Command Palette
Search for a command to run...
LFM2-1.2B : Un Modèle De Génération De Texte Pour Un Déploiement Efficace En Périphérie
1. Introduction au tutoriel
LFM2-1.2B est la deuxième génération de Liquid Foundation Model (LFM) lancée par Liquid AI le 10 juillet 2025. Ce modèle d'IA générative repose sur une architecture hybride. Il vise à offrir l'expérience d'IA générative sur appareil la plus rapide du secteur et est conçu pour les charges de travail de modèles de langage sur appareil à faible latence.
Modèle utilisant une nouvelle architecture hybride, LFM2-1.2B combine de manière innovante la multiplication par portes et la convolution courte. Il contient 16 blocs (10 blocs de convolution LIV courte portée à double porte et 6 blocs d'attention de requête de groupe), ce qui résout les lacunes des modèles traditionnels en termes d'efficacité et de performance de traitement. Son entraînement repose sur un corpus de pré-entraînement de 10 000 milliards de jetons et adopte des stratégies d'entraînement en plusieurs étapes telles que la distillation des connaissances, le réglage fin supervisé à grande échelle (SFT) et l'optimisation des préférences directes personnalisées (DPO). Il surpasse les modèles de même échelle dans plusieurs catégories de référence telles que les connaissances, les mathématiques, le suivi des instructions et les capacités multilingues, et peut même rivaliser avec des modèles dotés de plus grandes échelles de paramètres. Parallèlement, sa vitesse de décodage et de pré-remplissage sur le processeur est deux fois plus rapide que celle de Qwen 3, et son efficacité d'entraînement est trois fois supérieure à celle de la génération précédente de LFM. Il peut fonctionner efficacement sur CPU, GPU et NPU, offrant une solution flexible et performante pour le déploiement d'appareils périphériques.
