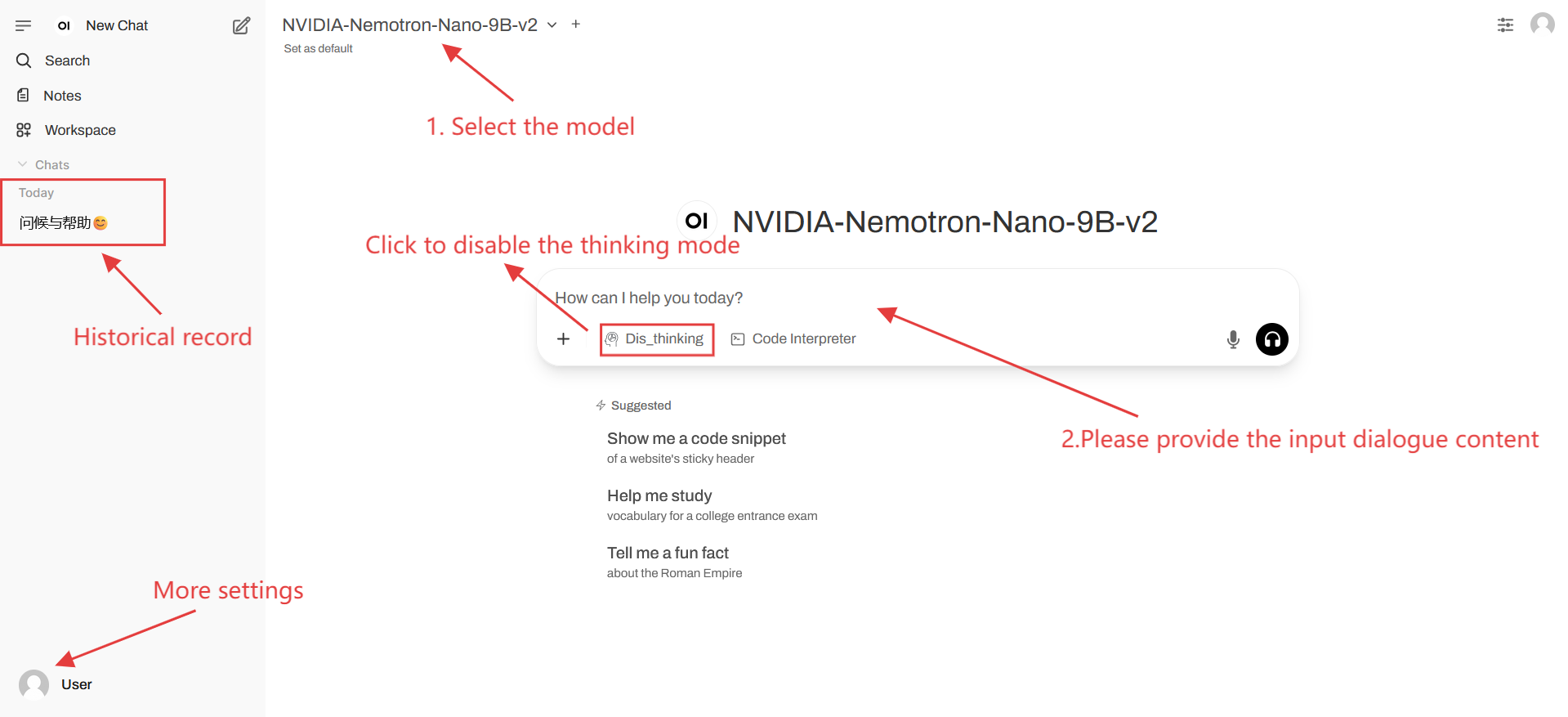
2. Après être entré sur la page Web, vous pouvez démarrer une conversation avec le modèle
Si « Modèle » n'est pas affiché, cela signifie que le modèle est en cours d'initialisation. Le modèle étant volumineux, veuillez patienter 2 à 3 minutes avant d'actualiser la page.
Comment utiliser
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@misc{nvidia2025nvidianemotronnano2,
title={NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model},
author={NVIDIA},
year={2025},
eprint={2508.14444},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.14444},
}Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.