Command Palette
Search for a command to run...
Déploiement vLLM+Open WebUI Phi-4-mini-flash-reasoning
Date
Taille
1.48 MB
Balises
Licence
MIT
GitHub
URL du document
1. Introduction au tutoriel

Phi-4-mini-flash-reasoning est un modèle léger et open source développé par l'équipe Microsoft. Basé sur des données synthétiques, il exploite des données d'inférence intensives et de haute qualité et est optimisé pour offrir des capacités de raisonnement mathématique avancées. Ce modèle, appartenant à la famille Phi-4, prend en charge des contextes de jetons de 64 000 éléments, utilise une architecture décodeur-décodeur hybride et combine des mécanismes d'attention et un modèle d'espace d'états (SSM), démontrant ainsi une excellente efficacité d'inférence. Des articles de recherche associés sont disponibles. Architecture décodeur-décodeur hybride pour un raisonnement efficace avec une génération longue .
Ce tutoriel utilise une seule carte RTX 4090. Les invites du projet prennent en charge le chinois et l'anglais.
2. Exemples de projets
3. Étapes de l'opération
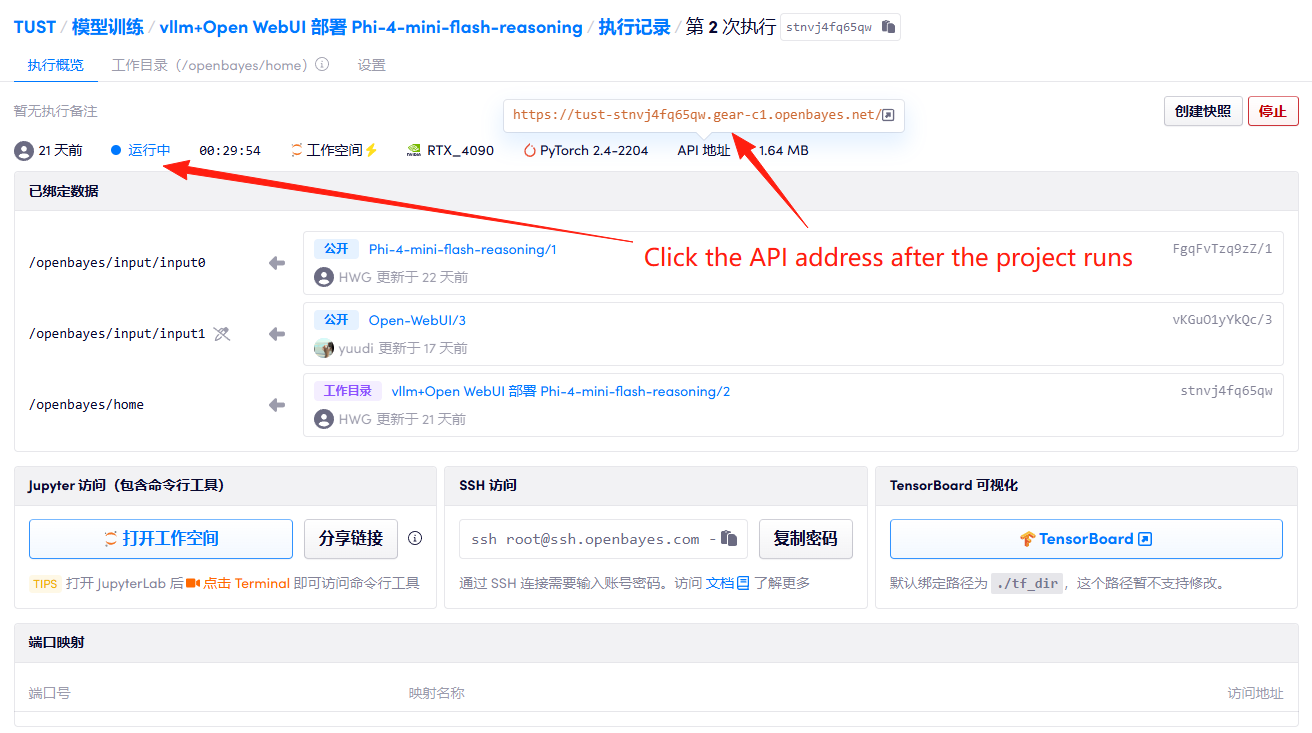
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
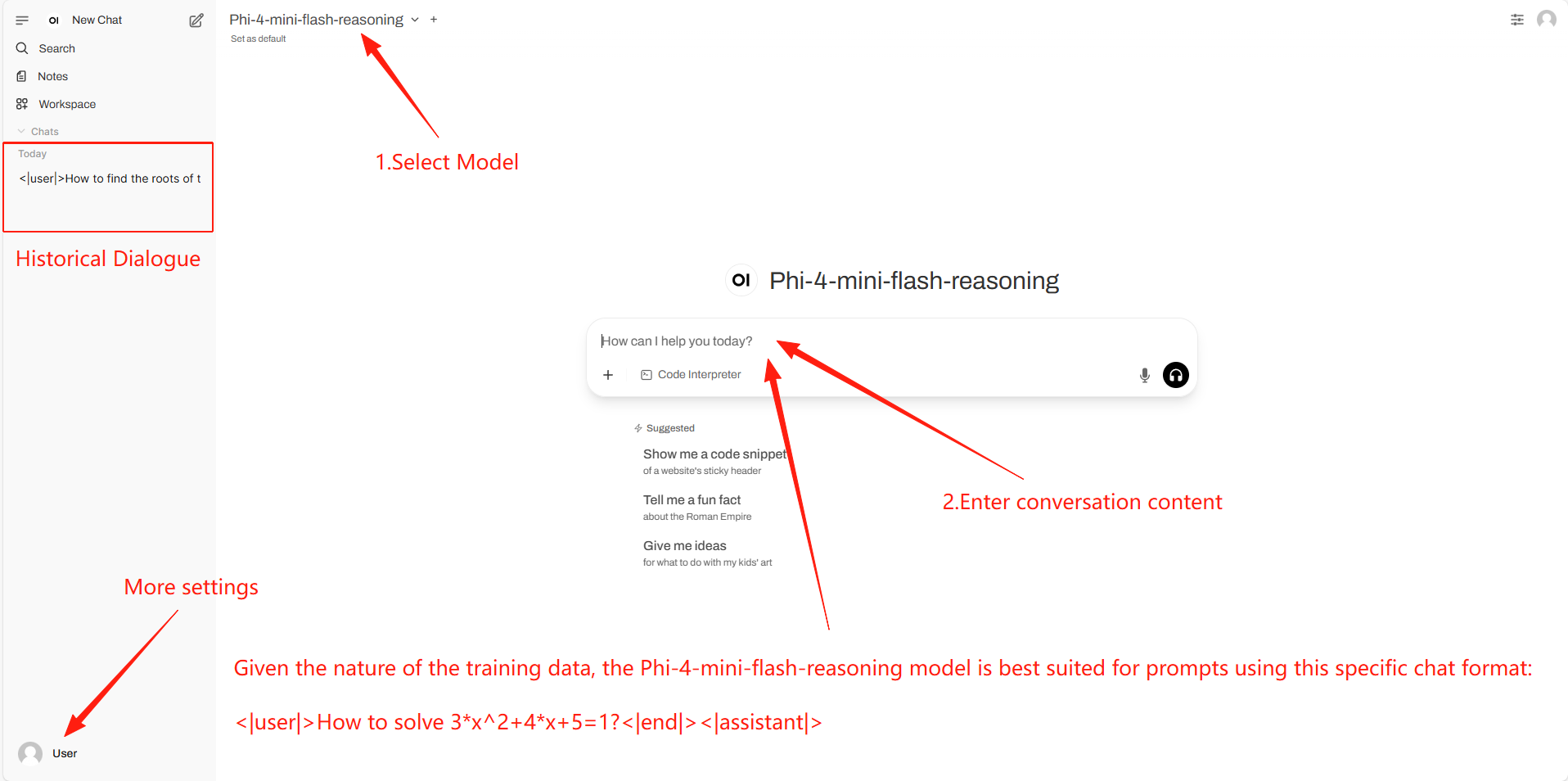
2. Étapes d'utilisation
Si « Modèle » n'apparaît pas, cela signifie que le modèle est en cours d'initialisation. Le modèle étant volumineux, veuillez patienter 1 à 3 minutes avant d'actualiser la page.
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@software{archscale2025, title={ArchScale: Simple and Scalable Pretraining for Neural Architecture Research}, author={Liliang Ren and Zichong Li and Yelong Shen}, year={2025}, url={https://github.com/microsoft/ArchScale} }@article{ren2025decoder,
title={Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation},
author={Liliang Ren and Congcong Chen and Haoran Xu and Young Jin Kim and Adam Atkinson and Zheng Zhan and Jiankai Sun and Baolin Peng and Liyuan Liu and Shuohang Wang and Hao Cheng and Jianfeng Gao and Weizhu Chen and Yelong Shen},
journal={arXiv preprint arXiv:2507.06607},
year={2025}
}
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.