Command Palette
Search for a command to run...
PlayDiffusion : Modèle d'édition Audio Local Open Source
Date
Taille
1.35 MB
Balises
Licence
Apache 2.0
GitHub
URL du document
1. Introduction au tutoriel

Caractéristiques principales :
- Édition audio partielle : prend en charge le remplacement partiel, la modification ou la suppression de l'audio sans régénérer l'intégralité du segment audio, gardant la voix naturelle et fluide.
- TTS efficace : lors du masquage de l'intégralité de l'audio, en tant que modèle TTS efficace, la vitesse d'inférence est 50 fois plus rapide que le TTS traditionnel, et le naturel et la cohérence de la parole sont meilleurs.
- Maintenir la continuité de la parole : Préservez le contexte lors de l'édition pour garantir la continuité de la parole et la cohérence du timbre du locuteur.
- Modification dynamique de la voix : ajustez automatiquement la prononciation, le ton et le rythme de la voix en fonction du nouveau texte, adapté aux scénarios tels que l'interaction en temps réel.
Principe technique :
- Codage audio : encode la séquence audio d'entrée en une séquence discrète de jetons, chaque jeton représentant une unité audio. Applicable à la parole réelle et à l'audio généré par des modèles de synthèse vocale.
- Traitement de masque : lorsqu'une partie de l'audio doit être modifiée, marquez la partie comme masque pour faciliter le traitement ultérieur.
