Command Palette
Search for a command to run...
Sa2VA : Vers Une Compréhension Perceptive Dense Des Images Et Des Vidéos
Date
Taille
465.62 MB
Licence
Apache 2.0
GitHub
URL du document
1. Introduction au tutoriel

Sa2VA, développé conjointement par des équipes de recherche de l'UC Merced, de ByteDance Seed, de l'Université de Wuhan et de l'Université de Pékin, a été lancé le 7 janvier 2025. Sa2VA est le premier modèle unifié pour la compréhension perceptive dense d'images et de vidéos. Contrairement aux modèles de langage multimodaux à grande échelle existants, généralement limités à des modalités et des tâches spécifiques, Sa2VA prend en charge un large éventail de tâches d'images et de vidéos, notamment la segmentation algébrique et le dialogue, nécessitant un minimum d'ajustements au niveau de chaque instruction. Les résultats des articles associés sont les suivants : Sa2VA : Associer SAM2 et LLaVA pour une compréhension dense et ancrée des images et des vidéos .
Ce tutoriel utilise des ressources pour une seule carte A6000.
2. Exemples de projets



3. Étapes de l'opération
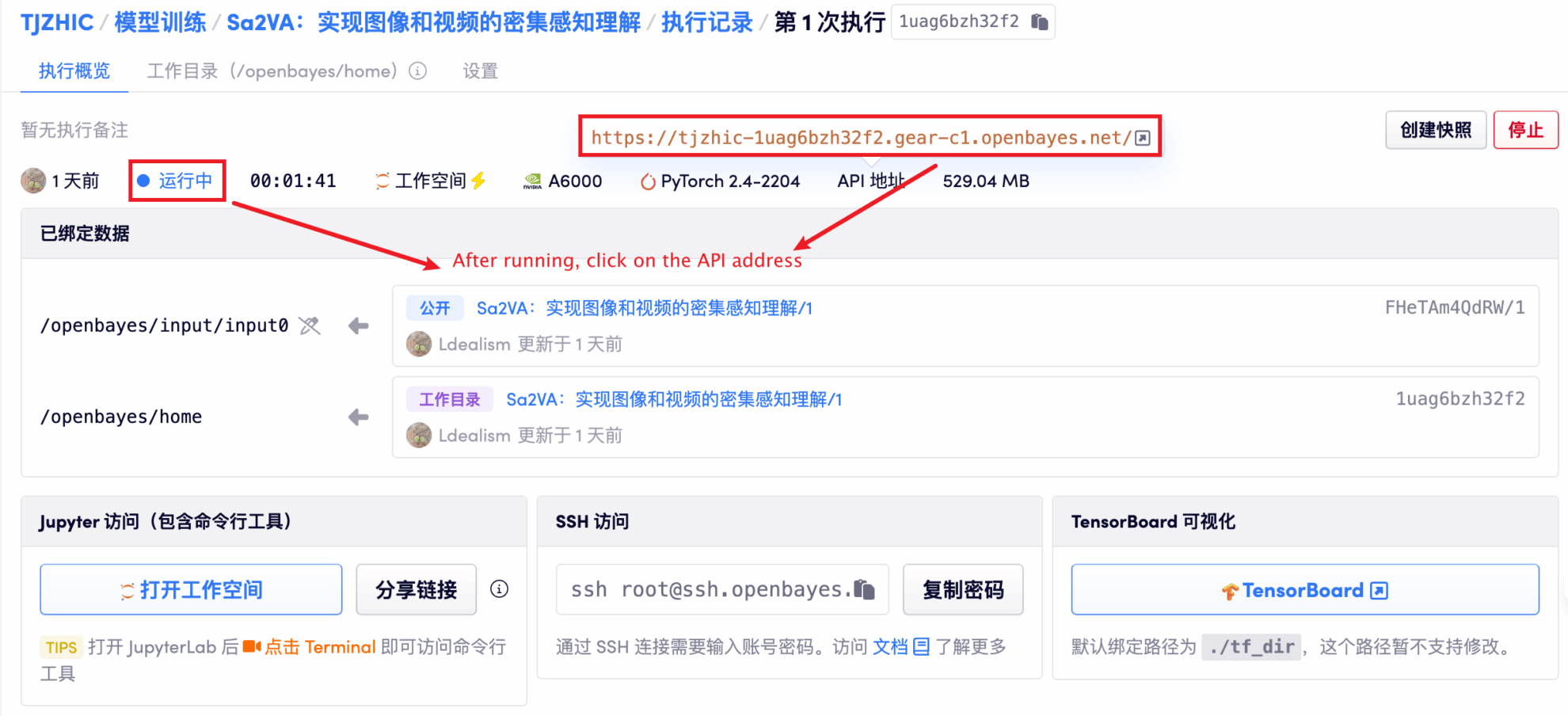
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 1 à 2 minutes et actualiser la page.
