Command Palette
Search for a command to run...
Stable-audio-open-small : Démonstration Du Modèle De Génération Audio
Date
Taille
1.47 GB
Licence
MIT
URL du document
1. Introduction au tutoriel

Ce tutoriel utilise une ressource A6000 à carte unique. Les invites générées sont uniquement en anglais.
2. Exemples de projets
3. Étapes de l'opération
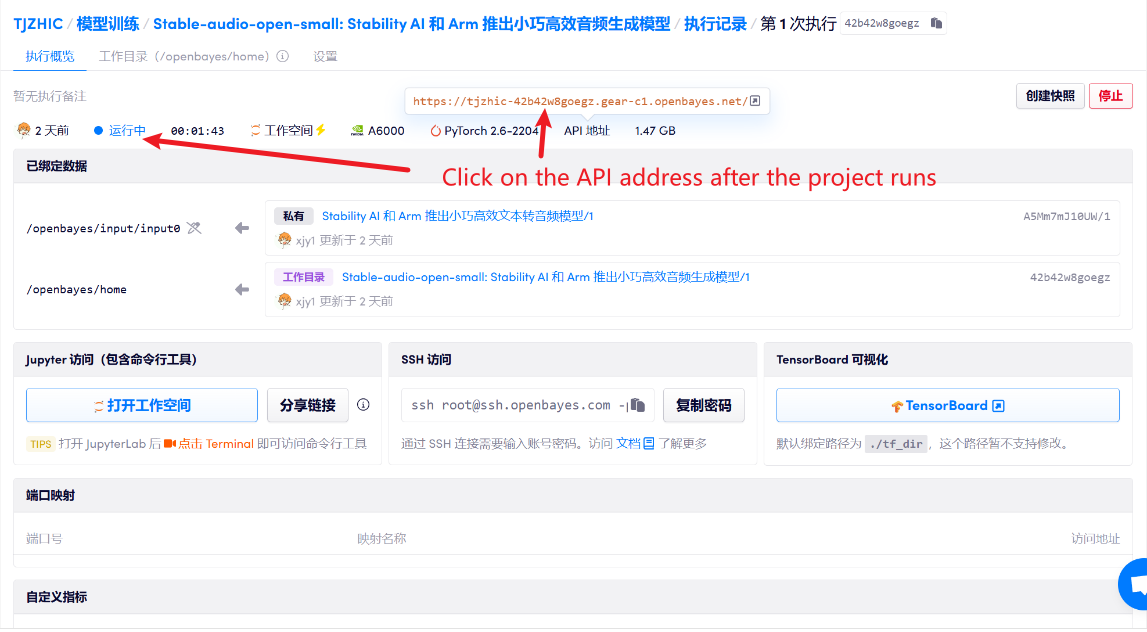
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 1 à 2 minutes et actualiser la page.
