Command Palette
Search for a command to run...
Déploiement En Un Clic GLM-4.1V-9B-Thinking
Date
Taille
446.13 MB
Licence
Apache 2.0
GitHub
URL du document
1. Introduction au tutoriel

GLM-4.1V-9B-Thinking est un modèle de langage visuel open source, publié le 2 juillet 2025 par Zhipu AI en collaboration avec une équipe de l'Université Tsinghua. Conçu spécifiquement pour les tâches cognitives complexes, il prend en charge les entrées multimodales telles que les images, les vidéos et les documents. Basé sur le modèle GLM-4-9B-0414, GLM-4.1V-9B-Thinking introduit un paradigme de pensée et améliore considérablement les capacités du modèle grâce à l'échantillonnage de contenu (RLCS), atteignant ainsi les meilleures performances parmi les modèles de langage visuel à 10 milliards de paramètres. Sur 18 tâches de référence, il égale, voire surpasse, Qwen-2.5-VL-72B, qui possède huit fois plus de paramètres. Des articles de recherche associés sont disponibles. GLM-4.1V-Pensée : Vers un raisonnement multimodal polyvalent avec un apprentissage par renforcement évolutif .
Les ressources informatiques de ce tutoriel utilisent une seule carte RTX A6000. Ce tutoriel prend en charge les conversations textuelles, les images, les vidéos, ainsi que la compréhension des PDF et des PowerPoint.
2. Affichage des effets
Conversation textuelle
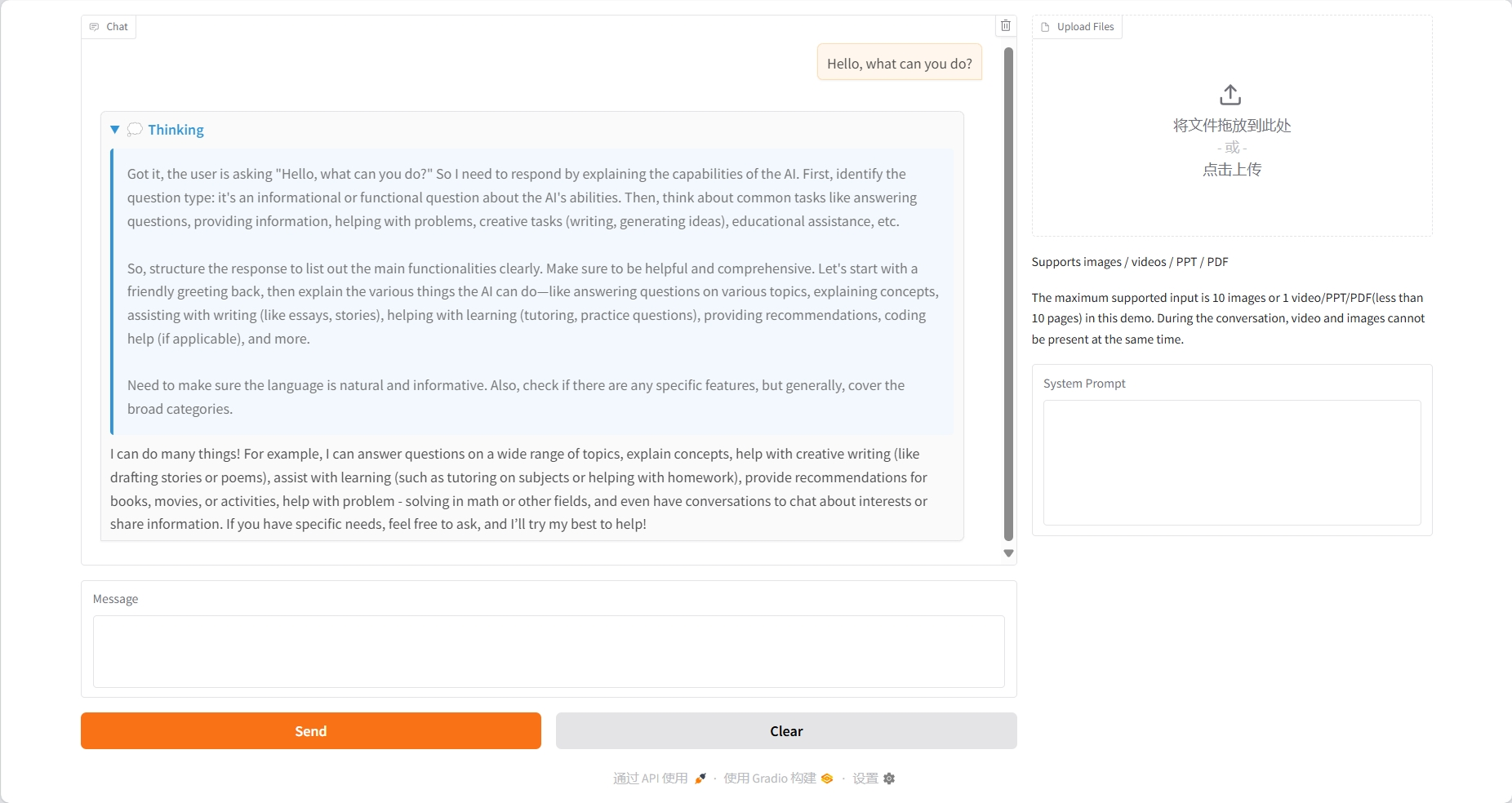
Compréhension de l'image
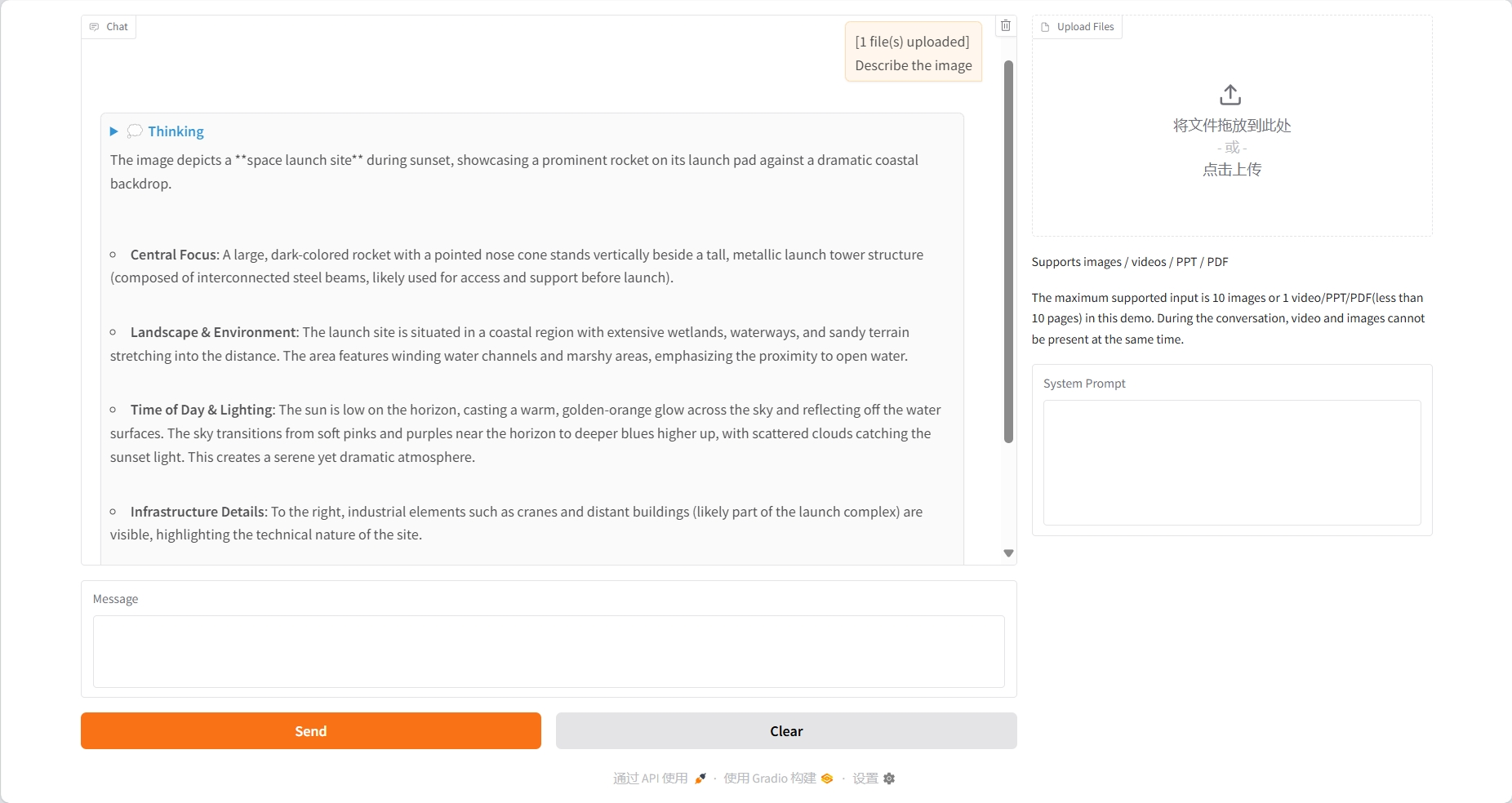
Compréhension de la vidéo
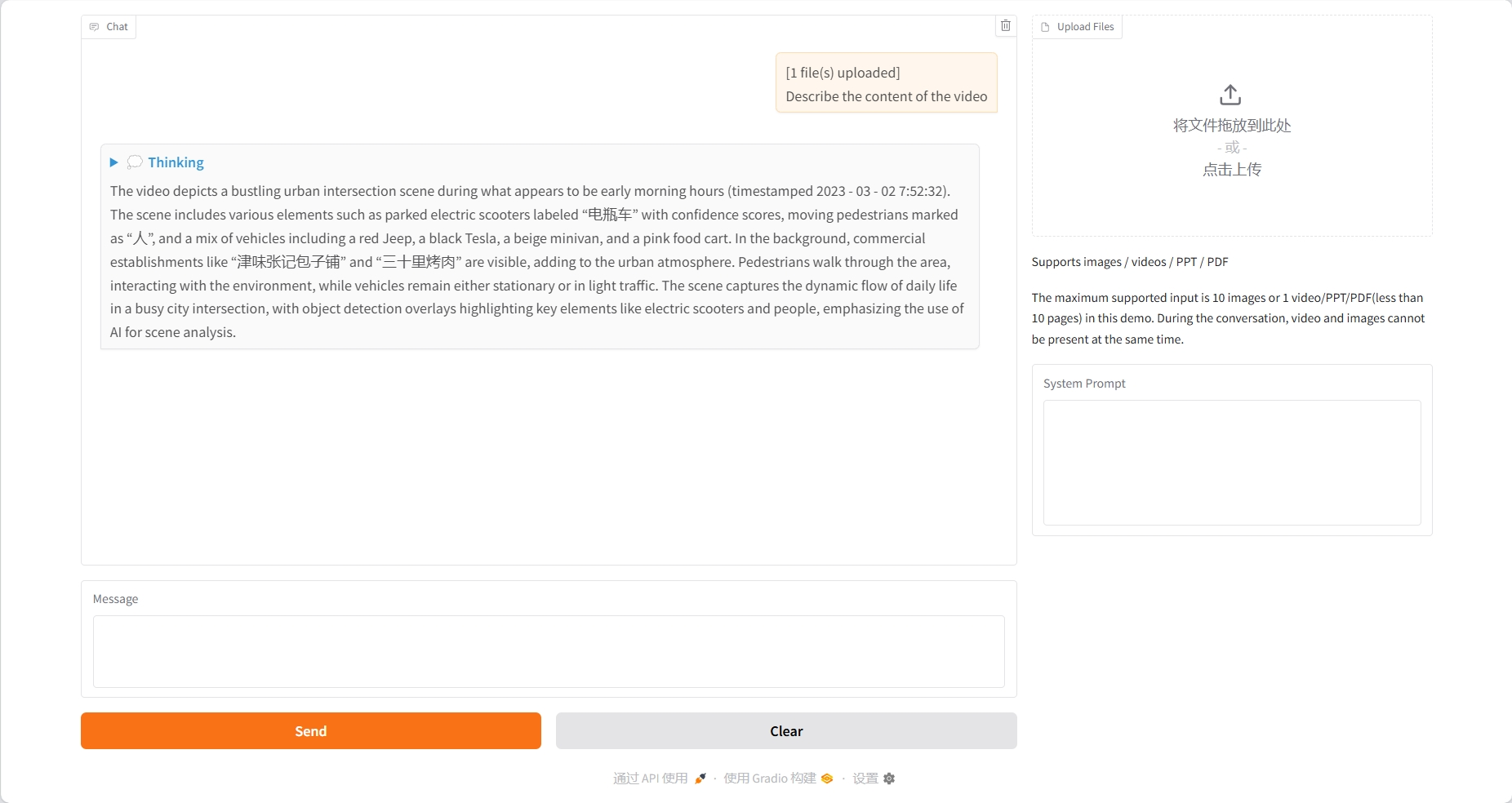
Compréhension du PDF
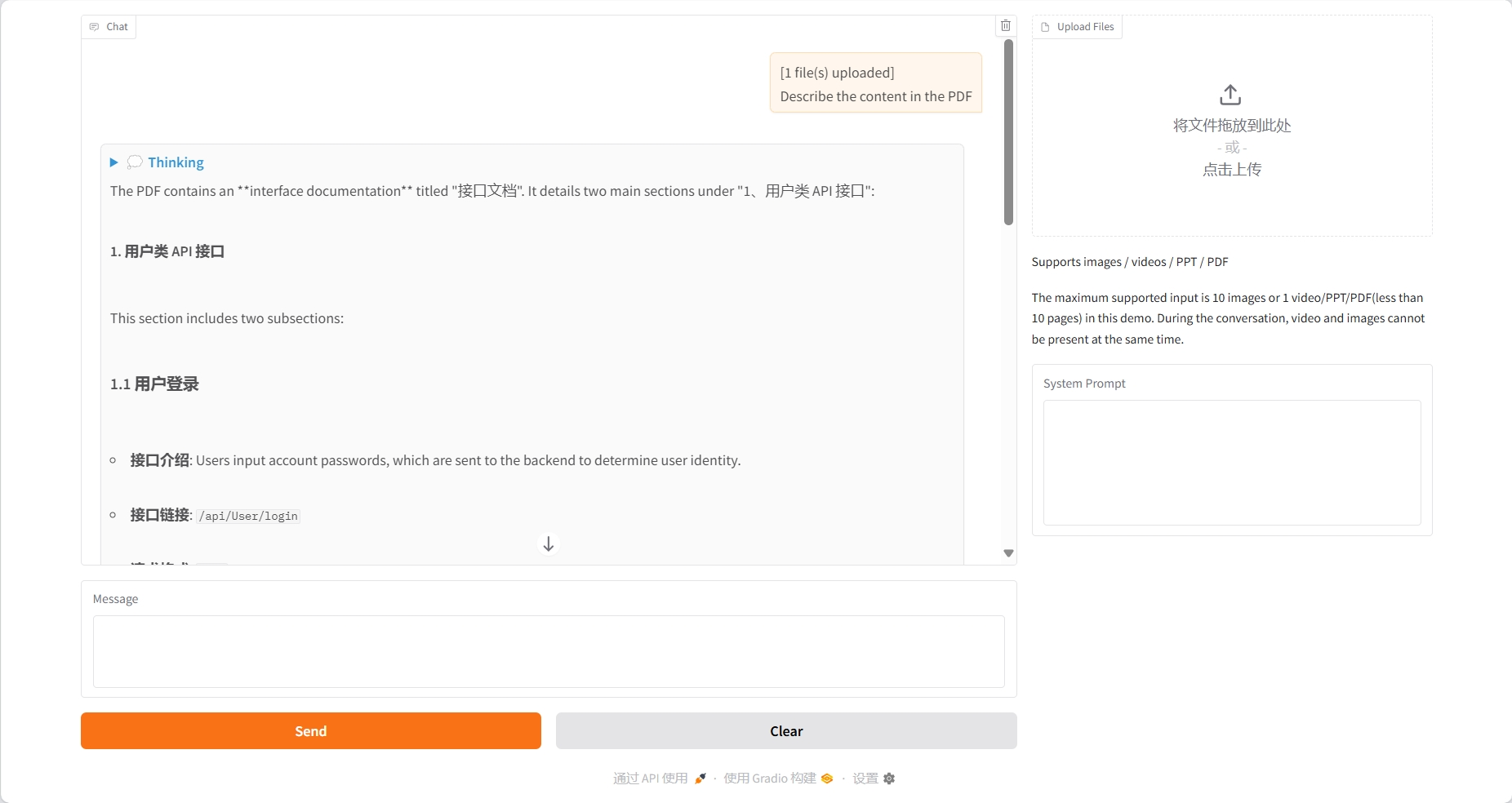