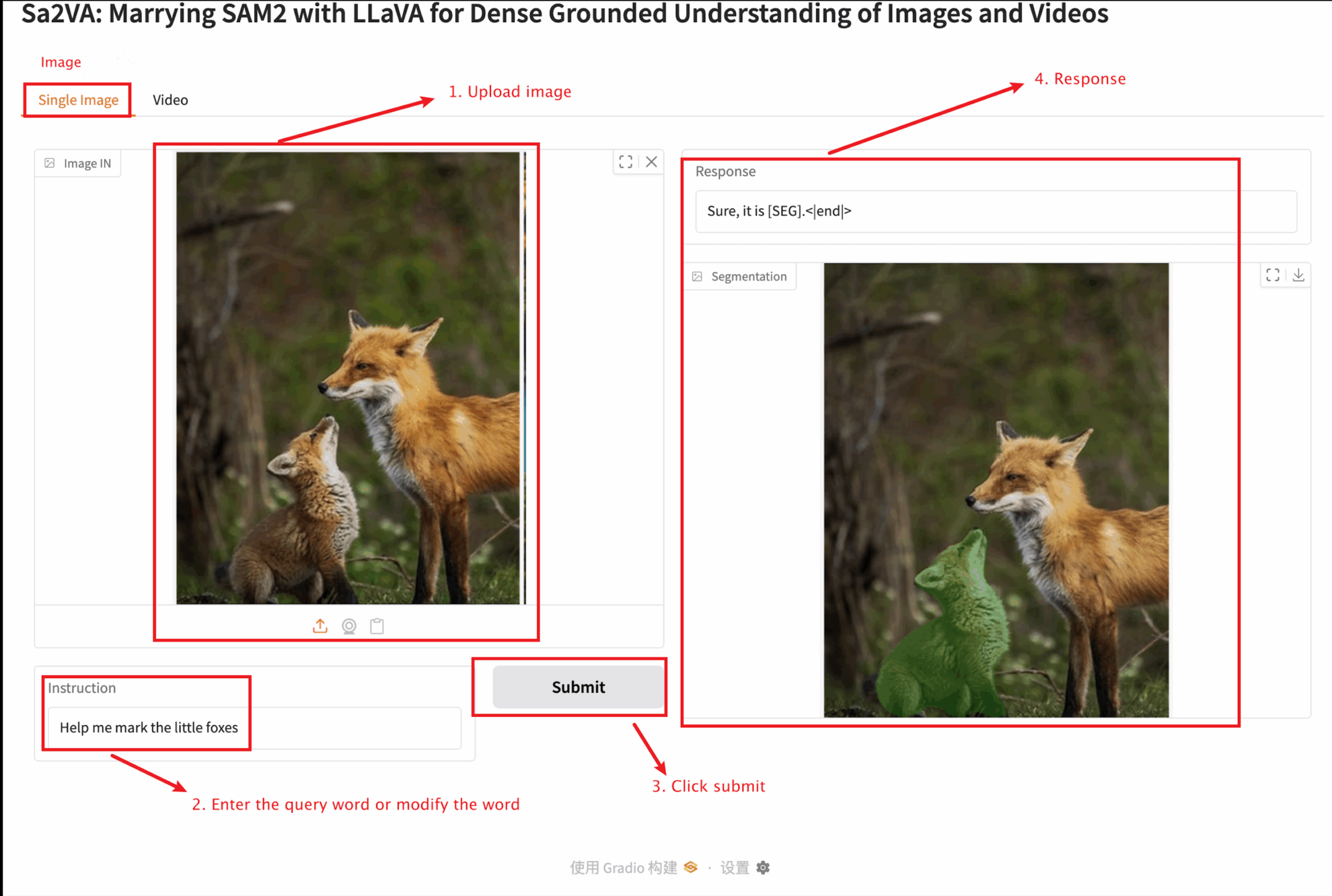
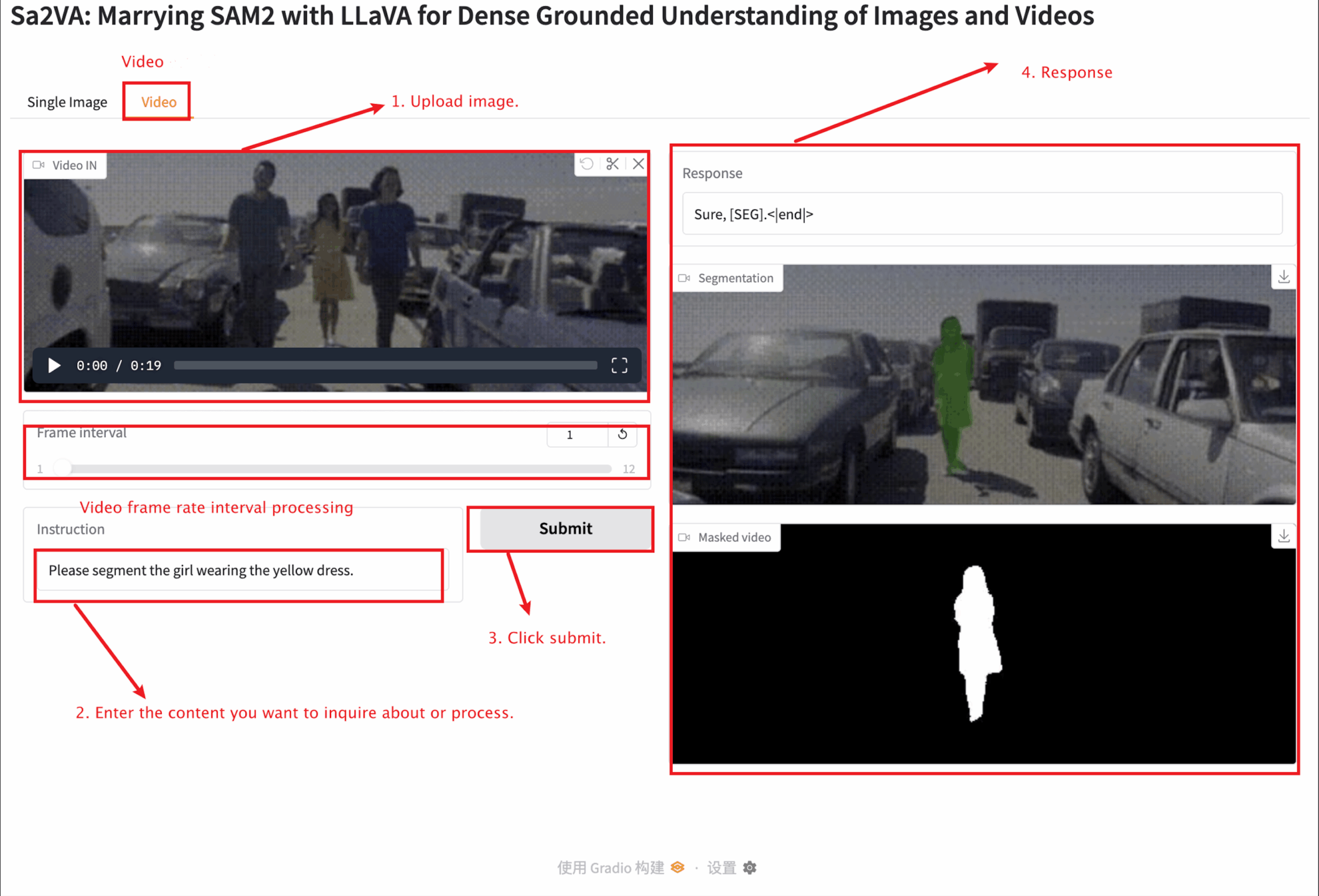
2. Une fois que vous entrez sur la page Web, vous pouvez interagir avec le modèle
Ce tutoriel propose deux tests de modules : des modules d'image unique et de vidéo.
La taille de l'image téléchargée ne doit pas dépasser 10 Mo, la durée de la vidéo téléchargée ne doit pas dépasser 1 minute et la taille de la vidéo ne doit pas dépasser 50 Mo, sinon cela peut entraîner un ralentissement du modèle ou signaler des erreurs.
Description des paramètres importants :
Image unique
Vidéo
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

V. Informations sur la citation
Merci à l'utilisateur Github zhangjunchang Pour le déploiement de ce tutoriel, les informations de référence du projet sont les suivantes :
@article{pixel_sail,
title={Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos},
author={Zhang, Tao and Li, Xiangtai and Huang, Zilong and Li, Yanwei and Lei, Weixian and Deng, Xueqing and Chen, Shihao and Ji, Shunping and and Feng, Jiashi},
journal={arXiv},
year={2025}
}
@article{sa2va,
title={Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos},
author={Yuan, Haobo and Li, Xiangtai and Zhang, Tao and Huang, Zilong and Xu, Shilin and Ji, Shunping and Tong, Yunhai and Qi, Lu and Feng, Jiashi and Yang, Ming-Hsuan},
journal={arXiv},
year={2025}
}Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.