Command Palette
Search for a command to run...
Déploiement vLLM+Open WebUI KernelLLM-8B
1. Introduction au tutoriel
Les ressources informatiques utilisées dans ce tutoriel sont une seule carte RTX 4090.
KernelLLM est un modèle de langage complet conçu pour le développement de noyaux GPU, lancé par Meta AI. Il vise à traduire automatiquement les modules PyTorch en code noyau Triton performant, simplifiant et accélérant ainsi le processus de programmation GPU haute performance. Ce modèle est basé sur l'architecture Llama 3.1 Instruct, comporte 8 milliards de paramètres et se concentre sur la génération d'implémentations de noyaux Triton performantes.
2. Exemples de projets
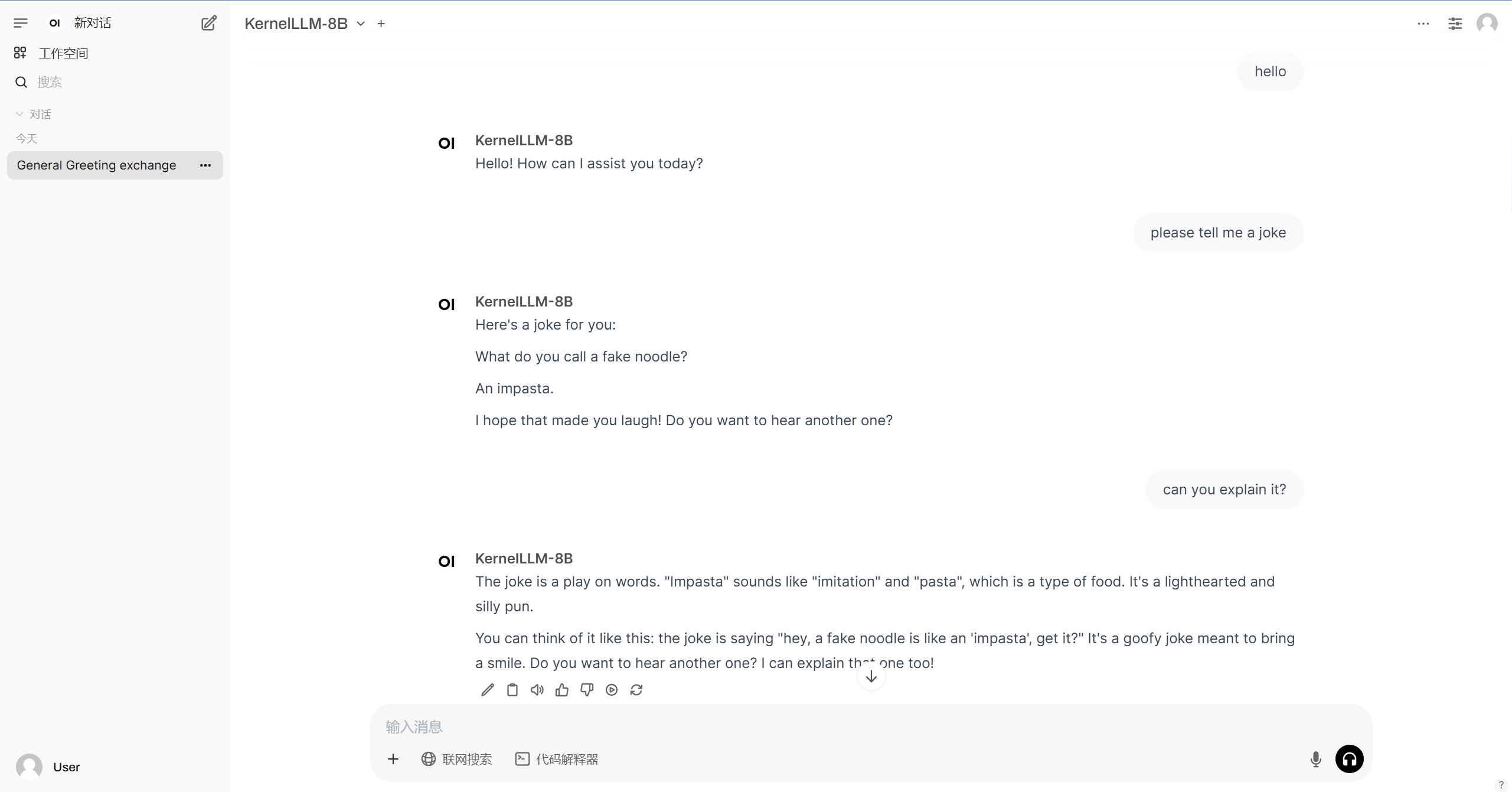
3. Étapes de l'opération
1. Démarrez le conteneur
Si « Modèle » n'est pas affiché, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 2 à 3 minutes et actualiser la page.
