Command Palette
Search for a command to run...
Déploiement En Un Clic De DeepSeek-R1-70B
Date
Taille
890.53 MB
Balises
Licence
MIT
GitHub
URL du document
1. Introduction au tutoriel

DeepSeek-R1-Distill-Llama-70B est un modèle de langage open source de grande taille, publié par DeepSeek en 2025, avec 70 milliards de paramètres. Entraîné sur Llama3.3-70B-Instruct, il utilise l'apprentissage par renforcement et des techniques de distillation pour améliorer les performances d'inférence. Il hérite des avantages des modèles de la série Llama tout en optimisant davantage les capacités d'inférence, excellant particulièrement dans les tâches de raisonnement mathématique, de programmation et logique. Version haute performance de la série DeepSeek, il obtient d'excellents résultats dans de nombreux tests de référence. De plus, ce modèle, optimisé pour l'inférence par DeepSeek AI, prend en charge divers scénarios d'application tels que les appareils mobiles, l'informatique de périphérie et les services d'inférence en ligne, afin d'améliorer la vitesse de réponse et de réduire les coûts d'exploitation. Il possède de puissantes capacités d'inférence et de prise de décision. Dans des domaines tels que les assistants IA avancés et l'analyse de la recherche scientifique, il peut fournir des résultats analytiques extrêmement professionnels et approfondis. Par exemple, dans la recherche médicale, la version 70B peut analyser de grandes quantités de données médicales, fournissant ainsi des références précieuses pour la recherche sur les maladies.
本教程使用 Ollama + Open WebUI 部署 DeepSeek-R1-Distill-Qwen-70B 作为演示,算力资源采用「单卡 A6000」。
2. Étapes de l'opération
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web (si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est volumineux, veuillez patienter environ 5 minutes et réessayer.) 2. Après avoir accédé à la page Web, vous pouvez démarrer une conversation avec le modèle !