Compréhension du PPT
3. Étapes de l'opération
1. Démarrez le conteneur
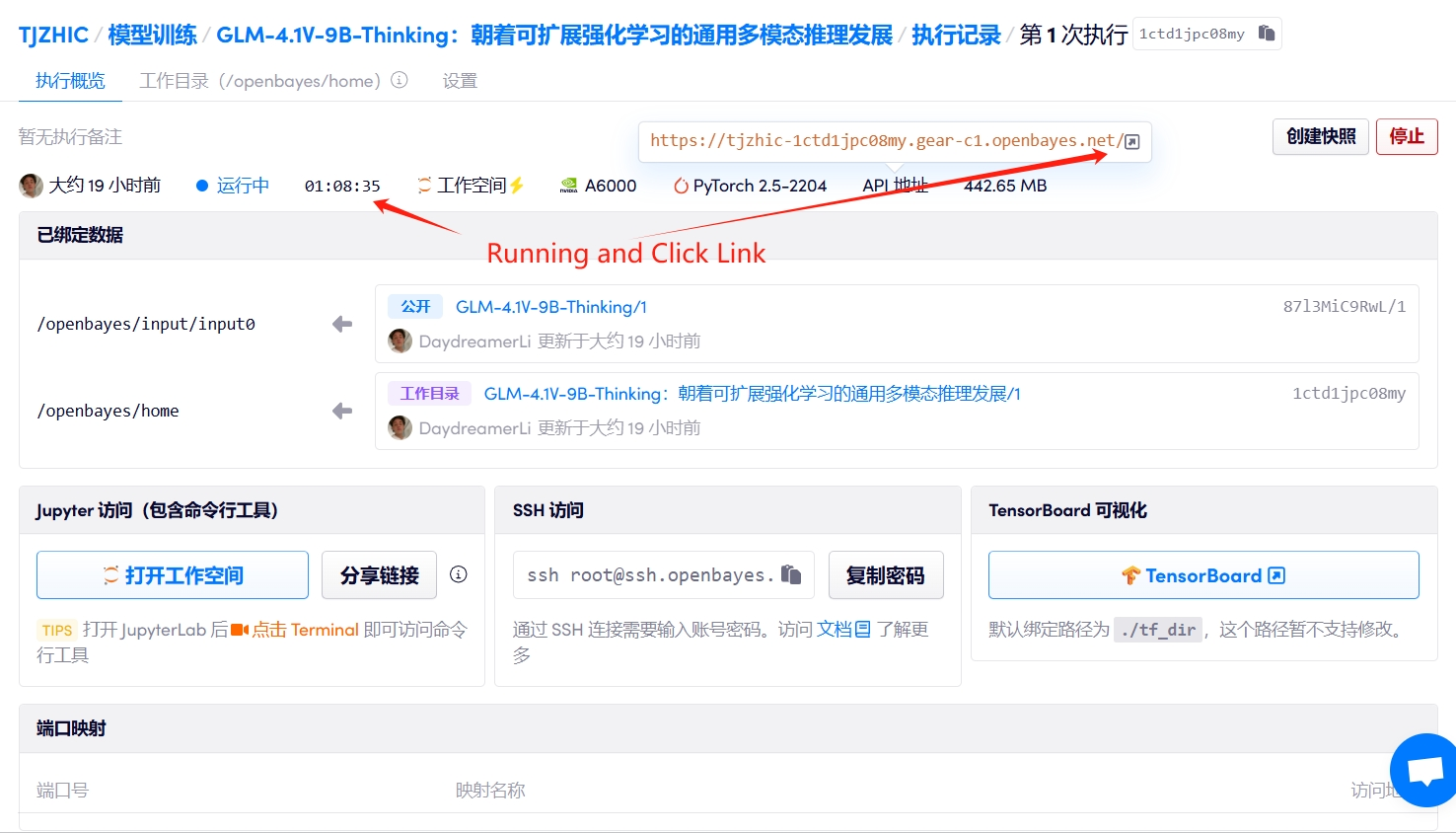
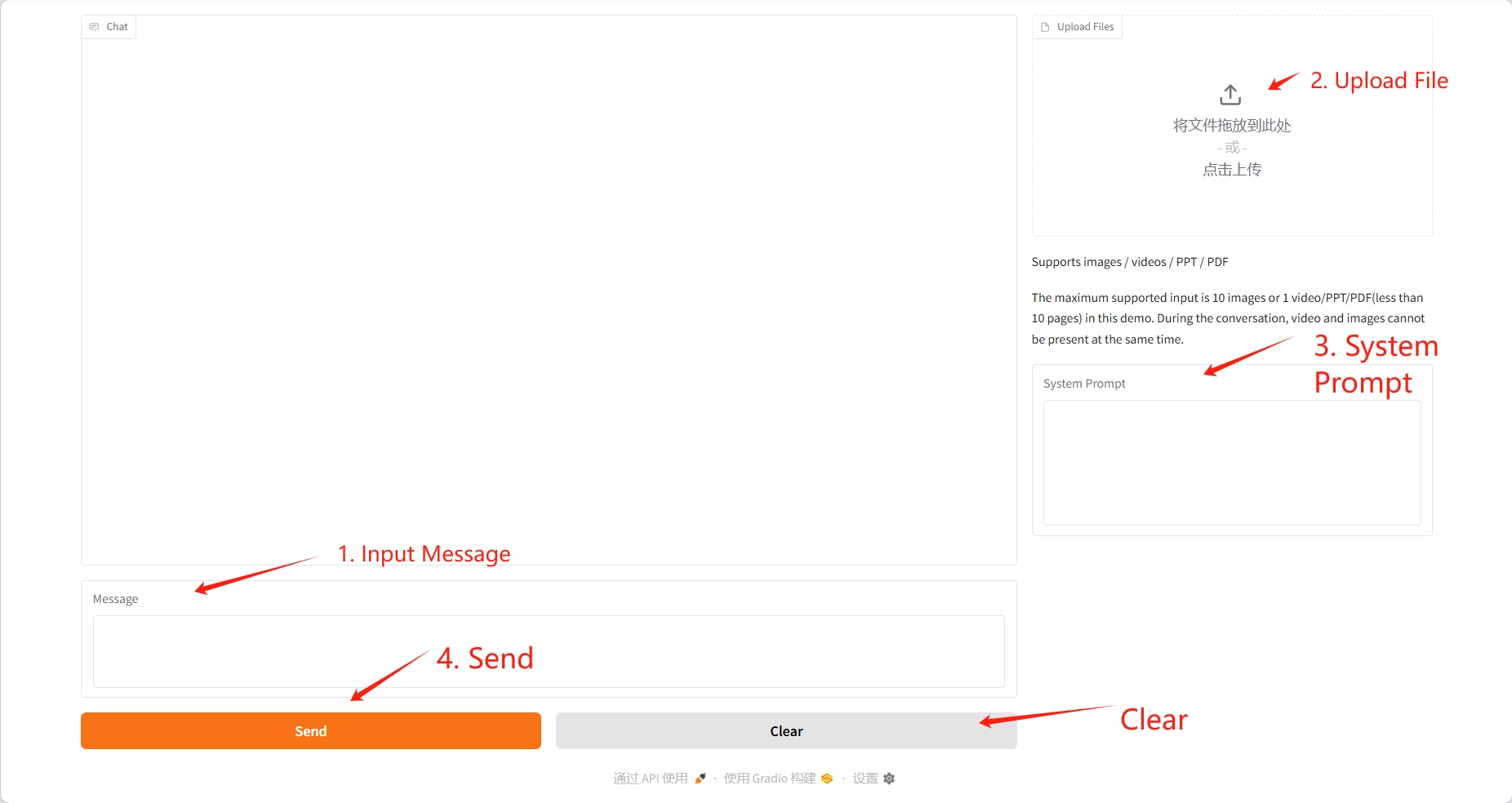
2. Étapes d'utilisation
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 2 à 3 minutes et actualiser la page.
La vidéo téléchargée ne doit pas dépasser 10 secondes, et les PDF et PowerPoint ne doivent pas dépasser 10 pages. Pendant la conversation, la vidéo et l'image ne peuvent pas être présentes simultanément. Il est recommandé de supprimer l'opération après chaque conversation.
