Ce tutoriel utilise des ressources pour une seule carte RTX 4090.
👉 Ce projet fournit un modèle de :
MegaTTS 3 : un système TTS doté d'un algorithme innovant de « transformateur diffus latent » guidé à alignement clairsemé qui permet d'obtenir une qualité de parole TTS zéro coup de pointe et prend en charge un contrôle très flexible de la force de l'accent. Le timbre d'entrée peut être cloné et utilisé pour générer un contenu audio spécifique selon les besoins.
2. Étapes de l'opération
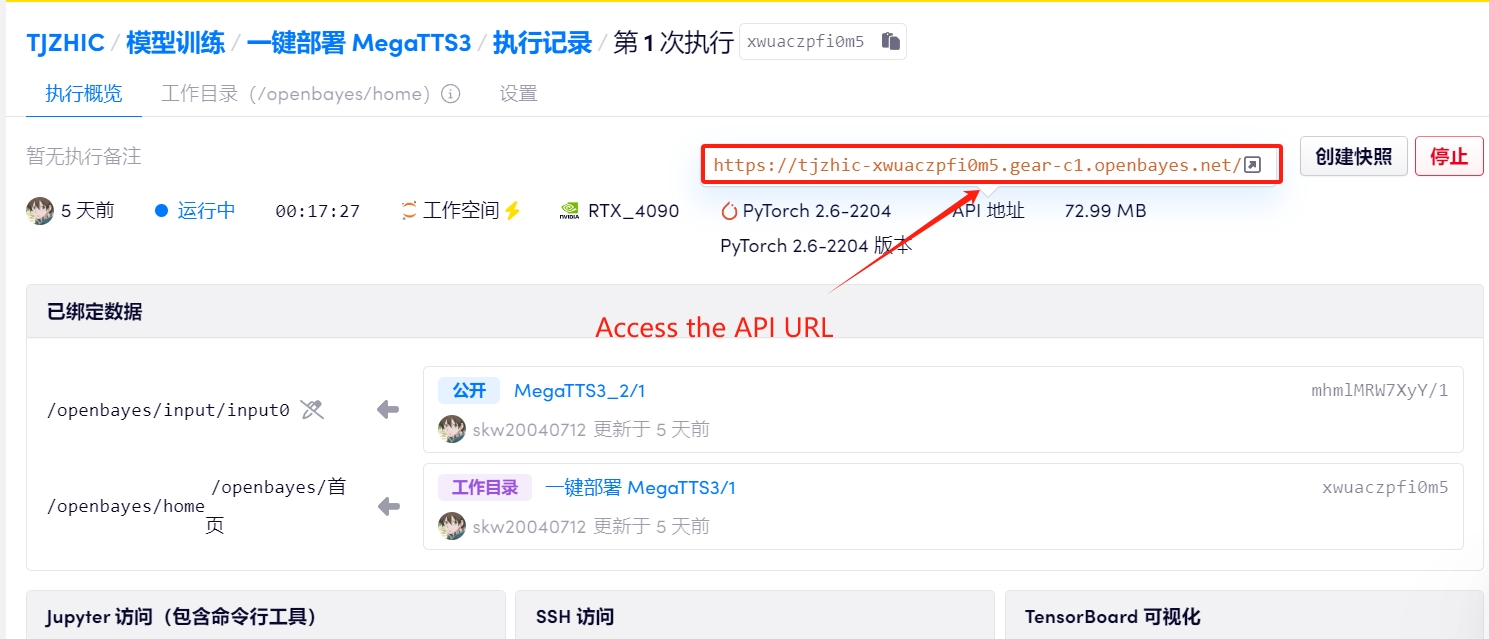
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 1 à 2 minutes et actualiser la page.
