Qwen3 est la dernière génération de grands modèles de langage de la série Qwen, fournissant des modèles denses complets et des modèles de mélange d'experts (MoE). S'appuyant sur une riche expérience de formation, Qwen3 a réalisé des progrès révolutionnaires en matière de raisonnement, de suivi des instructions, de capacités d'agent et de support multilingue. Les scénarios d’application de Qwen3 sont très larges. Il prend en charge le traitement de texte, d'image, d'audio et de vidéo et peut répondre aux besoins de création de contenu multimodal et de tâches intermodales. Dans les applications de niveau entreprise, les capacités d'agent et la prise en charge multilingue de Qwen3 lui permettent de gérer des tâches complexes telles que le diagnostic médical, l'analyse de documents juridiques et l'automatisation du service client. De plus, les petits modèles tels que Qwen3-0.6B conviennent au déploiement sur des appareils finaux tels que les téléphones mobiles, élargissant encore ses scénarios d'application.
La dernière version Qwen3 présente les fonctionnalités suivantes :
Modèles experts denses et mixtes pleine grandeur : 0,6B, 1,7B, 4B, 8B, 14B, 32B et 30B-A3B, 235B-A22B
Prend en charge la commutation transparente entre le mode de réflexion (pour le raisonnement logique complexe, les mathématiques et le codage) et le mode de non-réflexion (pour des conversations générales efficaces), garantissant des performances optimales dans divers scénarios.
Capacités de raisonnement considérablement améliorées, surpassant le modèle d'instruction QwQ précédent (en mode réflexion) et Qwen2.5 (en mode non réflexion) en mathématiques, génération de code et raisonnement logique de bon sens.
Alignement supérieur avec les préférences humaines, excelle dans l'écriture créative, les jeux de rôle, les conversations à plusieurs tours et le suivi des commandes, offrant une expérience de conversation plus naturelle, engageante et immersive.
Excelle dans les capacités d'agent intelligent, peut intégrer avec précision des outils externes dans les modes de réflexion et de non-réflexion, et est leader dans les modèles open source dans les tâches complexes basées sur des agents.
Il prend en charge plus de 100 langues et dialectes et dispose de puissantes capacités de compréhension multilingue, de raisonnement, de suivi de commandes et de génération.
2. Étapes de l'opération
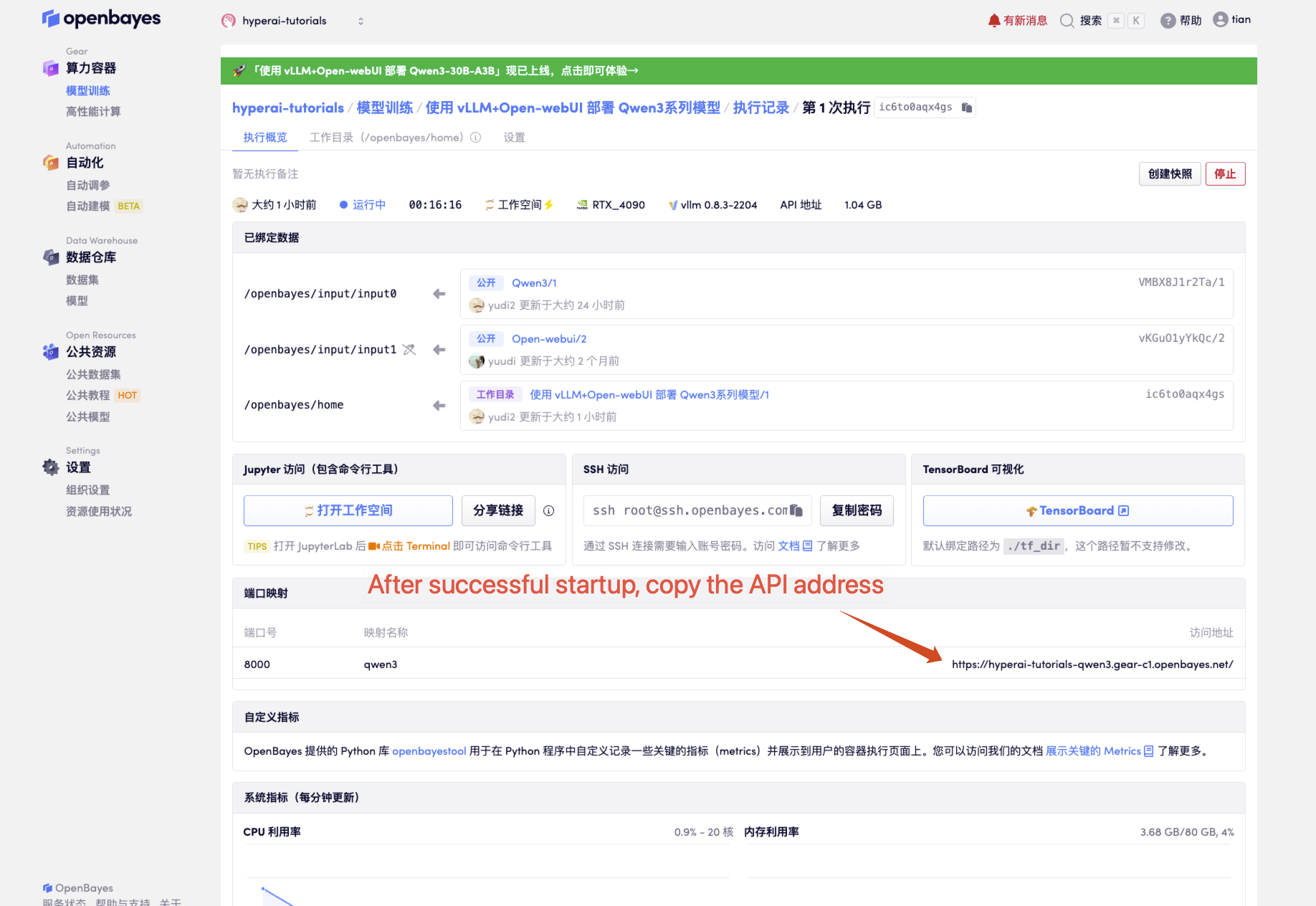
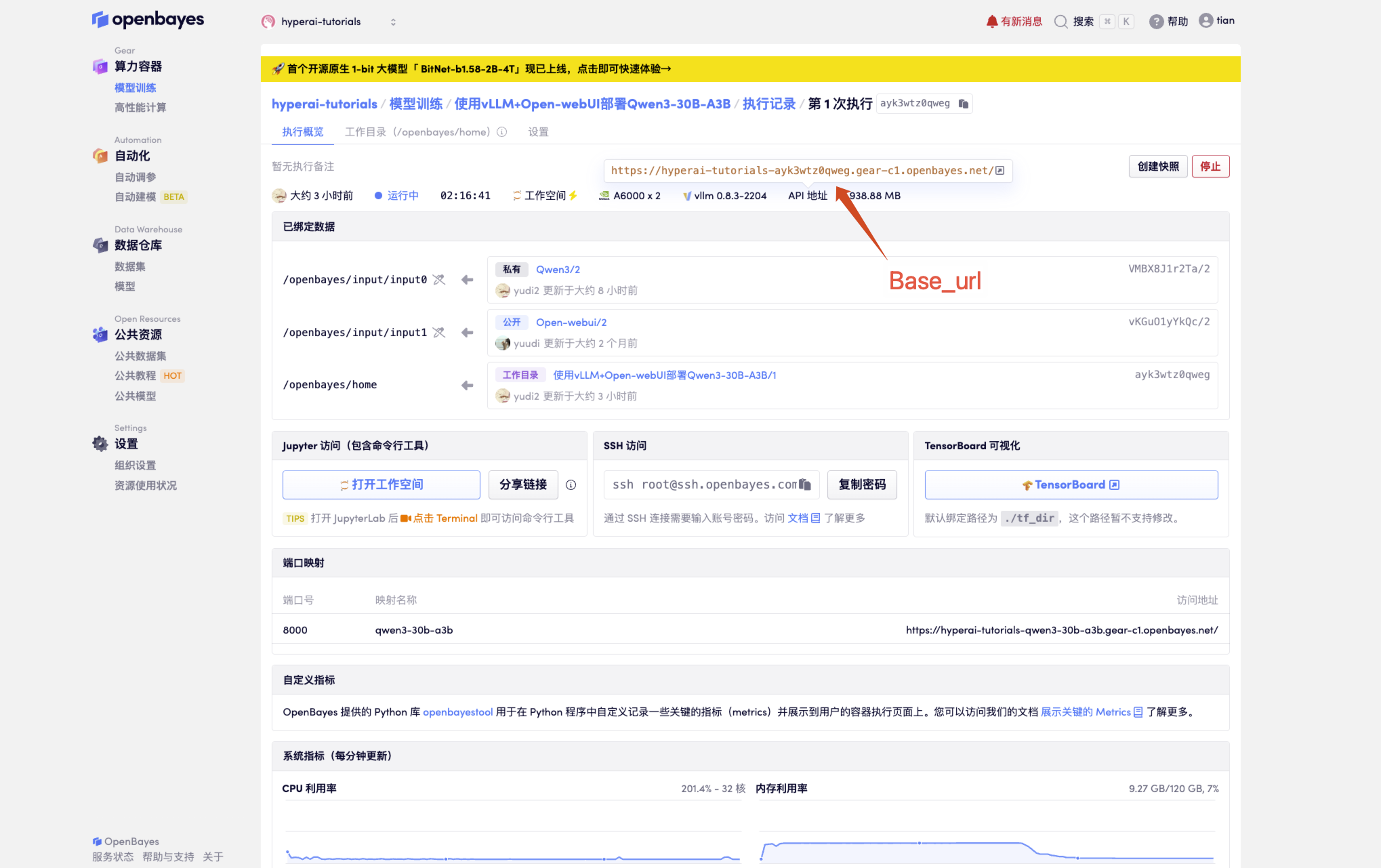
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
Si « Modèle » n'est pas affiché, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 1 à 2 minutes et actualiser la page.