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@misc{glmvteam2025glm41vthinkingversatilemultimodalreasoning,
title={GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning},
author={GLM-V Team and Wenyi Hong and Wenmeng Yu and Xiaotao Gu and Guo Wang and Guobing Gan and Haomiao Tang and Jiale Cheng and Ji Qi and Junhui Ji and Lihang Pan and Shuaiqi Duan and Weihan Wang and Yan Wang and Yean Cheng and Zehai He and Zhe Su and Zhen Yang and Ziyang Pan and Aohan Zeng and Baoxu Wang and Boyan Shi and Changyu Pang and Chenhui Zhang and Da Yin and Fan Yang and Guoqing Chen and Jiazheng Xu and Jiali Chen and Jing Chen and Jinhao Chen and Jinghao Lin and Jinjiang Wang and Junjie Chen and Leqi Lei and Letian Gong and Leyi Pan and Mingzhi Zhang and Qinkai Zheng and Sheng Yang and Shi Zhong and Shiyu Huang and Shuyuan Zhao and Siyan Xue and Shangqin Tu and Shengbiao Meng and Tianshu Zhang and Tianwei Luo and Tianxiang Hao and Wenkai Li and Wei Jia and Xin Lyu and Xuancheng Huang and Yanling Wang and Yadong Xue and Yanfeng Wang and Yifan An and Yifan Du and Yiming Shi and Yiheng Huang and Yilin Niu and Yuan Wang and Yuanchang Yue and Yuchen Li and Yutao Zhang and Yuxuan Zhang and Zhanxiao Du and Zhenyu Hou and Zhao Xue and Zhengxiao Du and Zihan Wang and Peng Zhang and Debing Liu and Bin Xu and Juanzi Li and Minlie Huang and Yuxiao Dong and Jie Tang},
year={2025},
eprint={2507.01006},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.01006},
}Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.