Command Palette
Search for a command to run...
Déploiement vLLM+Open WebUI MiniCPM4-8B
Date
Taille
1.86 MB
Balises
Licence
Apache 2.0
GitHub
URL du document
1. Introduction au tutoriel

MiniCPM 4.0, lancé par OpenBMB le 6 juin 2025, est un modèle de langage étendu (LLM) haute performance pour le traitement en périphérie. Grâce à une architecture creuse, une compression par quantification et un cadre d'inférence efficace, il offre des performances d'inférence élevées à faible coût de calcul, ce qui le rend particulièrement adapté au traitement de textes longs, aux scénarios sensibles à la confidentialité et au déploiement sur des dispositifs de calcul en périphérie. MiniCPM4-8B présente une vitesse de traitement nettement supérieure à celle de Qwen3-8B pour les séquences longues. Des articles de recherche associés sont disponibles. MiniCPM4 : des LLM ultra-efficaces sur les terminaux .
Ce tutoriel utilise des ressources pour une seule carte RTX 4090.
2. Exemples de projets
3. Étapes de l'opération
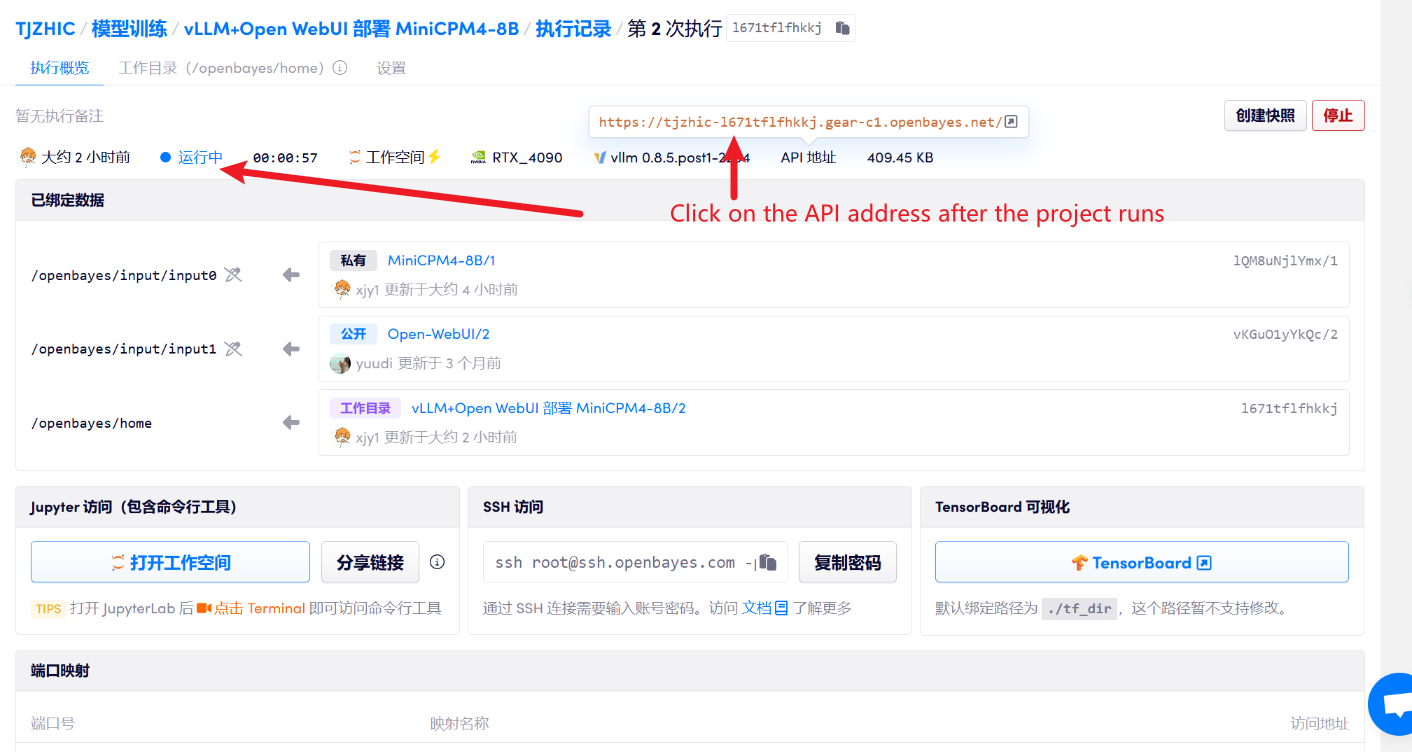