2. Une fois que vous entrez sur la page Web, vous pouvez utiliser MegaTTS 3
Comment utiliser
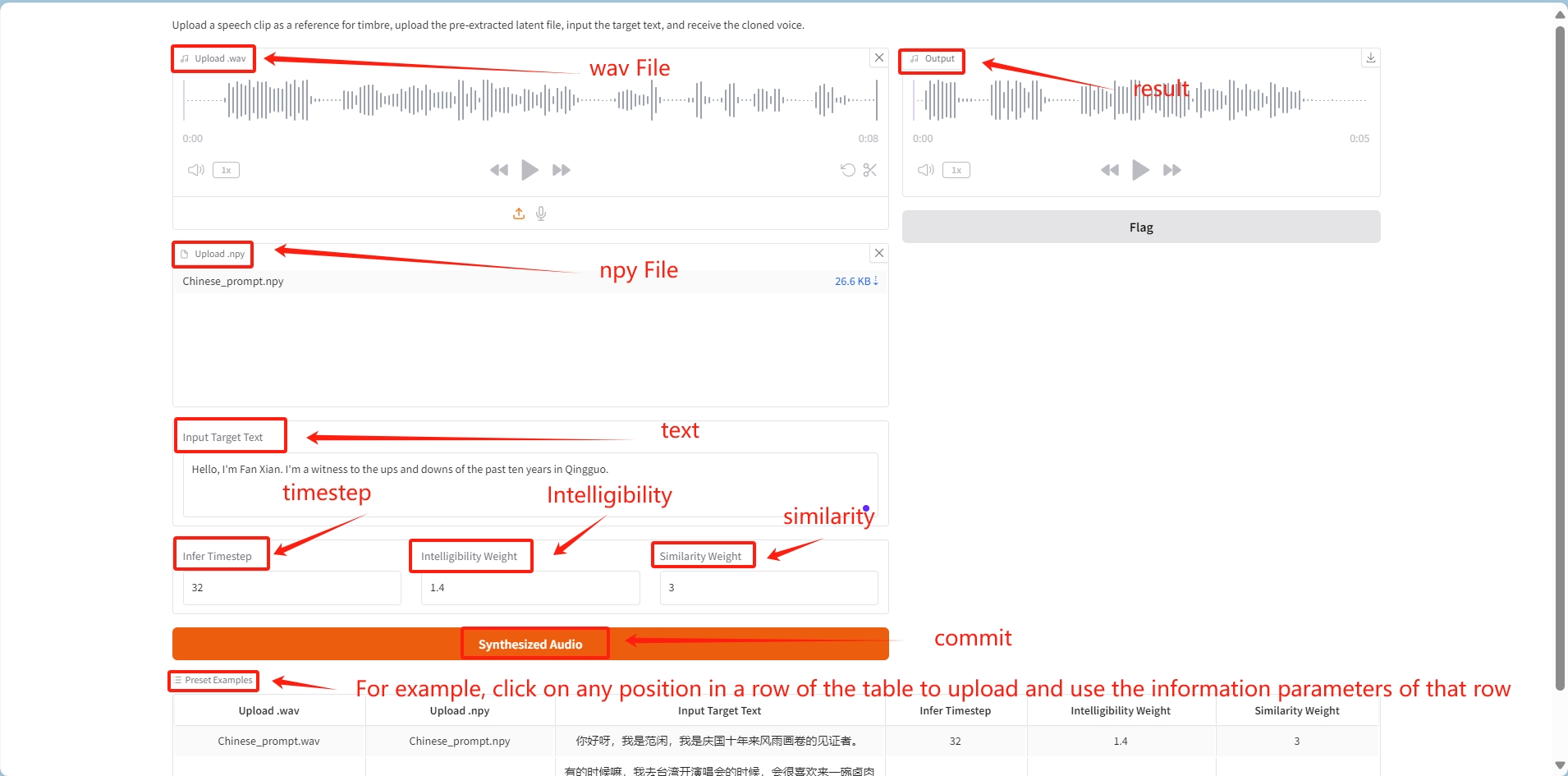
1. Téléchargez le fichier audio wav et le fichier npy généré correspondant séparément ;
2. Saisissez le texte spécifié dans input_text ;
③ Après la soumission, le timbre du fichier audio sera cloné pour générer l'audio correspondant au texte dans input_text.
❗️Description du paramètre :
déduire le pas de temps : Affecte le pas de temps auquel le modèle génère des sons, contrôlant généralement le nombre de pas de temps dans le processus de génération. Un pas de temps plus petit peut rendre le son plus fluide car le modèle dispose de plus de pas de temps pour affiner les caractéristiques sonores.
Poids d'intelligibilité : Ajuste la clarté et l'intelligibilité du son. Un poids plus élevé rend le son plus clair et convient aux scènes où les informations doivent être transmises avec précision, mais peuvent sacrifier un certain naturel.
Poids de similarité : Contrôle le degré de similitude du son généré avec le son d'origine. Un poids plus élevé rend le son plus proche du son d'origine et convient aux scénarios où la voix cible doit être reproduite fidèlement.
Obtenir un exemple de fichier
Accéder au site web https://drive.google.com/drive/folders/1QhcHWcy20JfqWjgqZX1YM3I6i9u4oNlr, il y a trois sous-dossiers (librispeech_testclean_40, official_test_case, user_batch_1-3) contenant tous les timbres actuellement disponibles. Après être entré dans le dossier, écoutez et téléchargez le fichier wav et le fichier npy.