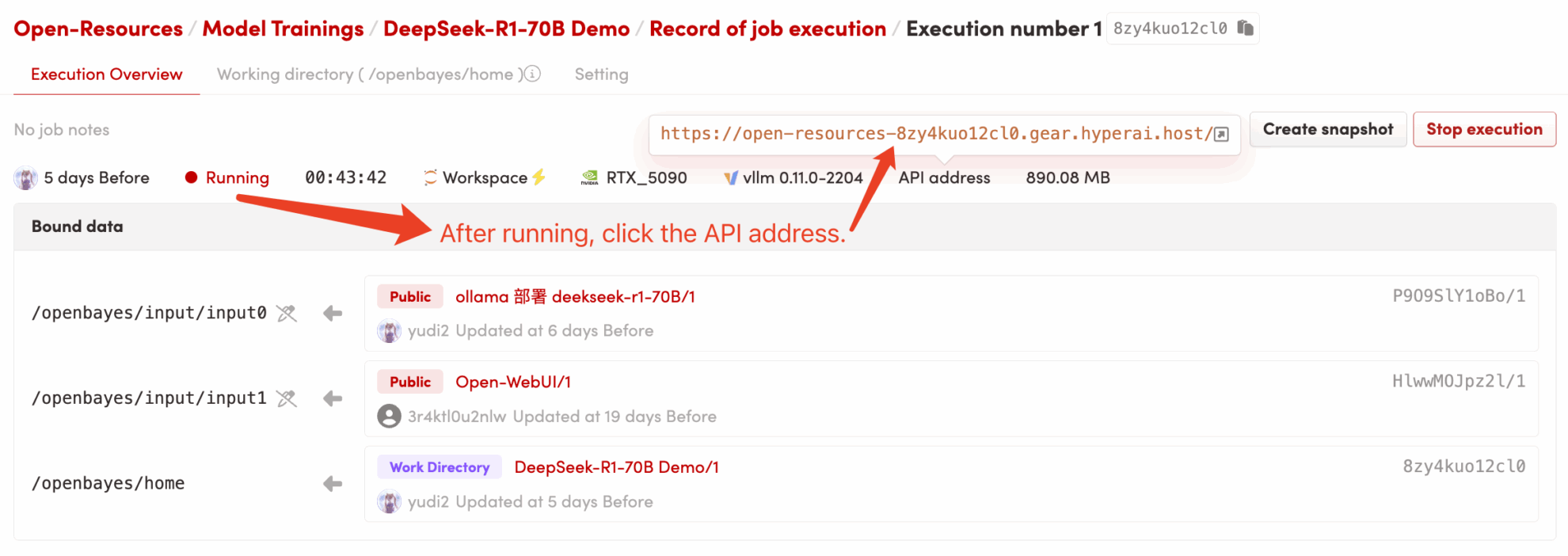
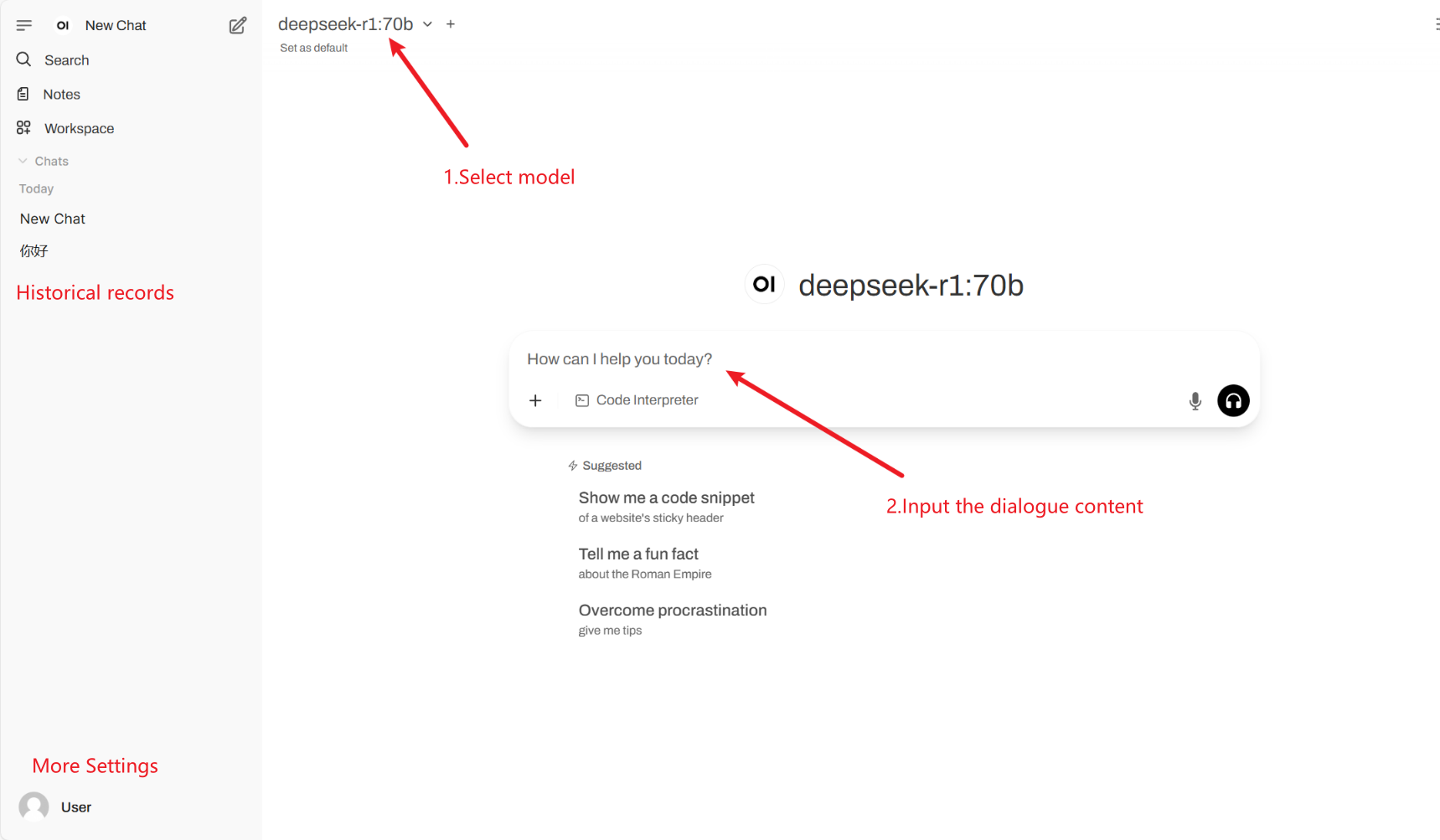
2. Après être entré sur la page Web, vous pouvez démarrer une conversation avec le modèle
Paramètres de conversation courants
1. Température
- Contrôle le caractère aléatoire de la sortie, généralement dans la plage de 0,0 à 2,0.
- Valeur faible (par exemple 0,1):Plus certain, biaisé vers les mots courants.
- Valeur élevée (par exemple 1,5):Contenu plus aléatoire, potentiellement plus créatif mais erratique.
2. Échantillonnage Top-k
- Ne sélectionner que les k mots ayant la plus forte probabilité, en excluant les mots à faible probabilité.
- k est petit (par exemple 10):Plus de certitude, moins d’aléatoire.
- k est grand (par exemple 50):Plus de diversité, plus d'innovation.
3. Échantillonnage Top-p (échantillonnage du noyau, échantillonnage Top-p)
- Sélectionnez l'ensemble de mots dont la probabilité cumulée atteint p et ne fixez pas la valeur de k.
- Valeur faible (par exemple 0,3):Plus de certitude, moins d’aléatoire.
- Valeur élevée (par exemple 0,9):Plus de diversité, une meilleure fluidité.
4. Pénalité de répétition
- Contrôle le taux de répétition du texte, généralement compris entre 1,0 et 2,0.
- Valeur élevée (par exemple 1,5):Réduisez les répétitions et améliorez la lisibilité.
- Valeur faible (par exemple 1,0): Aucune pénalité, peut amener le modèle à répéter des mots et des phrases.
5. Max Tokens (durée de génération maximale)
- Limitez le nombre maximal de jetons générés par le modèle pour éviter une sortie trop longue.
- Plage typique : 50-4096 (selon le modèle spécifique).
Citation
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
author={DeepSeek-AI},
year={2025},
eprint={2501.12948},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.12948},
}Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.