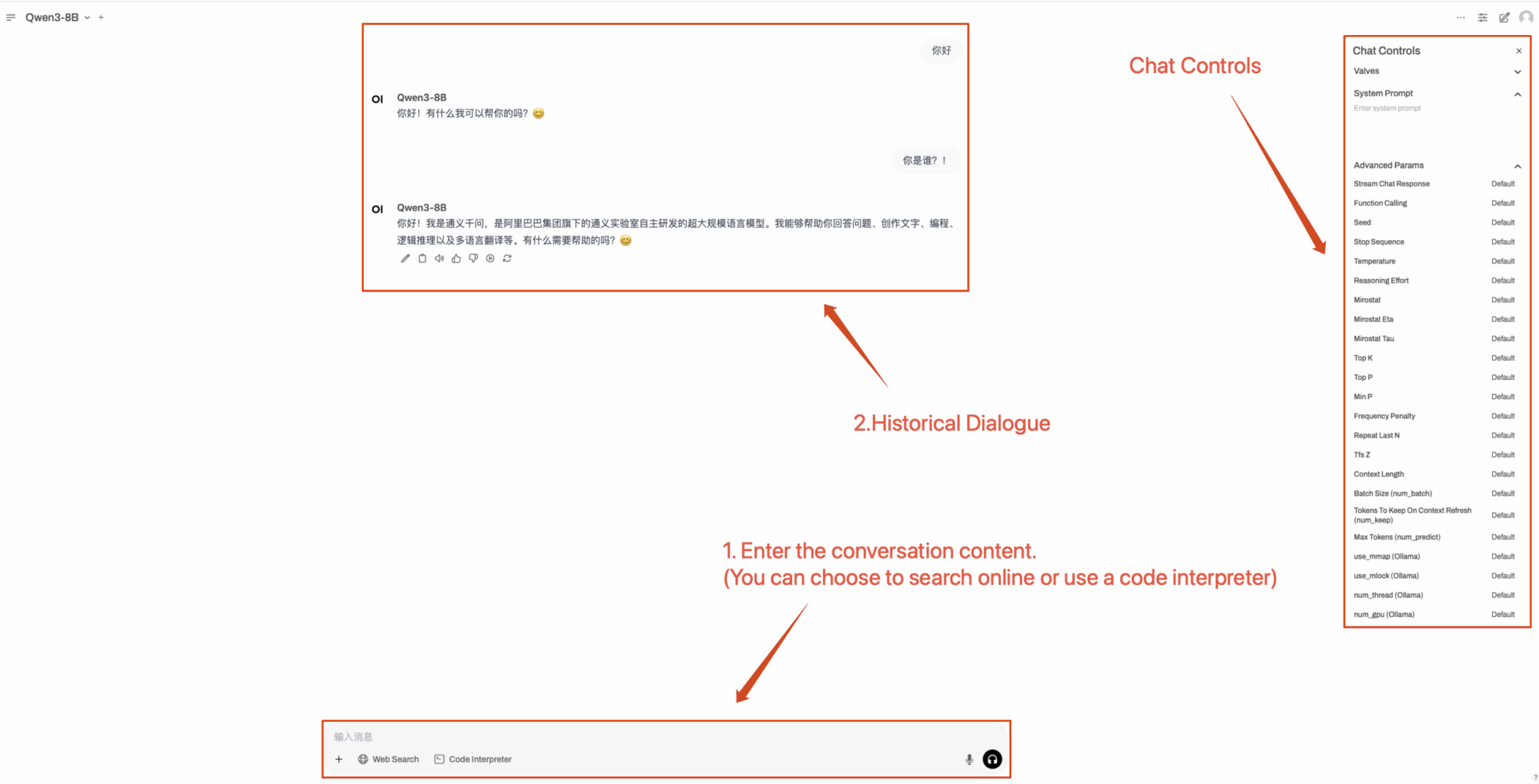
2. Après être entré sur la page Web, vous pouvez démarrer une conversation avec le modèle
Comment utiliser
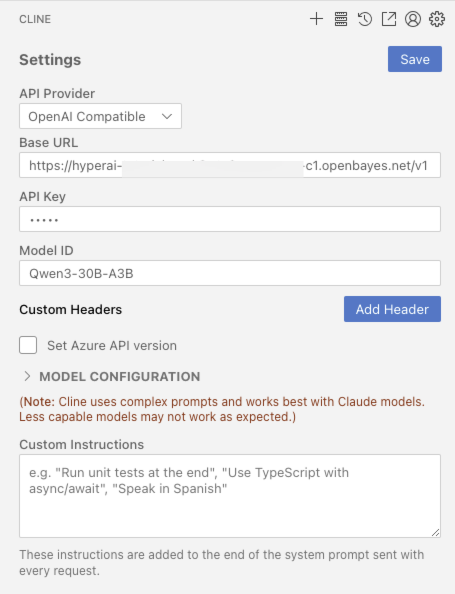
3. Guide d'appel d'API OpenAI
Ce qui suit est une description optimisée de la méthode d'appel d'API, avec une structure plus claire et des détails pratiques ajoutés :
/input0/Qwen3-4B → Remplacez par le chemin de votre modèle cible (par exemple Qwen3-1.7B).