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
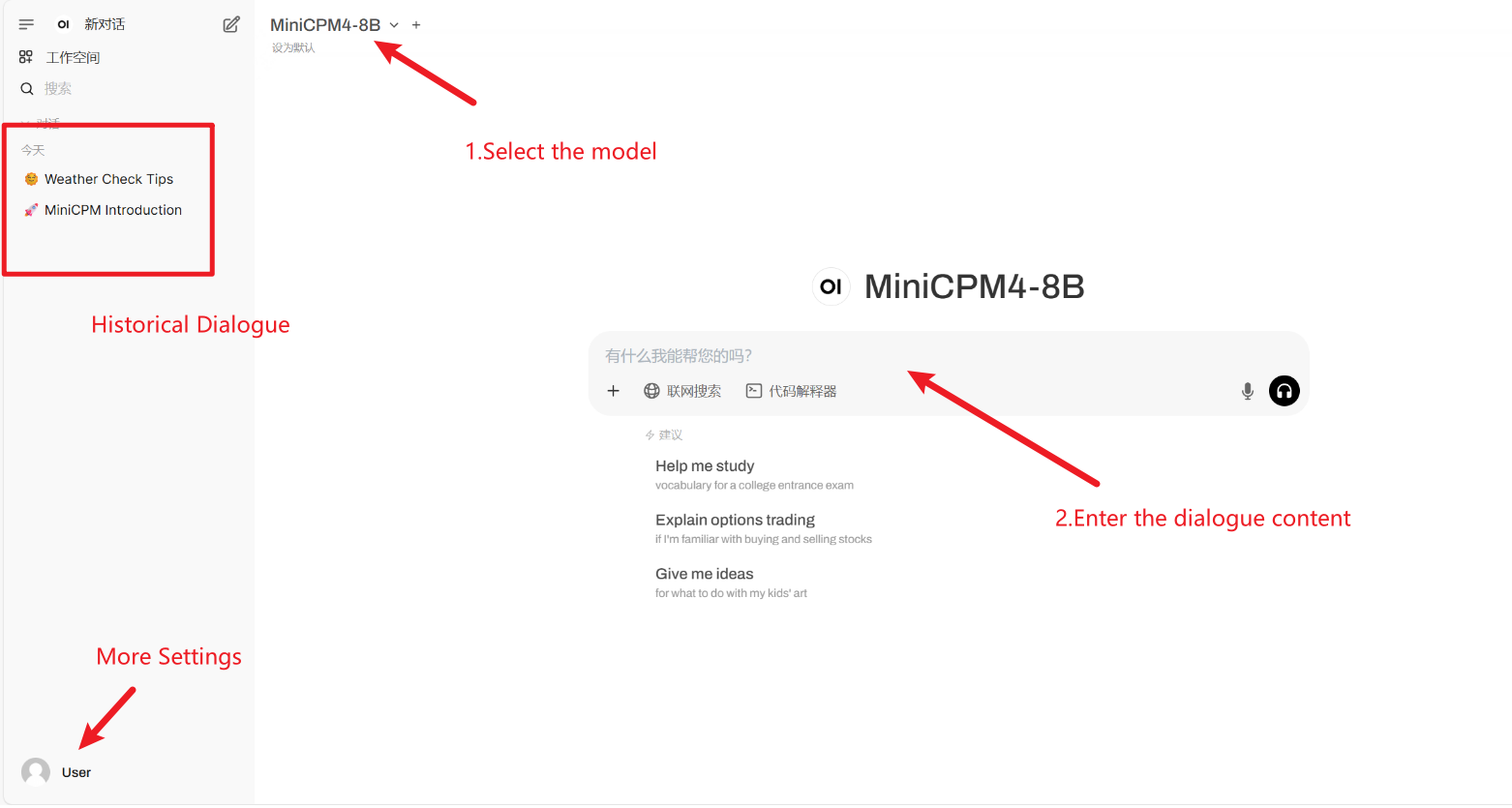
2. Après être entré sur la page Web, vous pouvez démarrer une conversation avec le modèle
Si « Modèle » n'est pas affiché, cela signifie que le modèle est en cours d'initialisation. Le modèle étant volumineux, veuillez patienter 2 à 3 minutes avant d'actualiser la page.
Comment utiliser
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Informations sur la citation
Merci à l'utilisateur Github xxxjjjyyy1 Déploiement de ce tutoriel. Les informations de citation pour ce projet sont les suivantes :
@article{minicpm4,
title={MiniCPM4: Ultra-Efficient LLMs on End Devices},
author={MiniCPM Team},
year={2025}
}
@inproceedings{huminicpm,
title={MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies},
author={Hu, Shengding and Tu, Yuge and Han, Xu and Cui, Ganqu and He, Chaoqun and Zhao, Weilin and Long, Xiang and Zheng, Zhi and Fang, Yewei and Huang, Yuxiang and others},
booktitle={First Conference on Language Modeling},
year={2024}
}Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.