Command Palette
Search for a command to run...
Déployer QwQ-32B À l'aide De vLLM
Date
Taille
143.31 MB

1. Introduction au tutoriel
QwQ est le modèle de raisonnement de la série Qwen. Comparé aux modèles de réglage d'instructions traditionnels, QwQ dispose de capacités de réflexion et de raisonnement et peut réaliser des améliorations de performances significatives dans les tâches en aval, en particulier les problèmes difficiles. QwQ-32B est un modèle d'inférence de taille moyenne qui peut atteindre des performances compétitives avec des modèles d'inférence de pointe tels que DeepSeek-R1 et o1-mini.
Ce tutoriel utilise QwQ-32B comme démonstration et les ressources de calcul sont A6000*2.
2. Étapes de l'opération
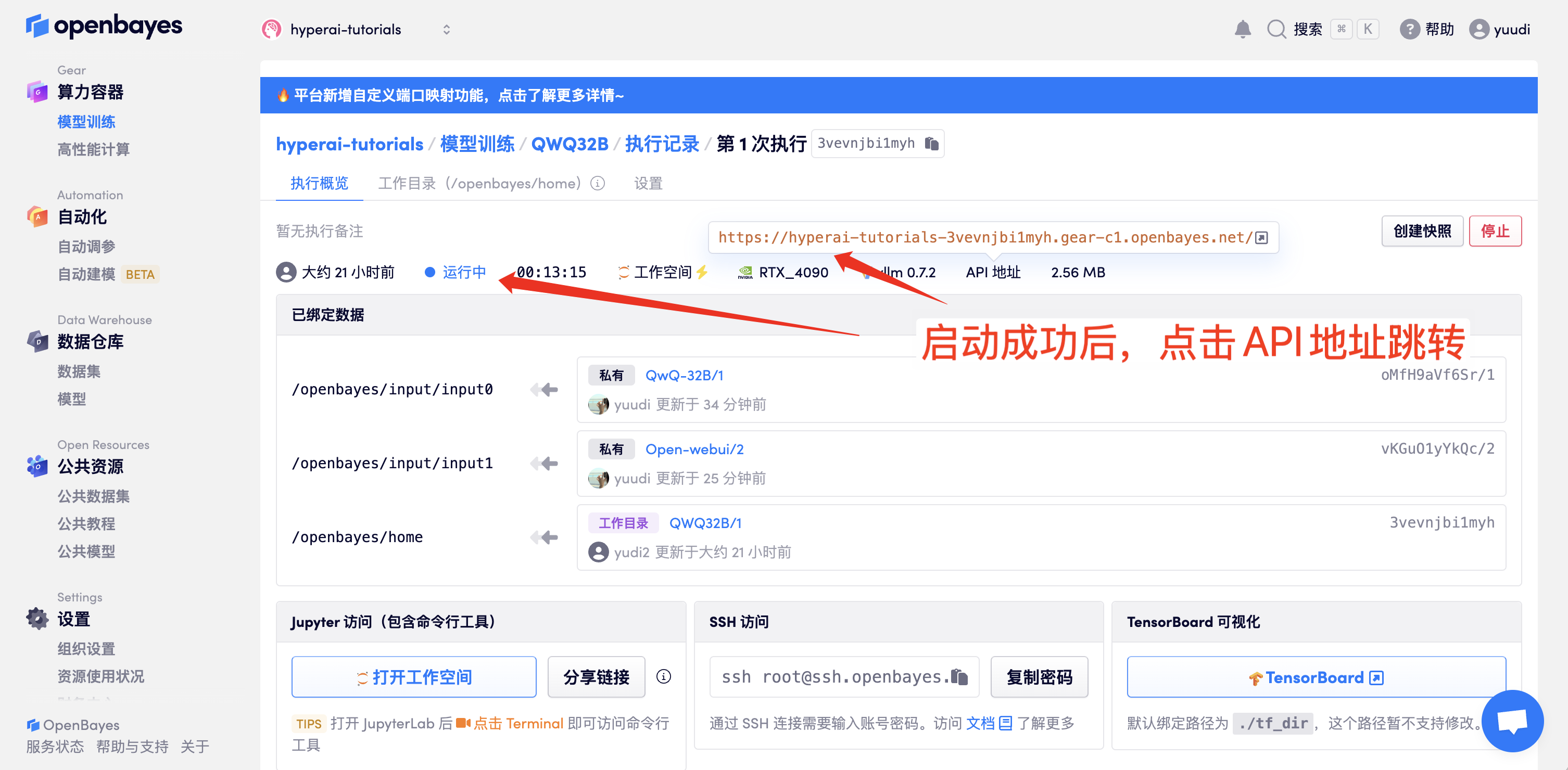
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web. (Si « Modèle » n'est pas affiché, cela signifie que le modèle est en cours d'initialisation. Le modèle étant volumineux, veuillez patienter 1 à 2 minutes et actualiser la page.)