- Débruitage par modèle de diffusion : Débruitage de la zone masquée grâce à un modèle de diffusion qui actualise le texte. Ce modèle génère une séquence de jetons audio de haute qualité grâce à une suppression progressive du bruit. Tous les jetons sont générés simultanément selon une méthode non autorégressive et affinés selon un nombre fixe d'étapes de débruitage.
- Décodage en forme d'onde audio : la séquence de jetons générée est reconvertie en forme d'onde vocale basée sur le modèle de décodeur BigVGAN pour garantir que la parole de sortie finale est naturelle et cohérente.
Ce tutoriel utilise une seule ressource de calcul RTX A6000 et fournit trois exemples de test : Inpaint, Synthèse vocale et Conversion vocale. Ce tutoriel est disponible uniquement en anglais.
2. Affichage des effets
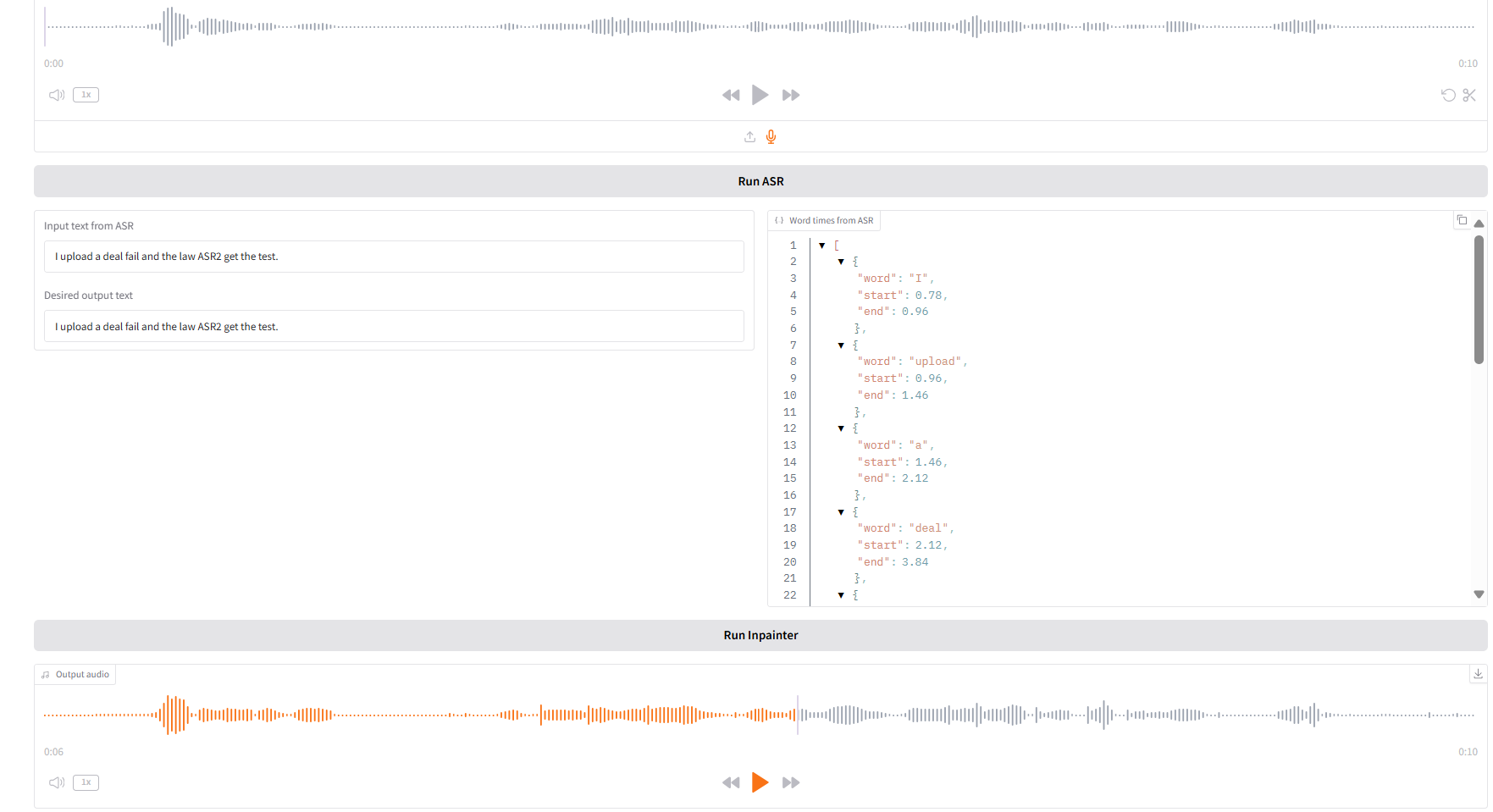
1. Inpaint
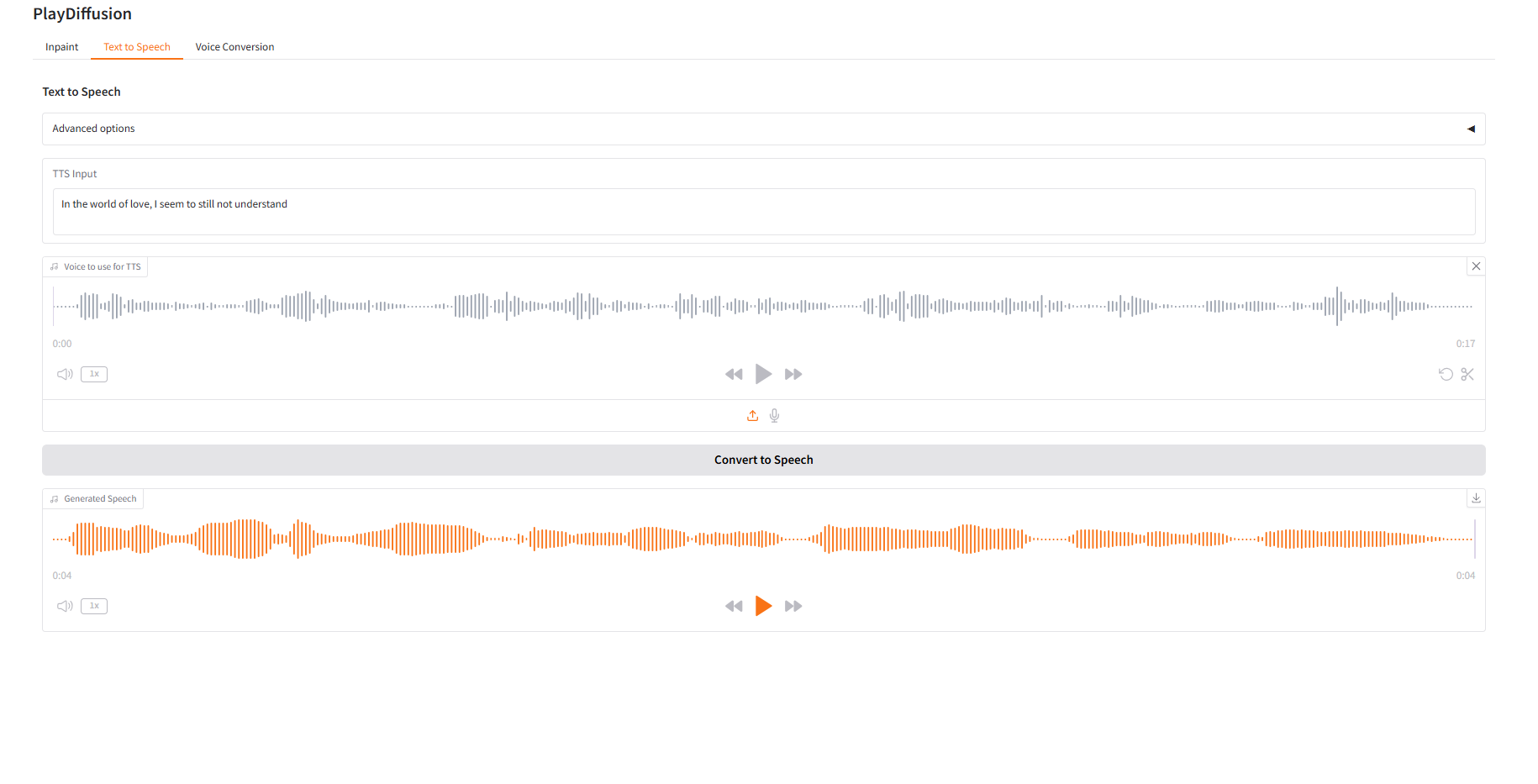
2. Synthèse vocale
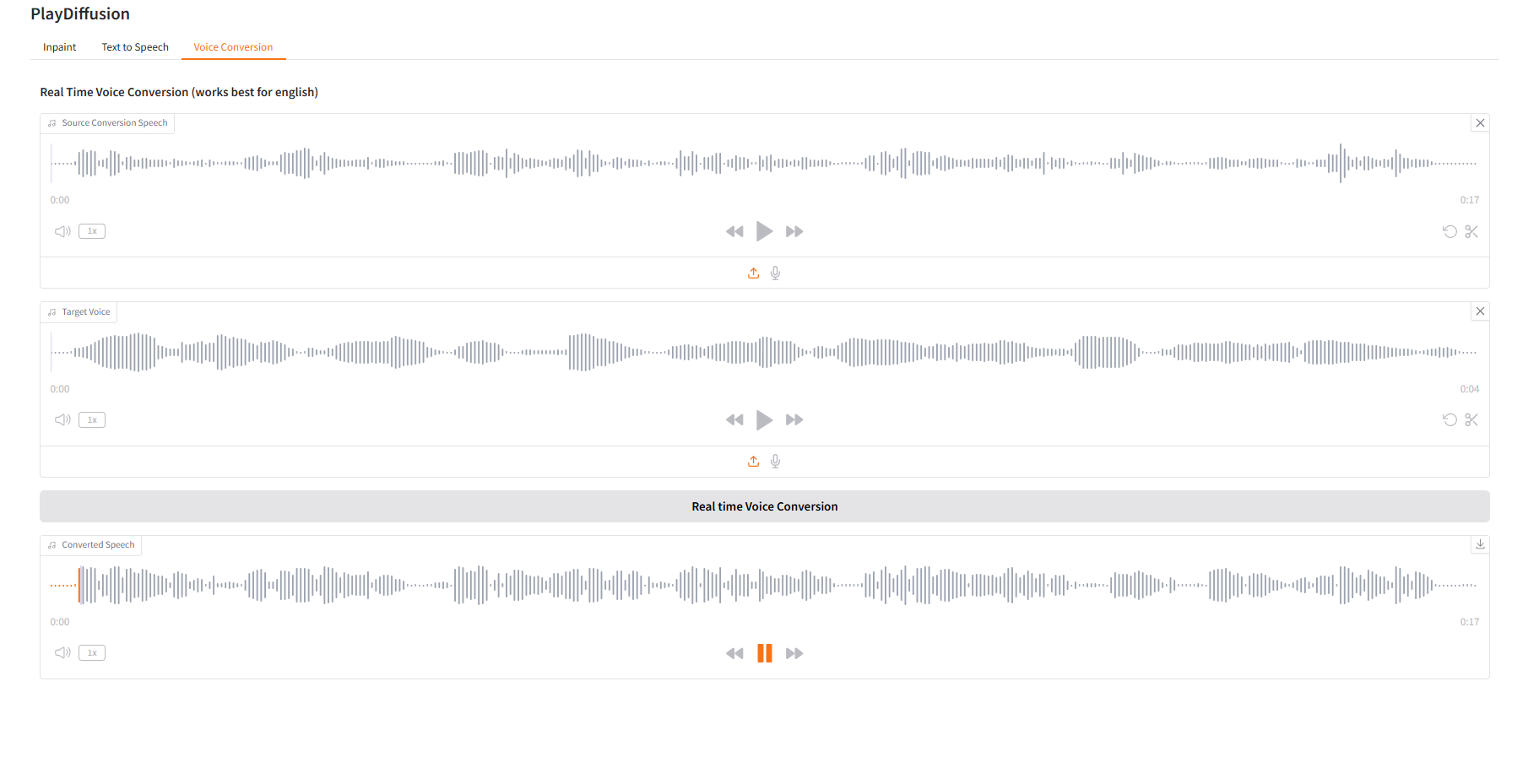
3. Conversion vocale
3. Étapes de l'opération
1. Démarrez le conteneur
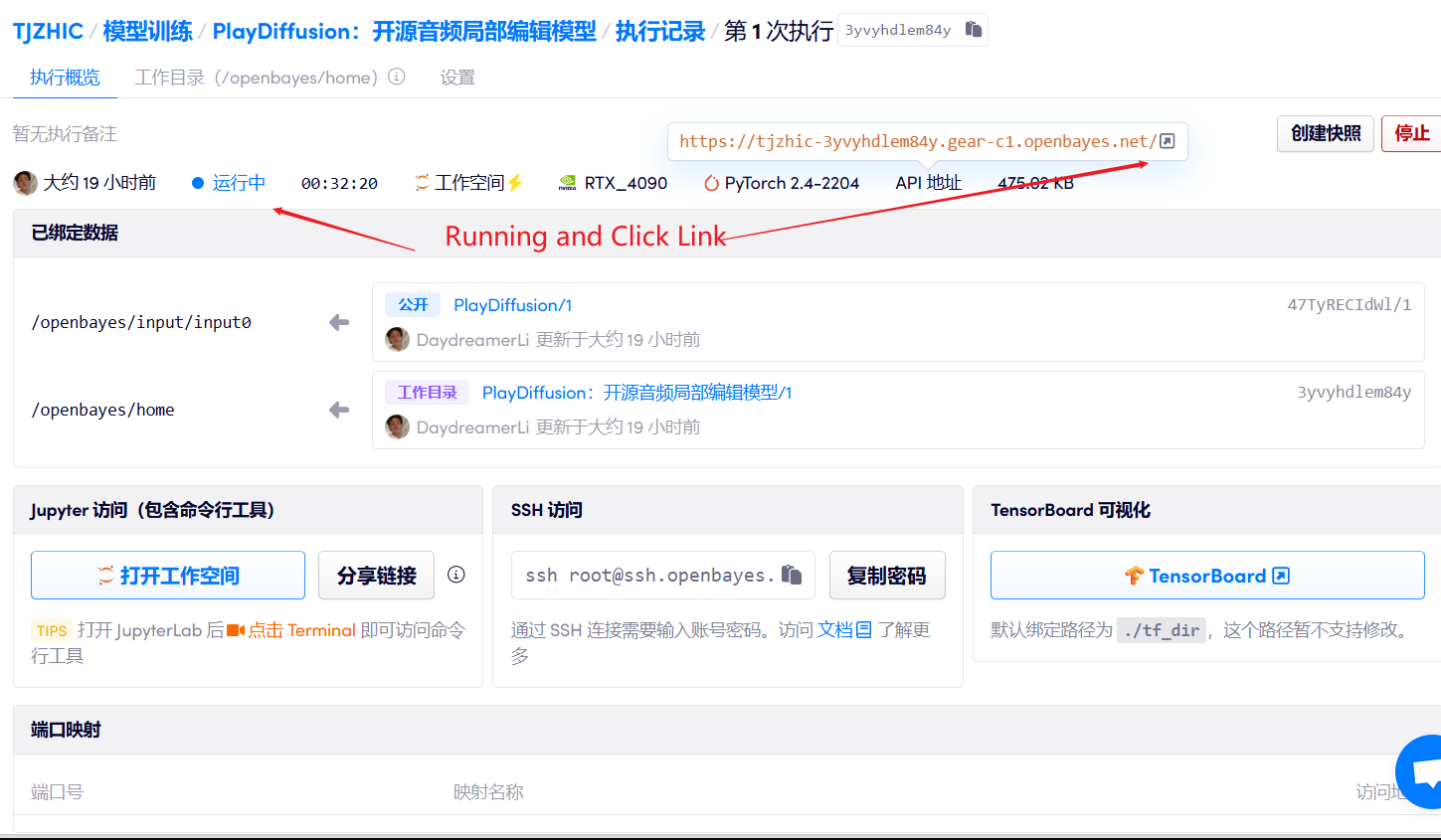
2. Étapes d'utilisation
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 2 à 3 minutes et actualiser la page.
Lorsque vous utilisez le navigateur Safari, l'audio peut ne pas être lu directement et doit être téléchargé avant la lecture.
1. Inpaint
Ce module peut remplacer, modifier ou supprimer partiellement l'audio sans régénérer l'intégralité de l'audio, gardant ainsi la parole naturelle et fluide.