--served-model-name → Changer pour le nom du modèle correspondant (par exemple Qwen3-1.7B).
Une fois terminé, votre nouveau modèle est prêt à être utilisé ! 🚀
Échange et discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓
Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
Ce notebook est fourni par des utilisateurs de la communauté et est destiné à des fins éducatives et informatives uniquement. Si un contenu enfreint des droits d'auteur, veuillez nous contacter à [email protected] pour un examen et un retrait rapides.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.
Qwen3 est la dernière génération de grands modèles de langage de la série Qwen, fournissant des modèles denses complets et des modèles de mélange d'experts (MoE). S'appuyant sur une riche expérience de formation, Qwen3 a réalisé des progrès révolutionnaires en matière de raisonnement, de suivi des instructions, de capacités d'agent et de support multilingue. Les scénarios d’application de Qwen3 sont très larges. Il prend en charge le traitement de texte, d'image, d'audio et de vidéo et peut répondre aux besoins de création de contenu multimodal et de tâches intermodales. Dans les applications de niveau entreprise, les capacités d'agent et la prise en charge multilingue de Qwen3 lui permettent de gérer des tâches complexes telles que le diagnostic médical, l'analyse de documents juridiques et l'automatisation du service client. De plus, les petits modèles tels que Qwen3-0.6B conviennent au déploiement sur des appareils finaux tels que les téléphones mobiles, élargissant encore ses scénarios d'application.
La dernière version Qwen3 présente les fonctionnalités suivantes :
Modèles experts denses et mixtes pleine grandeur : 0,6B, 1,7B, 4B, 8B, 14B, 32B et 30B-A3B, 235B-A22B
Prend en charge la commutation transparente entre le mode de réflexion (pour le raisonnement logique complexe, les mathématiques et le codage) et le mode de non-réflexion (pour des conversations générales efficaces), garantissant des performances optimales dans divers scénarios.
Capacités de raisonnement considérablement améliorées, surpassant le modèle d'instruction QwQ précédent (en mode réflexion) et Qwen2.5 (en mode non réflexion) en mathématiques, génération de code et raisonnement logique de bon sens.
Alignement supérieur avec les préférences humaines, excelle dans l'écriture créative, les jeux de rôle, les conversations à plusieurs tours et le suivi des commandes, offrant une expérience de conversation plus naturelle, engageante et immersive.
Excelle dans les capacités d'agent intelligent, peut intégrer avec précision des outils externes dans les modes de réflexion et de non-réflexion, et est leader dans les modèles open source dans les tâches complexes basées sur des agents.
Il prend en charge plus de 100 langues et dialectes et dispose de puissantes capacités de compréhension multilingue, de raisonnement, de suivi de commandes et de génération.
2. Étapes de l'opération
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
Si « Modèle » n'est pas affiché, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 1 à 2 minutes et actualiser la page.
2. Après être entré sur la page Web, vous pouvez démarrer une conversation avec le modèle
Comment utiliser
3. Guide d'appel d'API OpenAI
Ce qui suit est une description optimisée de la méthode d'appel d'API, avec une structure plus claire et des détails pratiques ajoutés :
/input0/Qwen3-4B → Remplacez par le chemin de votre modèle cible (par exemple Qwen3-1.7B).
--served-model-name → Changer pour le nom du modèle correspondant (par exemple Qwen3-1.7B).
Une fois terminé, votre nouveau modèle est prêt à être utilisé ! 🚀
Échange et discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓
Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
Ce notebook est fourni par des utilisateurs de la communauté et est destiné à des fins éducatives et informatives uniquement. Si un contenu enfreint des droits d'auteur, veuillez nous contacter à [email protected] pour un examen et un retrait rapides.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.