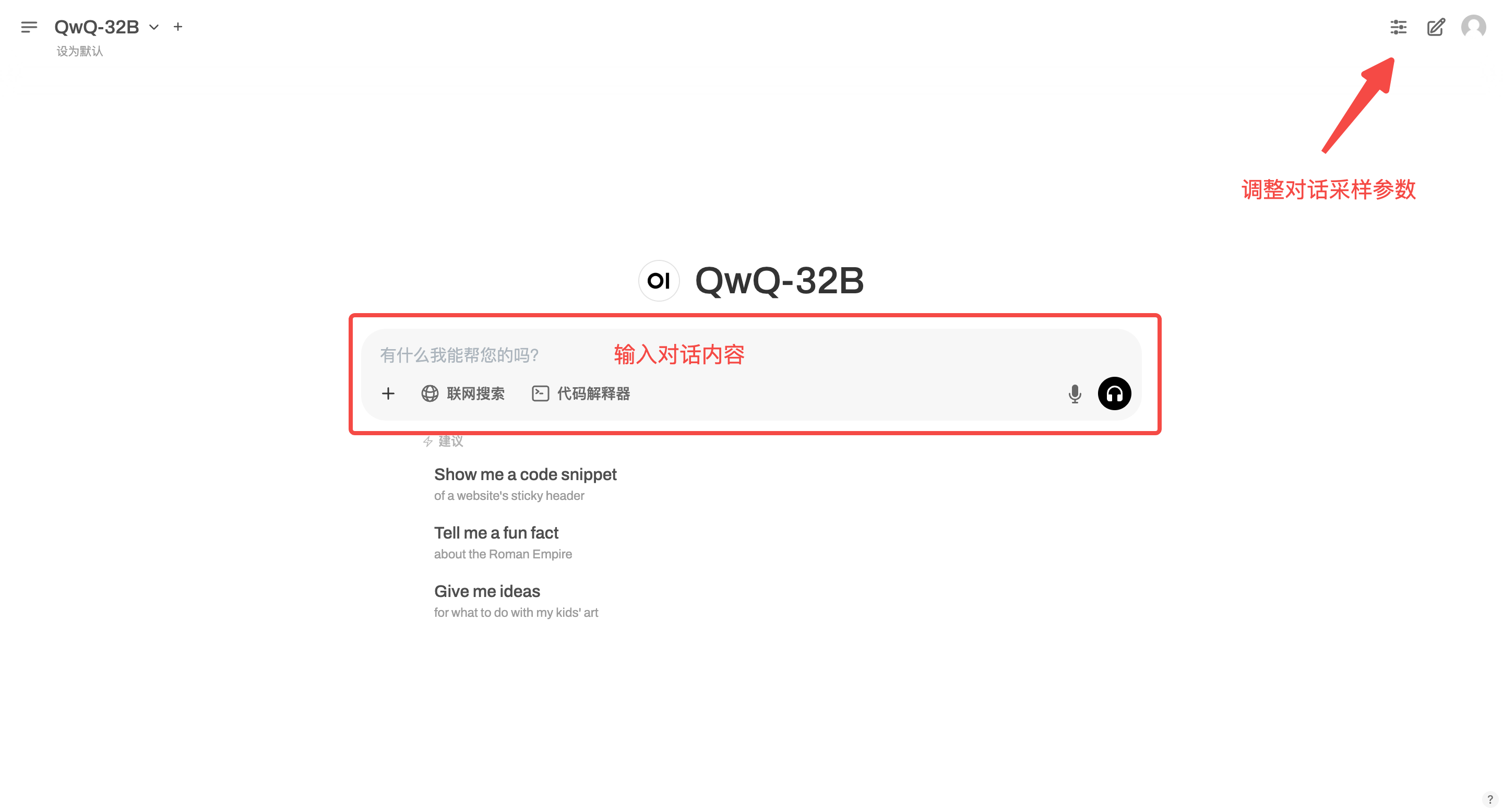
2. Après être entré sur la page Web, vous pouvez démarrer une conversation avec le modèle
Ce tutoriel prend en charge la « recherche en ligne ». Une fois cette fonction activée, la vitesse d'inférence ralentira, ce qui est normal.
Échange et discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓ 
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.