Ce didacticiel utilise LFM2-1.2B comme démonstration et la ressource informatique utilise RTX 4090. Langues prises en charge : anglais, arabe, chinois, français, allemand, japonais, coréen et espagnol.
2. Exemples de projets
3. Étapes de l'opération
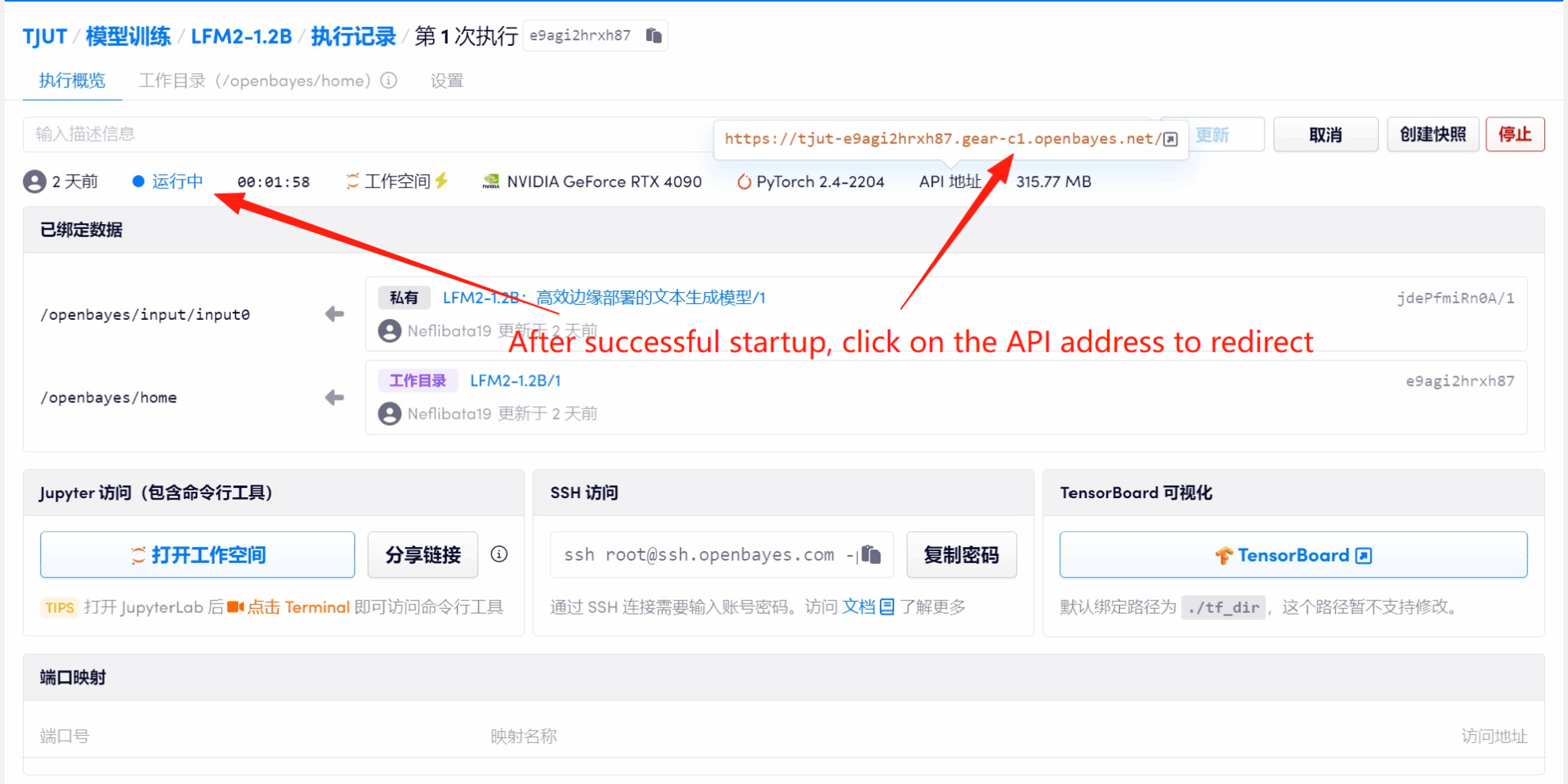
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
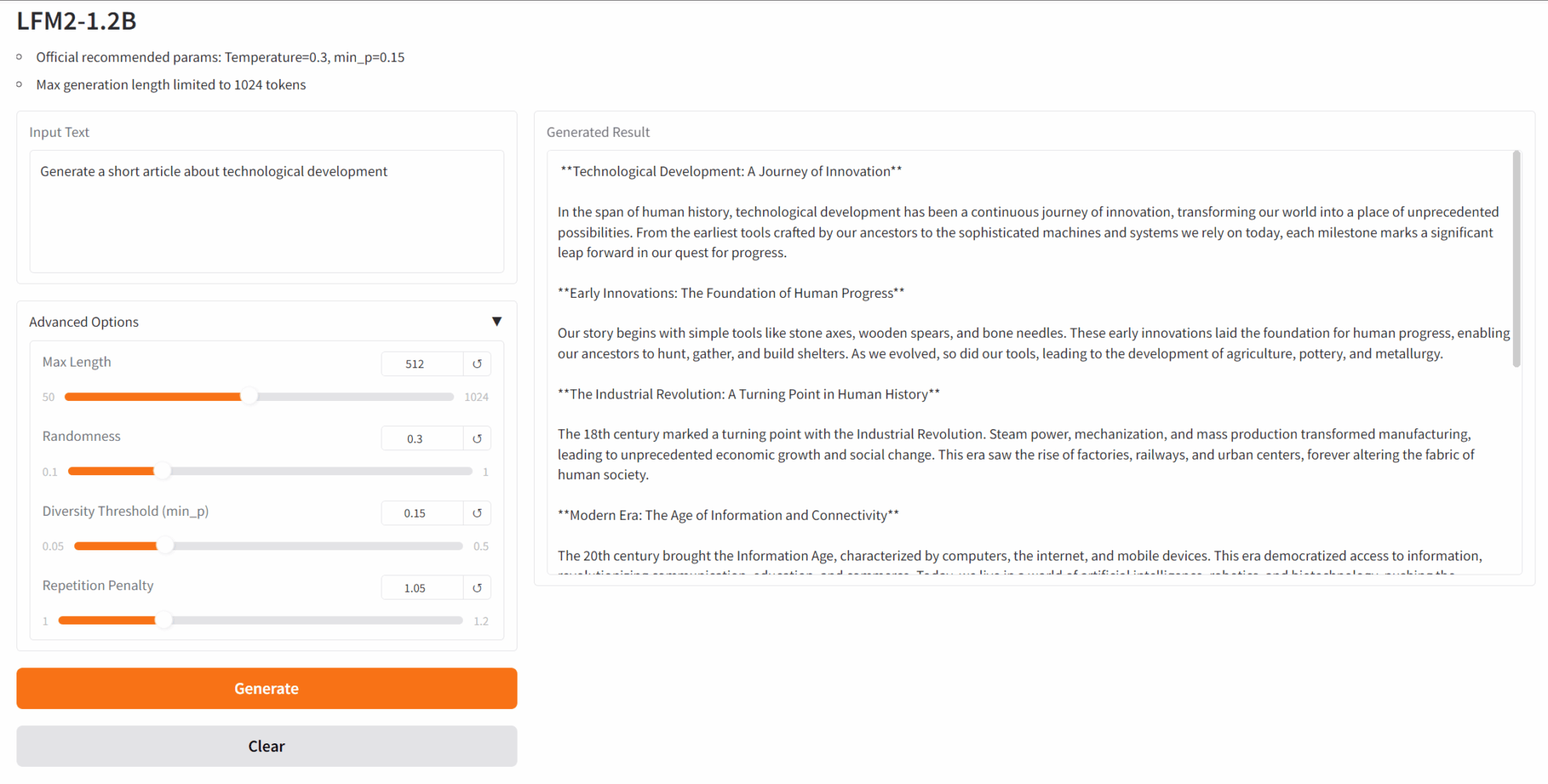
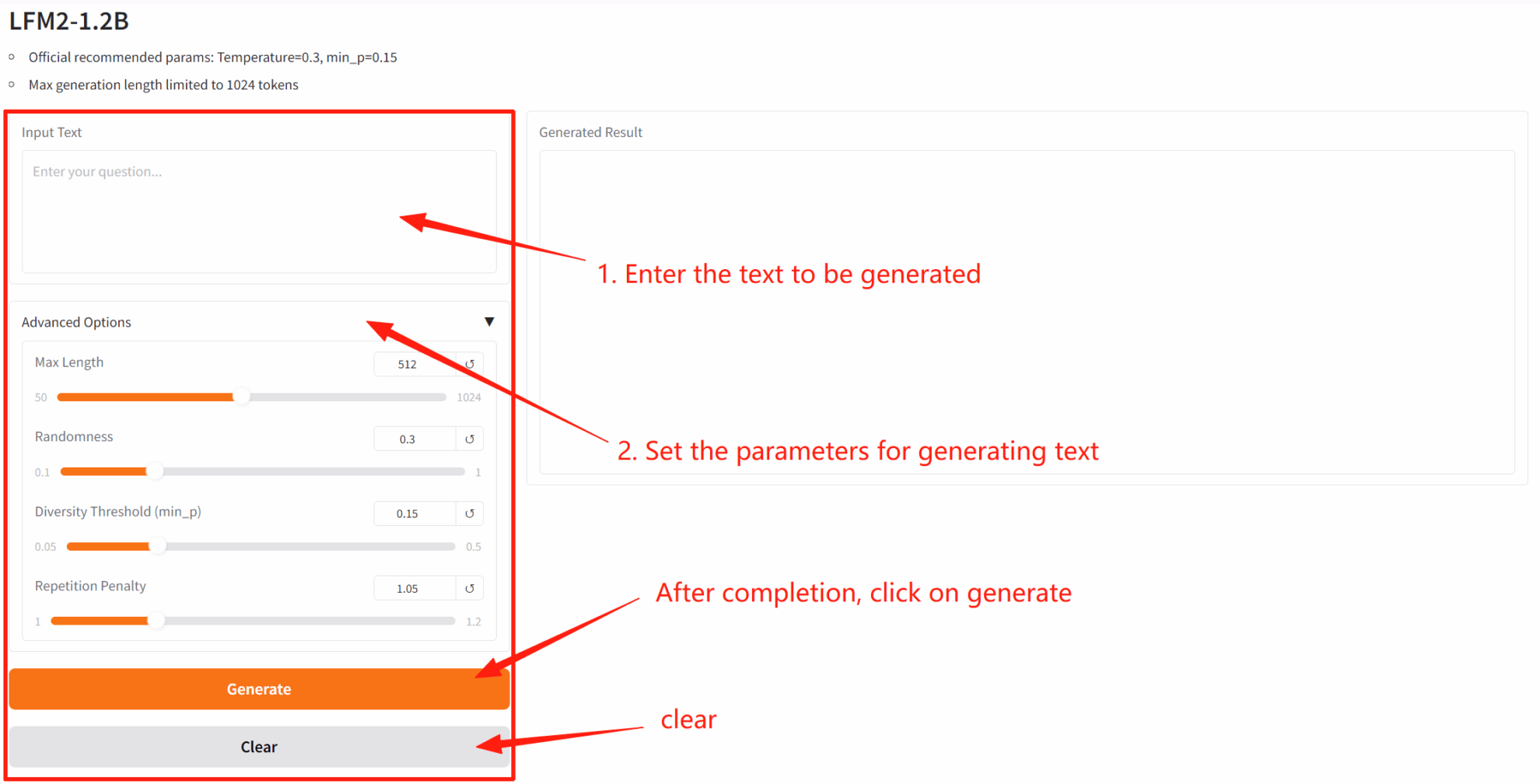
2. Après être entré sur la page Web, vous pouvez démarrer une conversation avec le modèle
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 2 à 3 minutes et actualiser la page.
4. Discussion
Si vous voyez un projet de qualité, n'hésitez pas à laisser un message pour le recommander ! Nous avons également créé un groupe d'échange de tutoriels. N'hésitez pas à scanner le code QR et à commenter [Tutoriel SD] pour rejoindre le groupe et discuter de divers problèmes techniques et partager les résultats de vos applications.

Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.