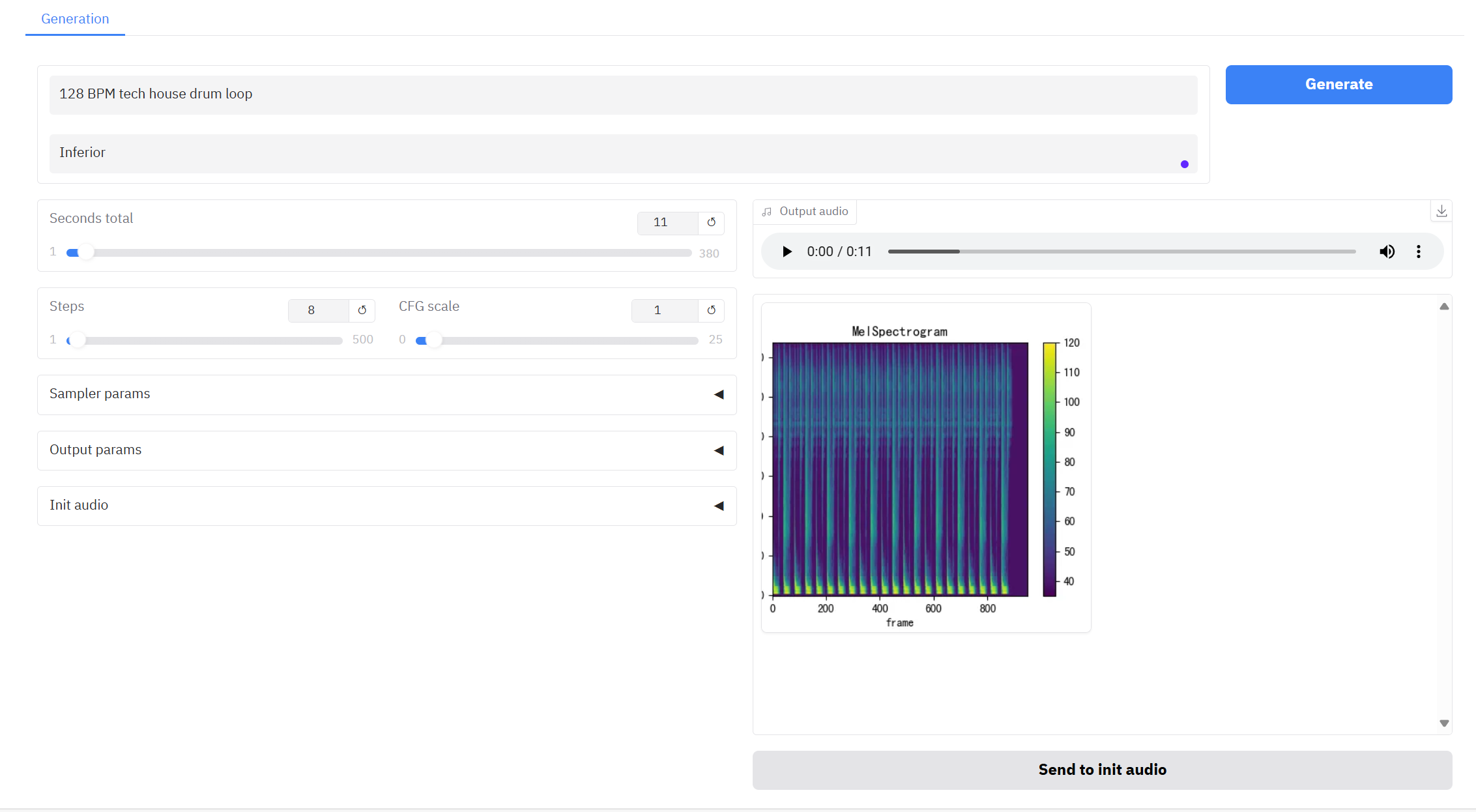
2. Après être entré sur la page Web, vous pouvez démarrer une conversation avec le modèle
Conseils : Des paramètres incorrects peuvent générer du bruit. Avec Safari, l'audio peut ne pas être lu directement et doit être téléchargé avant la lecture.