- Téléchargez l'audio d'origine, cliquez sur « Exécuter SAR » pour l'exécuter, puis modifiez et éditez le contenu audio que vous souhaitez générer dans « Texte de sortie souhaité ».
- Cliquez ensuite sur « Exécuter Inpainter » pour générer l’audio édité.
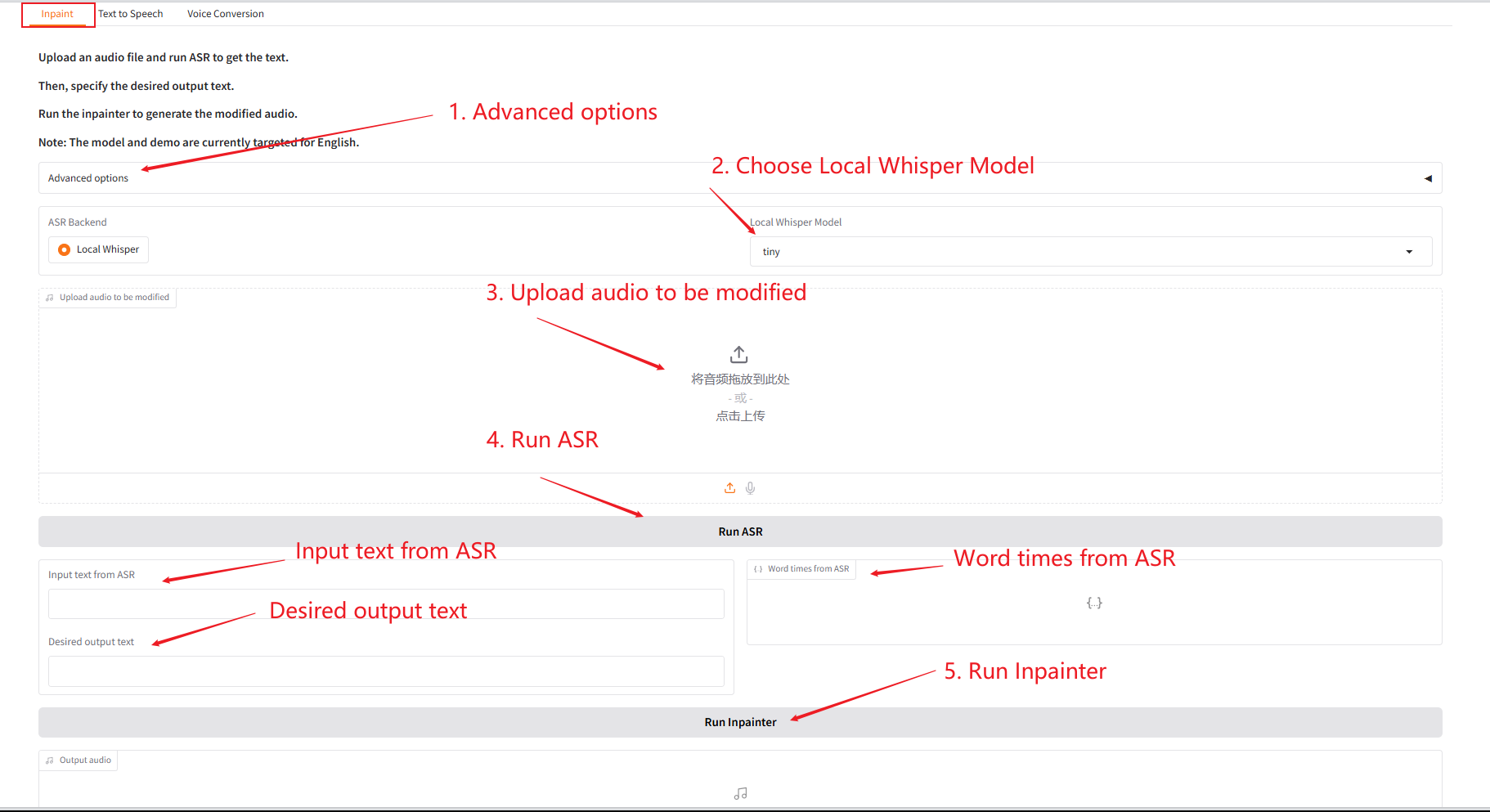
Description des paramètres :
- Nombre d'étapes d'échantillonnage : nombre d'itérations dans le processus de génération du modèle de diffusion. Plus le nombre d'étapes est élevé, meilleure est la qualité de la génération, mais plus le temps est long.
- Livre de codes : un dictionnaire de symboles discrets dans la couche de quantification vectorielle, utilisé pour mapper des caractéristiques continues dans des représentations discrètes.
- Température initiale : paramètre qui contrôle le caractère aléatoire de l'échantillonnage. Plus la valeur est élevée, plus la diversité est grande, et plus la valeur est faible, plus le résultat est fiable.
- Diversité initiale : Paramètres qui contrôlent le degré de variation dans les échantillons générés pour éviter de générer des résultats trop similaires.
- Guidage : ajuste le degré d'influence des informations conditionnelles (telles que le texte) sur les résultats générés.
- Facteur de redimensionnement des directives : rapport de pondération utilisé pour équilibrer les directives conditionnelles et la génération inconditionnelle.
- Échantillonnage à partir des logits top-k : sélectionnez uniquement parmi les K candidats ayant la plus grande probabilité d'améliorer la qualité de la génération.