Échange et discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓
Informations sur la citation
Merci à l'utilisateur Github kjasdk Pour la réalisation de ce tutoriel, les informations de référence du projet sont les suivantes :
@article{jiang2025sparse,
title={Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis},
author={Jiang, Ziyue and Ren, Yi and Li, Ruiqi and Ji, Shengpeng and Ye, Zhenhui and Zhang, Chen and Jionghao, Bai and Yang, Xiaoda and Zuo, Jialong and Zhang, Yu and others},
journal={arXiv preprint arXiv:2502.18924},
year={2025}
}
@article{ji2024wavtokenizer,
title={Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling},
author={Ji, Shengpeng and Jiang, Ziyue and Wang, Wen and Chen, Yifu and Fang, Minghui and Zuo, Jialong and Yang, Qian and Cheng, Xize and Wang, Zehan and Li, Ruiqi and others},
journal={arXiv preprint arXiv:2408.16532},
year={2024}
}
Ce notebook est fourni par des utilisateurs de la communauté et est destiné à des fins éducatives et informatives uniquement. Si un contenu enfreint des droits d'auteur, veuillez nous contacter à [email protected] pour un examen et un retrait rapides.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.
Ce tutoriel utilise des ressources pour une seule carte RTX 4090.
👉 Ce projet fournit un modèle de :
MegaTTS 3 : un système TTS doté d'un algorithme innovant de « transformateur diffus latent » guidé à alignement clairsemé qui permet d'obtenir une qualité de parole TTS zéro coup de pointe et prend en charge un contrôle très flexible de la force de l'accent. Le timbre d'entrée peut être cloné et utilisé pour générer un contenu audio spécifique selon les besoins.
2. Étapes de l'opération
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 1 à 2 minutes et actualiser la page.
2. Une fois que vous entrez sur la page Web, vous pouvez utiliser MegaTTS 3
Comment utiliser
1. Téléchargez le fichier audio wav et le fichier npy généré correspondant séparément ;
2. Saisissez le texte spécifié dans input_text ;
③ Après la soumission, le timbre du fichier audio sera cloné pour générer l'audio correspondant au texte dans input_text.
❗️Description du paramètre :
déduire le pas de temps : Affecte le pas de temps auquel le modèle génère des sons, contrôlant généralement le nombre de pas de temps dans le processus de génération. Un pas de temps plus petit peut rendre le son plus fluide car le modèle dispose de plus de pas de temps pour affiner les caractéristiques sonores.
Poids d'intelligibilité : Ajuste la clarté et l'intelligibilité du son. Un poids plus élevé rend le son plus clair et convient aux scènes où les informations doivent être transmises avec précision, mais peuvent sacrifier un certain naturel.
Poids de similarité : Contrôle le degré de similitude du son généré avec le son d'origine. Un poids plus élevé rend le son plus proche du son d'origine et convient aux scénarios où la voix cible doit être reproduite fidèlement.
Obtenir un exemple de fichier
Accéder au site web https://drive.google.com/drive/folders/1QhcHWcy20JfqWjgqZX1YM3I6i9u4oNlr, il y a trois sous-dossiers (librispeech_testclean_40, official_test_case, user_batch_1-3) contenant tous les timbres actuellement disponibles. Après être entré dans le dossier, écoutez et téléchargez le fichier wav et le fichier npy.
Échange et discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓
Informations sur la citation
Merci à l'utilisateur Github kjasdk Pour la réalisation de ce tutoriel, les informations de référence du projet sont les suivantes :
@article{jiang2025sparse,
title={Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis},
author={Jiang, Ziyue and Ren, Yi and Li, Ruiqi and Ji, Shengpeng and Ye, Zhenhui and Zhang, Chen and Jionghao, Bai and Yang, Xiaoda and Zuo, Jialong and Zhang, Yu and others},
journal={arXiv preprint arXiv:2502.18924},
year={2025}
}
@article{ji2024wavtokenizer,
title={Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling},
author={Ji, Shengpeng and Jiang, Ziyue and Wang, Wen and Chen, Yifu and Fang, Minghui and Zuo, Jialong and Yang, Qian and Cheng, Xize and Wang, Zehan and Li, Ruiqi and others},
journal={arXiv preprint arXiv:2408.16532},
year={2024}
}
Ce notebook est fourni par des utilisateurs de la communauté et est destiné à des fins éducatives et informatives uniquement. Si un contenu enfreint des droits d'auteur, veuillez nous contacter à [email protected] pour un examen et un retrait rapides.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.