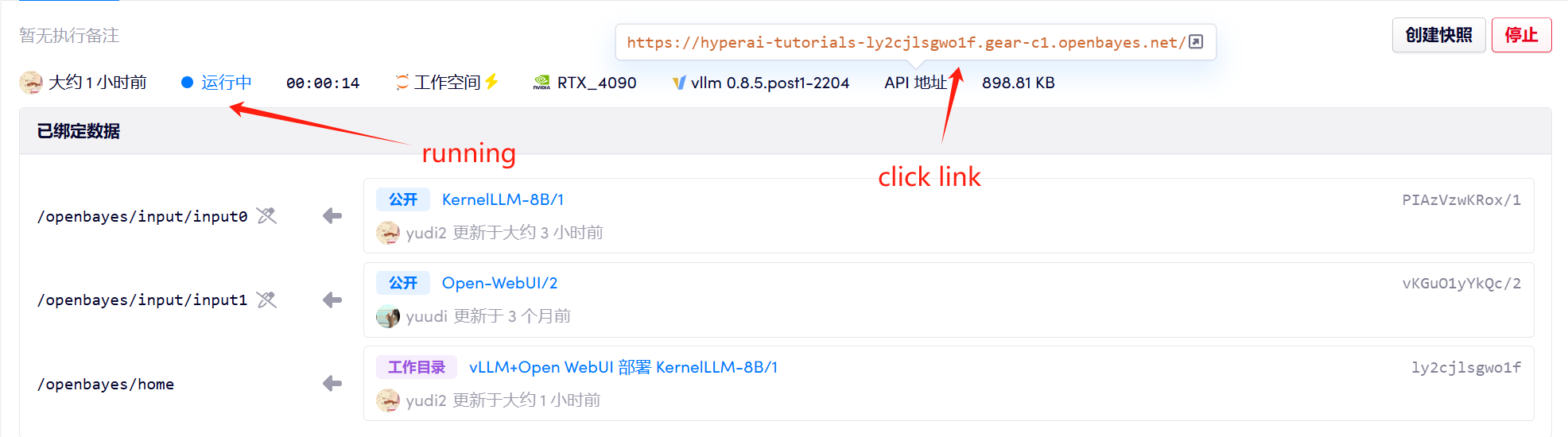
2. Après être entré sur la page Web, vous pouvez démarrer une conversation avec le modèle
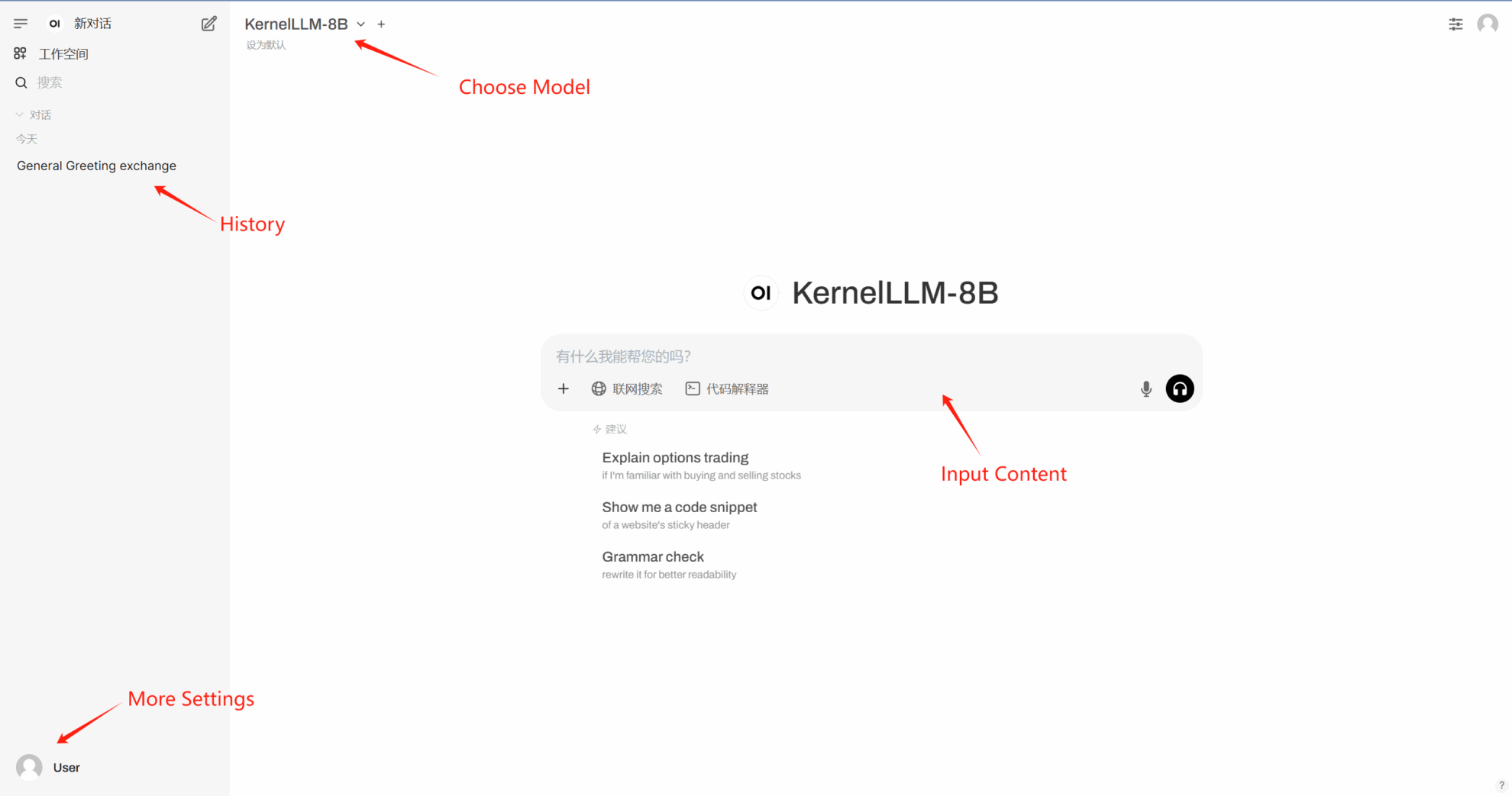
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.