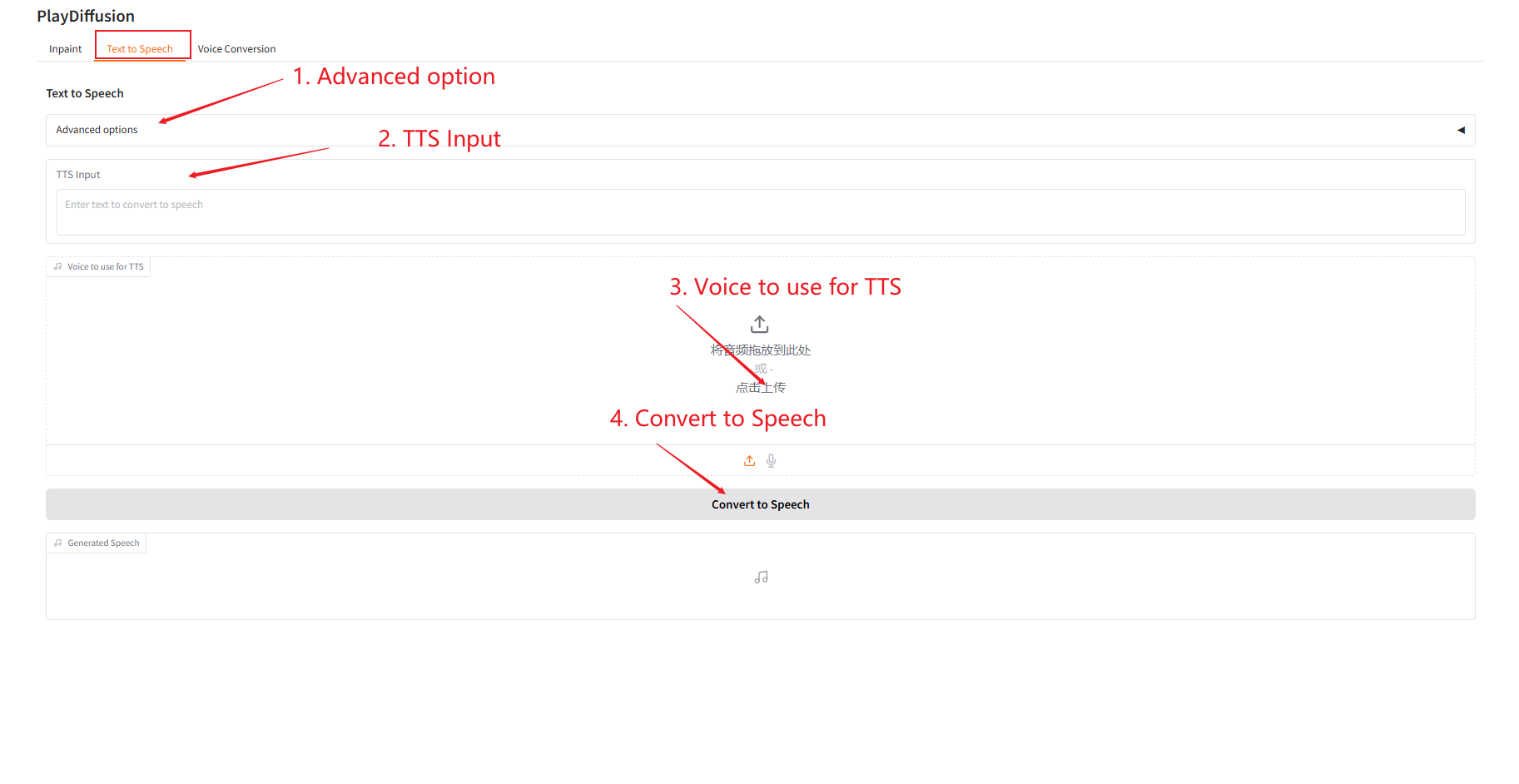
2. Synthèse vocale
En tant que modèle TTS efficace, sa vitesse d'inférence est 50 fois plus rapide que celle du TTS traditionnel, et son naturel et sa cohérence de parole sont meilleurs.
- Saisissez le contenu texte pour lequel vous souhaitez générer de l'audio dans « Entrée TTS », puis téléchargez l'audio cible.
- Cliquez ensuite sur « Convertir en parole » pour générer l’audio.