Comment utiliser
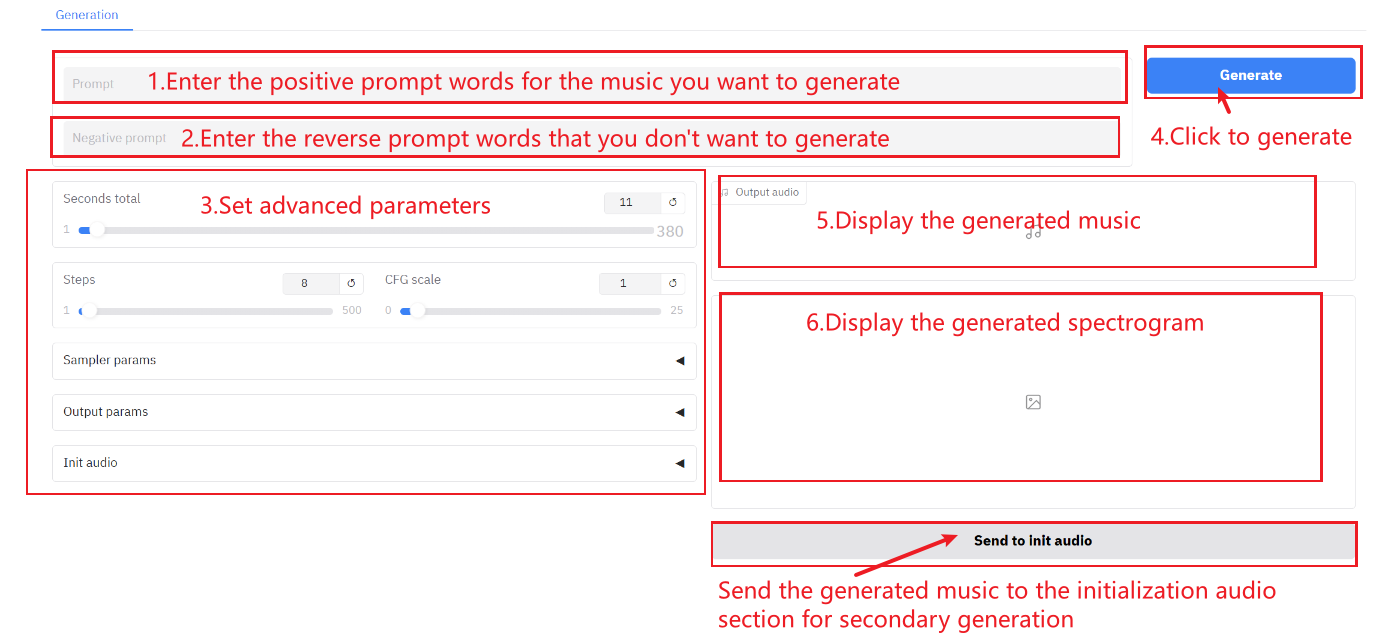
Description des paramètres :
- Secondes totales : La durée totale de l'audio généré.
- Mesures: Le nombre d'itérations ou d'étapes du processus d'inférence du modèle représente le nombre d'étapes d'optimisation nécessaires pour produire le résultat. Un nombre d'étapes plus élevé produit généralement des résultats plus précis, mais peut augmenter le temps de calcul.
- Échelle CFG : Il permet de contrôler l'influence des entrées conditionnelles sur les résultats générés dans le modèle génératif. Plus la valeur est élevée, plus elle est conforme à la description textuelle.
Paramètres de l'échantillonneur
- Graine: La graine aléatoire, qui reste constante, peut produire les mêmes résultats à plusieurs reprises.
- Intervalle CFG min : Définissez le guide conditionnel sur le point de départ temporel du processus de diffusion.
- Intervalle CFG max : Définissez le guide conditionnel au point final temporel du processus de diffusion.
- Montant de redimensionnement CFG : En ajustant dynamiquement la force de condition, le débordement numérique est évité et la stabilité de la génération sous une force de condition élevée est améliorée.
Paramètres de sortie
- Format de fichier : Sélectionnez le format du fichier de sortie.
- Nommage du fichier : Sélectionnez la méthode de dénomination du fichier de sortie.
- Aperçu des spécifications tous les : Sélectionnez si vous souhaitez prévisualiser le graphique du spectre.
- Passer au total des secondes : S'il faut couper à la durée spécifiée.
- Lecture automatique : S'il faut jouer automatiquement.
- Radio Infinie : S'il faut générer dans une boucle.
- Téléchargement automatique : Faut-il télécharger automatiquement ?
Init audio
- Init audio : Sélectionnez le fichier audio initial pour générer un nouvel audio.
- Niveau de bruit d'initialisation : Initialise le niveau de bruit, qui contrôle le caractère aléatoire initial de l'audio généré.
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.