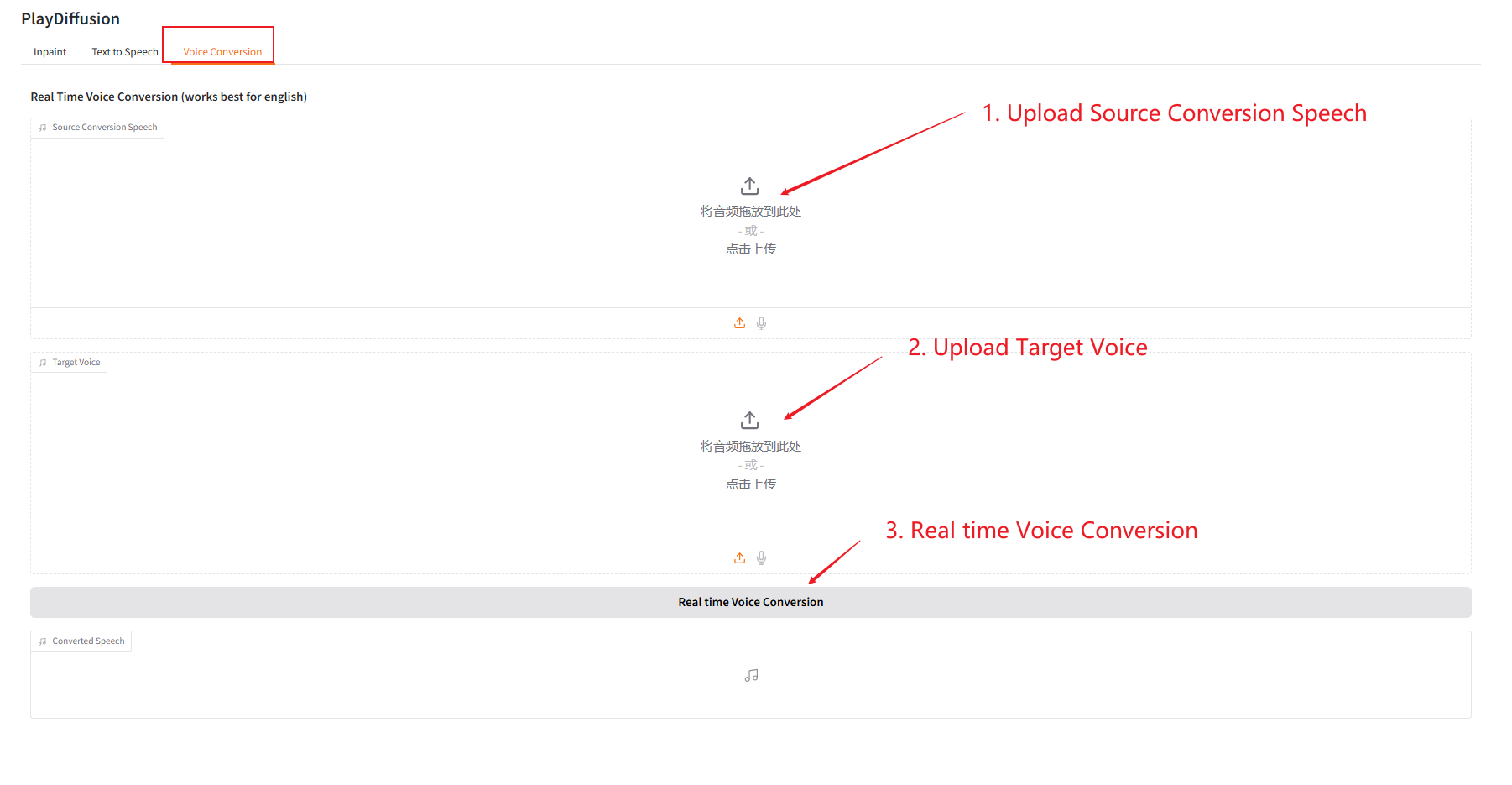
3. Conversion vocale
Ajustez dynamiquement le contenu de la voix et vous pouvez cloner directement le contenu audio d'origine sur le timbre cible.
- Téléchargez l'audio d'origine, puis téléchargez l'audio cible.
- Cliquez ensuite sur « Conversion vocale en temps réel » pour générer directement le contenu audio d'origine de la tonalité cible.
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.